이전 포스트에서 나온 objective의 그래디언트의 추정은 다음과 같다:
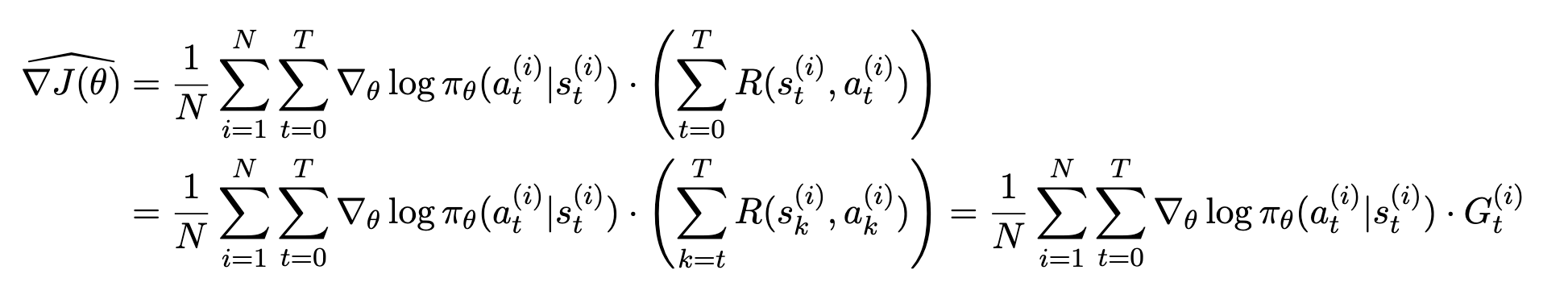
이 수식의 $G_t$ term에 $s_t$에 dependent한 함수 $b(s_t)$를 빼준다면

와 같은 형태가 될 것이다. 여기서 두 번째 항의 평균을 구해보자.
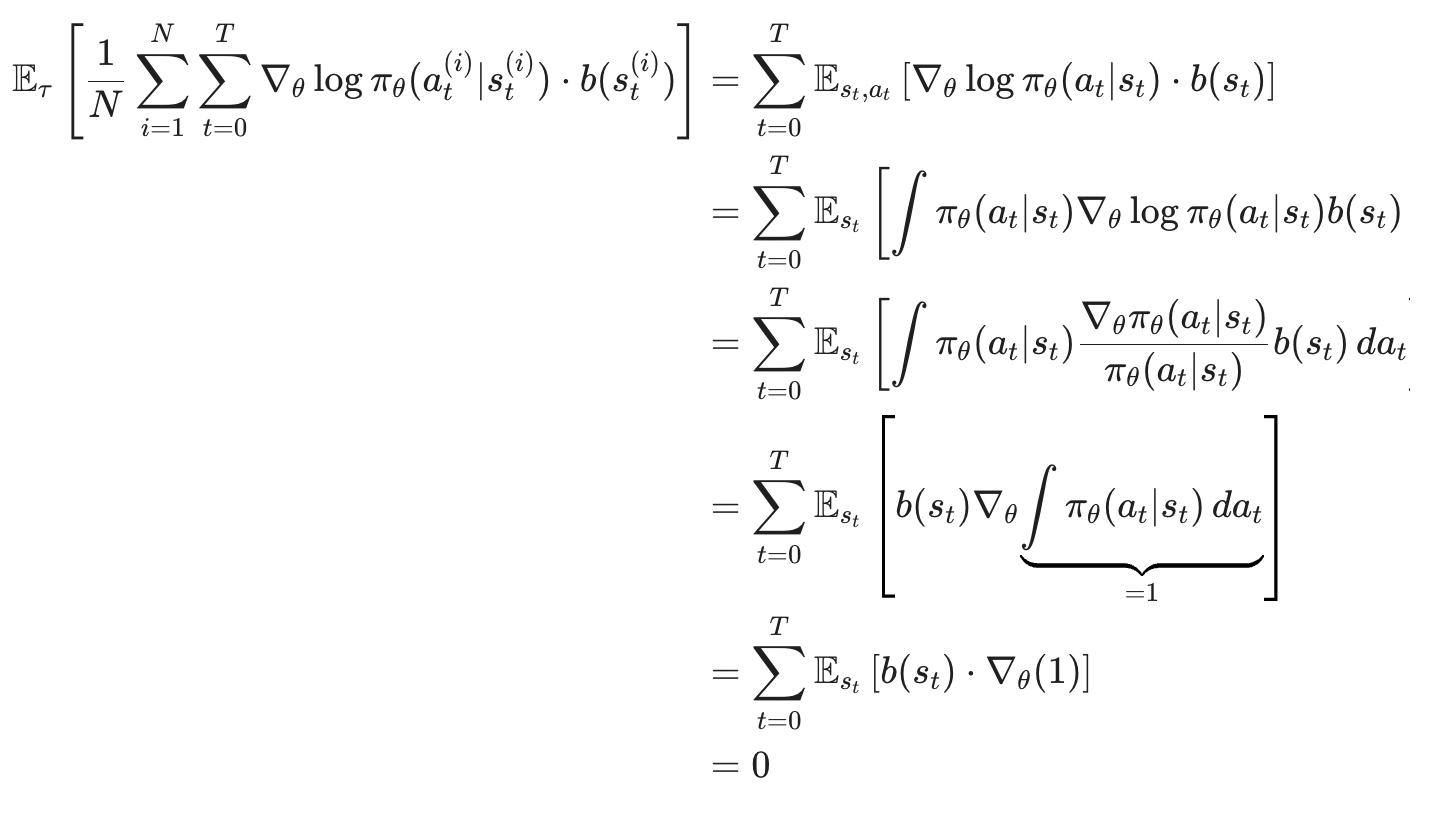
평균이 0이 되는 것을 확인할 수 있고, 이 말은 즉 어떤 좋은 baseline을 빼줌으로써 unbiasedness를 깨뜨리지 않고 variance를 낮출 수 있다는 것을 알 수 있다. 그렇다면 이제 자연스러운 의문은, 그러한 baseline은 어떤 것으로 선택해야 되어야 하는가에 관한 것이다.
이러한 baseline 선택에 관한 내용을 다루기 전에 앞서서, 원래의 objective gradient를 다시 한 번 recap해보자.
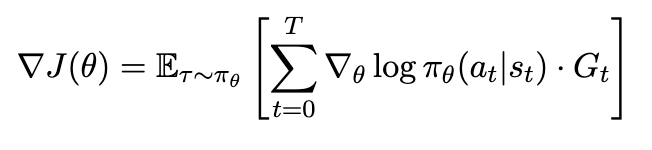
이를 trajectory에 대한 평균이 아닌, state, action pair에 대한 평균으로 나타내면
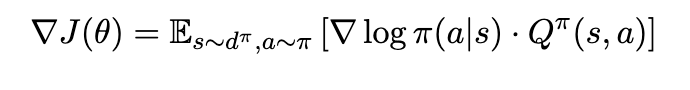
가 됨을 알 수 있다. 여기서 $d^\pi$는 policy $\pi$를 따를 때 state에 대한 distribution이다. 여기서 만약 baseline을 어떤 것으로 선택하는가에 관한 내용에서, 만약 baseline을 $V^{\pi}(s)$로 둔다면 자연스럽게 $Q^{\pi}(s,a)-V^{\pi}(s)$는 현재 따르는 policy를 바탕으로, 주어진 state에 대해서 어떠한 행동을 하는 것이 얼마나 유리한지에 관한 내용이 나오게 된다.
앞서 확인한 바와 같이 $G_t$ term에 $s_t$에 dependent한 함수 $b(s_t)$를 빼주더라도 평균이 달라지지 않기 때문에 베이스라인으로 state-value function을 쓰는 것은 unbiasedness를 깨지 않으며 따로 여기서 증명하지는 않겠지만 Monte Carlo estimate의 분산을 최소에 가깝게 낮추어줄 수 있다. 여기서 A2C의 이름이 나오는 것이며, $Q^{\pi}(s,a)-V^{\pi}(s)$는 advantage $A(s_t,a_t)$가 되는 것이다.
그렇다면 이 value function은 approximation을 통해 구해야 할 것이다. 한편 최종 reward sum을 Monte Carlo로 구하는 것은 분산이 여전히 크기 때문에, unbiasedness를 살짝 포기하면서 variance를 낮추는 TD 방법을 사용하여 해결할 수 있다. 즉
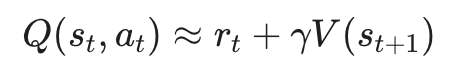
을 사용하여 advantage를 구할 수 있게 되는 것이다. Value network는 TD error의 MSE loss를 최소화하는 방향으로 학습할 수 있다.
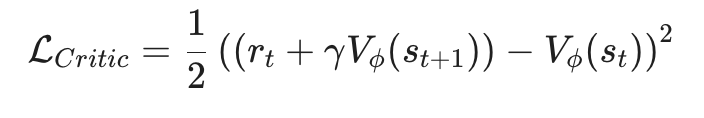
아직까지는 on-policy에 대한 policy gradient 방법인데, 이를 off-policy에서도 사용하기 위해 어떠한 방법을 사용하는지 다음 포스트에서 알아보도록 하자.
'Study > Reinforcement Learning' 카테고리의 다른 글
| Policy Gradient 4: TRPO & PPO (0) | 2025.11.22 |
|---|---|
| Policy Gradient 3: Off-Policy (0) | 2025.11.22 |
| Policy Gradient 1 - REINFORCE (0) | 2025.11.21 |
| Dynamic Programming 3 (0) | 2025.11.10 |
| Dynamic Programming 2 (0) | 2025.11.10 |