Dynamic Programming 1 포스트에서 최적의 value function가 존재하고, 따라서 정의에 의해 $v_* (s) = \max_\pi v_\pi(s)$이며, 그리고 finite MDP에서 action space가 finite이기 때문에 $v_*(s) = \max_a Q_* (s,a)$이므로 각 state에서 이 max를 달성하는 action이 반드시 있기 때문에, 그 action을 취하는 deterministic policy가 optimal policy임을 확인했었다.
그러나 단 한 번의 closed form으로 구할 수 없거나 사실상 불가능하며, iteration을 통해서 구해야 하며, 그러한 DP의 대표적 방법론은 Policy Iteration과 Value Iteration이라는 것이다. 이번에는 이 두 방법론에 대해서 알아보도록 하겠다.
Policy Iteration
Policy Iteration은 Policy evaluation과 Policy Improvement로 나뉜다. 우선 Policy evaluation에 대해서 알아보자.
Policy evaluation
우선 Policy evaluation은 주어진 policy에 대해서 반복적으로 Bellman Expected Equation을 solve하는 것이다. 즉,
$$ v_{\pi}(s) = \sum_a \pi(a \mid s) \sum_{s', r} p(s',r\mid s,a)\left[r+\gamma v_{\pi}(s')\right] $$
을 모든 $s\in\mathcal{S}$에 대해서 solve하는 과정이 필요하다. 이것도 똑같은 논리로 $\gamma$-contraction에 의해서 해가 존재함과, 그것이 유일함이 보장되며, 이를 linear system으로써 행렬의 형태로 표현할 수 있다. (사실 역행렬이 존재함으로도 보일 수 있지만, MDP의 구조에서 오는 것으로 설명하는 것이 더 중요하다고 본다)
- $R_\pi(s)=\sum_a \pi (a\mid s) \sum_{s',r}p(s',r\mid s,a) r$
- $P_\pi(s, s') = \sum_a \pi (a\mid s)\sum_r p(s',r\mid s, a) $
로 정의하면
$$ v_\pi = R_\pi + \gamma P_{\pi}v_{\pi} \Rightarrow v_\pi = (I-\gamma P_\pi)^{-1}R_{\pi}$$
가 된다. 이렇게 역행렬을 구하는 방식으로 $v_\pi$를 얻을 수 있지만, 역행렬 계산은 $O(|S|^3)$이기 때문에 사실상 불가능에 가깝다. 하지만 우리는 contraction mapping theorem에서, iterative update 방법($v_{\pi}^{(k+1)}\leftarrow T^{\pi}v_{\pi}^{(k)}$)으로 $v_\pi$를 구할 수 있다는 사실 또한 안다. 이를 policy evaluation이라고 한다.

Policy Improvement
현재의 policy에서 policy evaluation을 통해서 value function을 전부 다 찾았으면, 주어진 state에 대해서 어떠한 행동을 취해야 더 높은 long-term return을 받는지 비교할 수 있다.
$$ q_{\pi}(s,a) = E[R_{t+1}+\gamma v_{\pi}(S_{t+1}) \mid S_t=s, A_t = a] $$
이기 때문이다.
이제 policy improvement theorem을 보자. 일단은 어려운 가정 없이 새로운 deterministic policy $\pi'$, 즉 $\pi$로부터 얻은 value function에서, 각 state에서 가장 좋은 action만 고르는 policy를 가정하자.
$$ \begin{align*} q_{\pi}(s, \pi'(s))&=E[R_{t+1}+\gamma v_{\pi}(S_{t+1})\mid S_t = s, A_t = \pi'(s)] \\ &\geq E[R_{t+1}+\gamma v_{\pi}(S_{t+1})\mid S_t=s]=v_\pi(s)\end{align*} $$
를 모든 state에 대해서 만족한다고 하자. 그렇다면 $v_\pi \leq v_\pi'$이 성립한다. Policy improvement theorem의 증명은 다음과 같다.
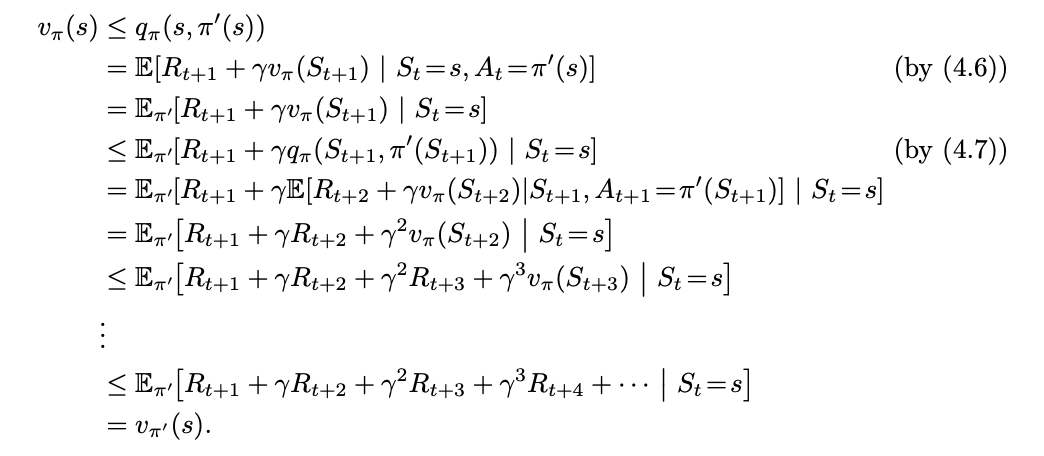
여기서 한 가지 자연스러운 질문이 생긴다. 그렇다면 deterministic policy가 아닌 stochastic policy의 경우에는 성립하지 않는가? 그렇다고 말할 수 없다. Policy Improvement는 deterministic 제한이 아니라, 단지 다음 조건만 만족하면 된다.
$$ E_{\pi'}[R_{t+1}+\gamma v_\pi (S_{t+1}) \mid S_t] = \sum_{a}\pi'(a\mid s)\sum_{s', r}p(s', r\mid s,a)[r + \gamma v_{\pi}(s')]$$
가 $v_{\pi}(s)$보다 크거나 같은 것이 모든 state에서 성립하기만 하면, deterministic이든 stochastic이든 상관 없이 더 좋은 policy를 만들 수 있다.
이렇게 두 과정을 알아봤다. Policy iteration은 이 두 과정을 반복적으로 진행하면서 최적 policy에 도달하는 과정을 말한다.

알고리즘부터 확인해보자.

아직 근데 한 가지 질문이 남아있다. Policy improvement theorem은 그저 one step 개선이 가능함을 보장하는 것이지, 그것이 global하게 optimum인 policy를 도달하게 하는 것의 근거는 아니다. 그렇다면 policy iteration은 local optimum에 빠질 가능성이 아예 없는가? 다시 말해서, PI에서 update에 대한 변화량이 거의 없다면, 즉 local optima에 도달했다면 그것 자체가 global optima임을 어떻게 보장하는가?

$\pi$가 $v_\pi$에 대해서 greedy이고, 업데이트된 정책을 $\pi'$라 하자. Policy improvement 과정에서 max연산자로 인해
$$ v_{\pi'}(s)=\sum_a \pi'(a\mid s)q_{\pi}(s,a) = \max_a q_{\pi}(s,a) \geq \sum_a \pi(a\mid s)q_\pi(s, a) = v_{\pi}(s) $$
가 된다.
$v_{\pi'}(s) = v_{\pi}(s), \forall s$를 가정해보자. 이 말은 즉 policy를 업데이트했음에도 불구하고 value가 개선되지 않는 상태, 즉 local optima에 빠졌다는 것을 의미한다. 그런데 이전에 우리는 bellman optimal operator에서, banach fixed point theorem에 의해 위의 equation이 성립하는 $v^*$는 유일하다는 것을 보았다. 즉 그러한 $v^*$에 도달했다는 것 자체가 최적이라는 것이다.
따라서 우리는 로컬 옵티마에 도달했다고 생각했지만, 결국에는 그것이 글로벌 옵티마가 되는 것이다.
Stochastic Policy의 경우에는 local optima에 빠질 수 있기는 하다. 한번 예시를 생각해보면 좋겠다.
Value Iteration
이전 포스트에서 확인했듯이 Bellman Optimal Operator $T^*$는 $\gamma$-contraction임을 보였고, 따라서 유일한 fixed point $v_*$가 존재하며 반복적 적용만으로 그 fixed point에 수렴할 수 있다. Value Iteration은 이 사실을 그대로 사용하는 알고리즘이다. Policy Iteration과 달리 별도의 policy evaluation–improvement 분리를 하지 않고, value function만을 직접적으로 update하여 optimality에 도달한다. 알고리즘은 다음과 같다.

이후 포스트는 이 두 알고리즘을 비교하는 동시에, DP에 대해서 더 공부해보는 시간을 가지자.
'Study > Reinforcement Learning' 카테고리의 다른 글
| Policy Gradient 1 - REINFORCE (0) | 2025.11.21 |
|---|---|
| Dynamic Programming 3 (0) | 2025.11.10 |
| Dynamic Programming 1 (0) | 2025.11.10 |
| Bellman Equation (0) | 2025.11.10 |
| Markov Decision Process (0) | 2025.11.09 |