기존의 Value-based RL, 예를 들어서 Q-learning의 경우 state-action value function $Q(s,a)$를 학습한 뒤, 이를 기반으로 행동을 결정하는 간접적인 방식을 취한다. 반면 policy gradent는 정책 $\pi_\theta$를 직접 모델링하고 최적화함으로써 이러한 문제를 해결하고자 한다.
우선 notation을 명확히 하자. Finite trajectory를 우선 기본 설정으로 하자.
- Trajectory) $\tau := (s_0, a_0, s_1, a_1, ..., s_T, a_T)$
- Trajectory Reward) $R(\tau) = \sum_{i=0}^T R(s_i, a_i) $
- Trajectory Distribution) $P(\tau;\pi,\theta) = \prod_{t=0}^T p(s_{t+1} \mid s_t, a_t) \pi_{\theta}(a_t|s_t)$
강화학습의 목표는 주어진 state에서 시작하여 얻는 총 보상을 최대화하는 것이므로,
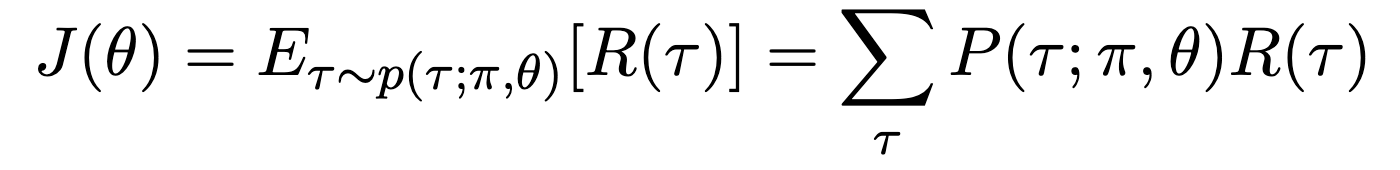
가 objective가 된다. 이 objective를 미분하면
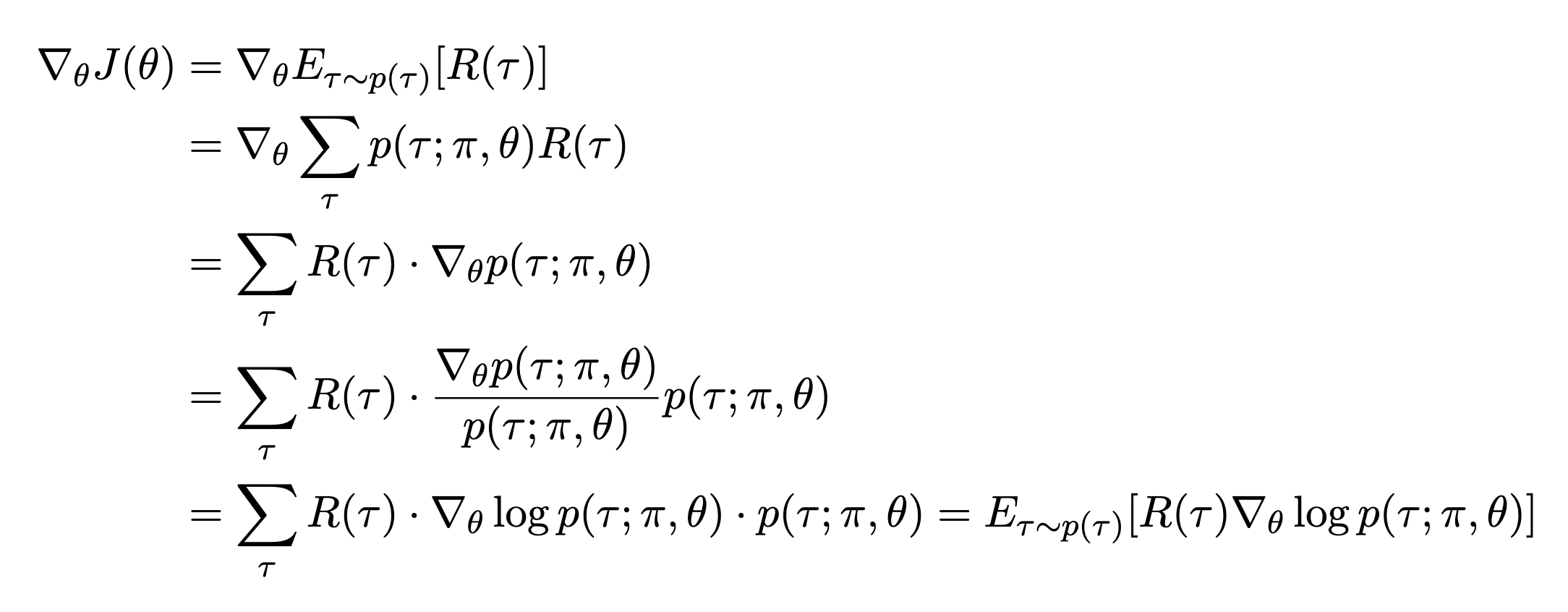
가 되고,
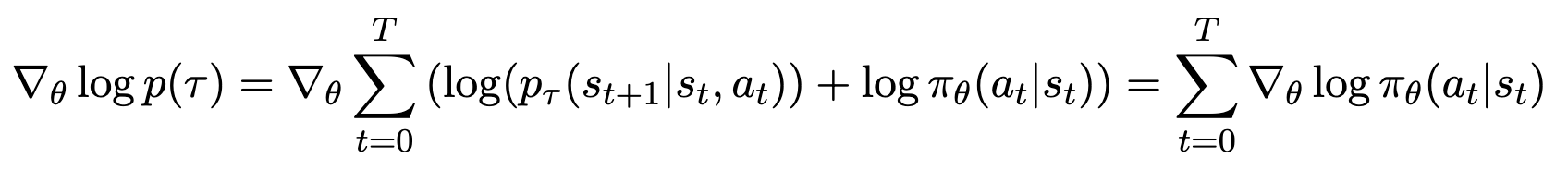
를 도출함에 따라
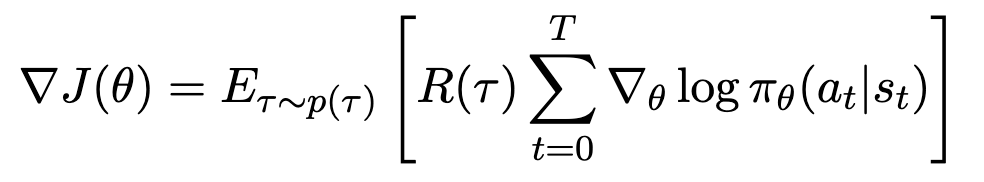
의 형태가 됨을 알 수 있다. 이에 대한 Monte Carlo unbiased estimate는 다음과 같다:

그러나 $t$ 시점 policy의 행동은 그 이후 보상에 대해서만 관여를 하지, 그 이전에 대해서는 관여하지 않는다. 따라서 아래와 같은 식으로 다시 만들어짐을 알 수 있다.

여기까지가 RENIFORCE에 관한 내용이다. 그러나 estimate에는 그에 대한 분산이 어느정도인가에 대해서 알아볼 필요가 있고, 그것이 최소의 variance가 아니라면 이 unbiasedness를 유지하거나, 살짝의 bias를 가져오면서 variance를 닞추는 방법에 대해서 알아볼 필요가 있다. 다음 포스트에서는 baseline을 통한 variance reduction을 알아보고, 결과적으로 나오는 actor-critic 구조에 대해서 탐구해보도록 하자.
'Study > Reinforcement Learning' 카테고리의 다른 글
| Policy Gradient 3: Off-Policy (0) | 2025.11.22 |
|---|---|
| Policy Gradient 2 (0) | 2025.11.21 |
| Dynamic Programming 3 (0) | 2025.11.10 |
| Dynamic Programming 2 (0) | 2025.11.10 |
| Dynamic Programming 1 (0) | 2025.11.10 |