이전 포스트에서 확인한 IS를 통한 off-poilcy objective의 그래디언트는 다음과 같다:
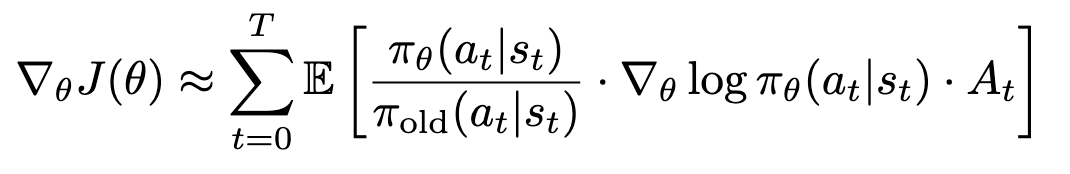
그러나 gradient 업데이트를 그대로 적용할 수 없고, 적절한 step size를 통해서 점진적으로 업데이트해야만 발산하는 경우와 bad local optima에 빠지는 것을 막을 수 있다. 사실 이러한 이야기는 일반적인 supervised learning에도 적용되는 말이고, 너무나도 당연한 말이다. 다만 off-policy에서 위의 per-step importance sampling은 target policy와 behavior policy의 state distribution이 거의 유사하다는 것을 가정으로 한다.
즉 supervised learning보다 한 단계 더 어려운 테스크에 직면하고 있는 것이며, 단순히 훈련 과정에서 테크니컬하게 learning rate를 조절하는 것으로는 부족하다는 결론이 나온다. 이렇기 때문에 강화학습에서는 1-step update에서 regularization term을 둔다.
그렇다면 constrained objective는 어떻게 될까?

여기서 $d$는 어떠한 distance를 의미하며, 굳이 이것이 metric일 필요는 없다. 즉 L2 norm도 될 수 있고, KL divergence도 될 수 있다. TRPO에서는 이 distance를 KL divergence로 둔다. 왜 하필 KL인가? L-p norm도 가능할 것이고, JSD 등 다양한 것이 가능할텐데 말이다.
우선 유클리드 거리 기반 metric은 고차원 데이터의 비선형 변환에 대한 정보를 충분하게 담지 못한다는 문제점이 있다. 특히 확률분포 공간은 manifold이기 때문에 효과가 크게 떨어지고 왜곡의 가능성이 존재한다. 반면 KL divergence는 분포 간의 차이를 측정함으로써 공간의 정보를 최대한 유지한다는 효과가 있다. 특히
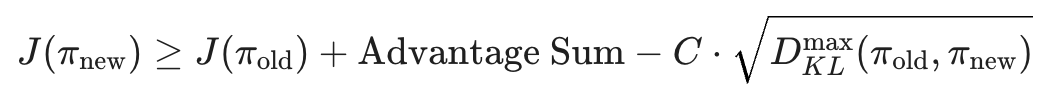
와 같은 사실은 KL divergence가 작다면, 적어도 성능은 증가할 수 있다는 것을 증명한다(Kakade & Langford (2002)). JSD는 왜 안되는가? 우선 나중에 볼 것이지만 KL divergence의 hessian은 정책의 fisher information matrix와 같아지는데, JSD는 이러한 깔끔한 형태를 가져오지 못한다. 또한 KL divergence의 monte carlo를 통한 근사는 과거의 샘플을 기준으로 하는데, JSD에서는 미래의 샘플로도 monte carlo를 적용해야 하기 때문에 애초의 목적에 맞지 않는다. -- JSD가 불필요한 이유는 단순히 TRPO의 수식 유도에서만 비롯하는 것이 아님을 알아두자.
이제 Objective를 다시 정의해보자.

라그랑지안 폼으로 constraint를 풀면 다음과 같은 형태가 된다.
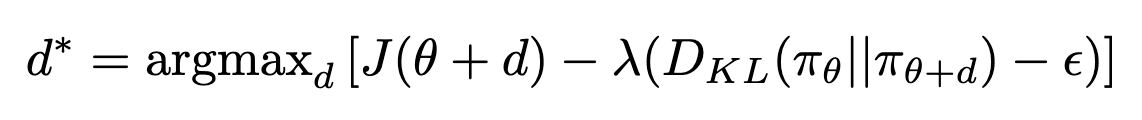
애초에 "작은 변화"를 가정했으므로, 기존 objective에 대해서는 1차 테일러 전개, KL divergence에 대해서는 2차 테일러 전개로 목적식을 근사할 수 있다.


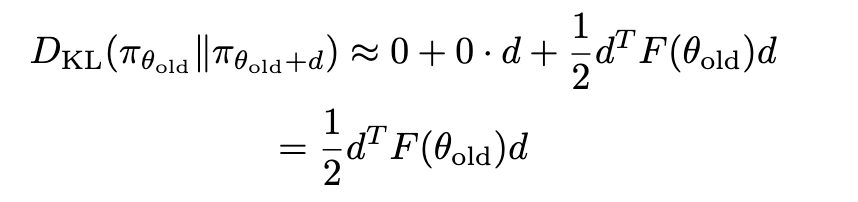
Objective는 따라서 다음과 같이 변하게 된다:

여기서 $F$는 KL divergence의 hessian 행렬으로 fisher information matrix를 지칭한다. Objective를 다시 라그랑지안 형태로 바꾸게 되면 최적 $d$를 찾을 수 있다.
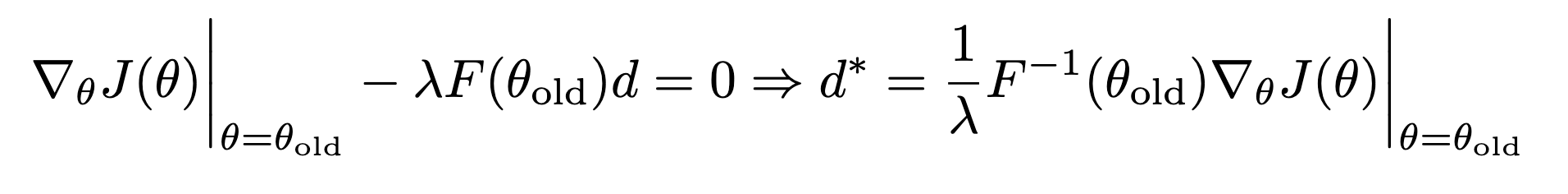
남은 $lambda$를 구하기 위해 위 objective에 $d^*$을 대입하게 되면

가 되고, 결과적으로 업데이트는

와 같은 형태가 된다. 이대로 잘 되면 정말 다행이겠지만, 굉장히 금쪽이(?) 같은 RL은 그렇지 않을 때가 많다. 우선 이대로 가는 경우의 문제점으로, (1) fisher information matrix의 inverse를 구하는 것은 사실상 불가능하며 (2) 어디까지나 테일러 근사를 사용했기 때문에 오차로 인해 의도한 바와 다르게 구해진 step이 실제로는 더 멀리 갈 수 있다. 따라서 (1)을 위해 Conjugate Gradient, (2)를 위해 Line Search를 해결책으로 TRPO는 제시한다.
우선 Conjugate Gradient를 확인해보자. 우리가 결과적으로 얻고 싶은 것은 $x$이다.

왼쪽 그대로 inverse를 구할 수 없으니, 선형 방정식을 만족하는 오른쪽의 형태로 변환하여 $x$를 찾는 과정을 거친다. 여기서 $F$가 positive semi-definite matrix이기 때문에, conjugate gradient 알고리즘을 적용할 수 있게 된다.
https://en.wikipedia.org/wiki/Conjugate_gradient_method 를 참고하자. 추가적으로 여기서 $F$를 직접 구하지 않고 hessian vector-product을 적용할 수 있다. 즉 미분을 두 번 적용하는 것이라고 보면 된다.

이제 Line Search를 확인해보자. Pseudo code를 보면 더 쉽다.

빨간색 부분은

여기서 $\alpha$ 값은 구한 step size를 스케일링해주는 계수이다. 업데이트 된 모델의 advantage가 더 증가하는지, 그리고 KL divergence constraint를 만족하는지 확인하면서, 만족하지 않는다면 j를 늘리면서 그 step size를 줄여준다. KL divergence constraint는, 보통 policy로 gaussian을 많이 쓰기 때문에 KL divergence를 closed form으로 구할 수 있다.
그러나 보다시피 매우 복잡하고 까다로운 방법이다. 정말 이상적이지만 실제로 사용되는 알고리즘이 아닌, 이론적 산물에 가까울 뿐이다. PPO는 따로 논문 리뷰에서 언급했으니, 어떠한 surrogate objective를 가지는지만 확인하자.


더더욱 간단하면서도 강력한 성능을 내는 것을 확인해볼 수 있다. 이만 마치도록 하겠다!!
'Study > Reinforcement Learning' 카테고리의 다른 글
| RLHF 기본적인 정리 (0) | 2025.12.03 |
|---|---|
| Policy Gradient 3: Off-Policy (0) | 2025.11.22 |
| Policy Gradient 2 (0) | 2025.11.21 |
| Policy Gradient 1 - REINFORCE (0) | 2025.11.21 |
| Dynamic Programming 3 (0) | 2025.11.10 |