Recap
Off-Policy
Off-policy란 데이터를 수집하는 정책(Behavior Policy)과 학습하려는 정책(Target Policy)이 분리된 강화학습 방법론을 의미한다.
일반적인 딥러닝은 데이터가 많을수록 학습 효과가 좋지만, 강화학습은 정책이 업데이트됨에 따라 과거에 수집한 데이터의 분포가 현재 정책과 달라지는(Outdated) 문제가 발생한다. 따라서 On-policy 방식은 이 과거 데이터를 학습에 사용할 수 없어 버려야 하므로 '샘플 효율성(Sample Efficiency)'이 낮다는 단점이 있다.
반면, Off-policy 방법론은 과거의 데이터나 다른 정책이 생성한 데이터까지 학습에 적극적으로 재사용(Replay)함으로써, 데이터 부족 문제를 해결하고 학습 효율을 극대화하는 것을 목표로 한다. 특히 과거의 수집한 데이터 분포가 현재 정책과 달라지는 문제를 해결하는 것을 주된 관심사로 둔다.
Importance Sampling
Importance sampling의 기본적인 형태는 다음과 같다:

여기서 $P$는 그 형태를 알고 있지만 샘플링이 어려운 분포이고, $Q$는 샘플링이 쉬운 분포를 의미한다. 이렇게 tractable하지 않은 분포를 다른 분포로 샘플링하여, 그 비율을 보정하여 원하는 적분값을 MC를 통해 도출할 수 있는 것이다.
강화학습, 특히 off-policy에서도 이 방법이 사용된다. 이제 한 번 살펴보도록 하자.
Objective는 다음과 같다:

이 objective에 대한 Monte Carlo estimate는 $\theta$를 파라미터로 가지고 있는 policy $\pi$가 만들어내는 trajectory sample의 평균이 될 것인데, off-policy는 과거의 데이터를 바탕으로 훈련해야 한다는 문제점이 있다. 따라서

와 같은 형태로 바꿀 수 있고, 이렇게 되면 과거의 샘플을 바탕으로 unbiased monte carlo estimate를 만들 수 있게 되는 것이다. Objective의 그래디언트 또한 다음과 같이 바꾸어줄 수 있다:
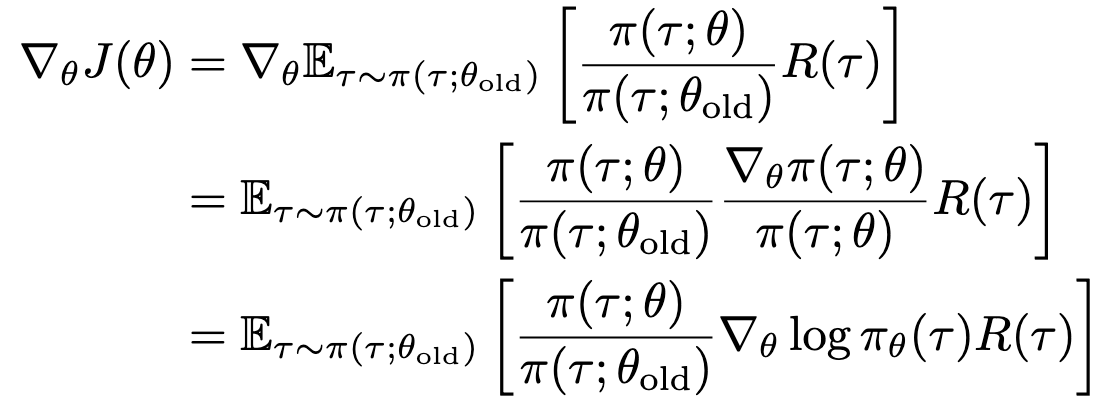
이 형태를 더 파헤쳐보자. Trajectory 비율은 다음과 같다:

이를 이용하면 objective의 gradient를 다음과 같이 계산할 수 있다.

그러나 이대로 형태가 끝나면 안된다. 우선 몇 가지 원칙에 대해서 살펴보면:
- 현 시점의 행동은 미래의 보상에만 책임이 있지, 그 전과는 무관하다. 즉 그래디언트에 곱해지는 보상의 term은 t-step부터 시작해서 T(terminal)까지만 반영해야 한다.
- 현 시점으로 도달할 확률은 과거에 의해 좌우된다. 따라서 그래디언트에 곱해지는 importance sampling ratio는 0-step부터 t-step까지만 유효하다.
따라서 다음과 같은 형태가 된다:

아직 문제가 다 끝난 것이 아니다. Trajectory에 대해서 monte-carlo를 해주는 경우
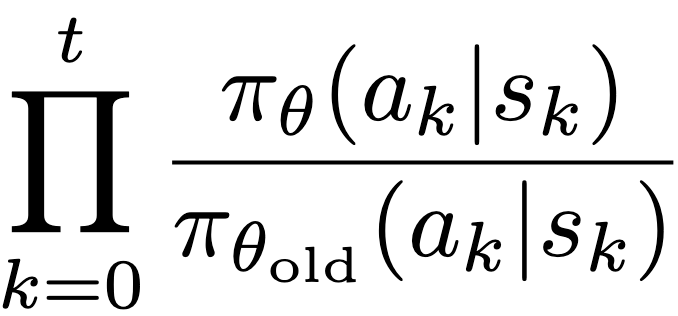
가 vanish하거나 explode하여 올바른 MC estimate 자체를 하기 어려워진다는 문제점이 있다. Sequence가 길어질수록 이 문제는 필연적이라는 것을 알 수 있을 것이다. 따라서 trajectory에 대한 importance sampling을 하지 않고, step에 대해서 importance sampling을 해주는 방향으로 바뀌어야 한다.
Trajectory 관점에서 per-step관점으로 바꾸면 다음과 같다:
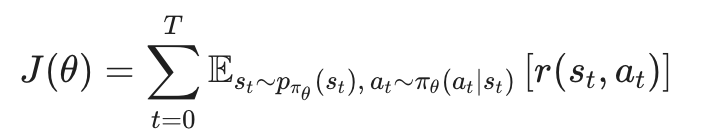
이 상태에서 importance sampling을 적용해보자.
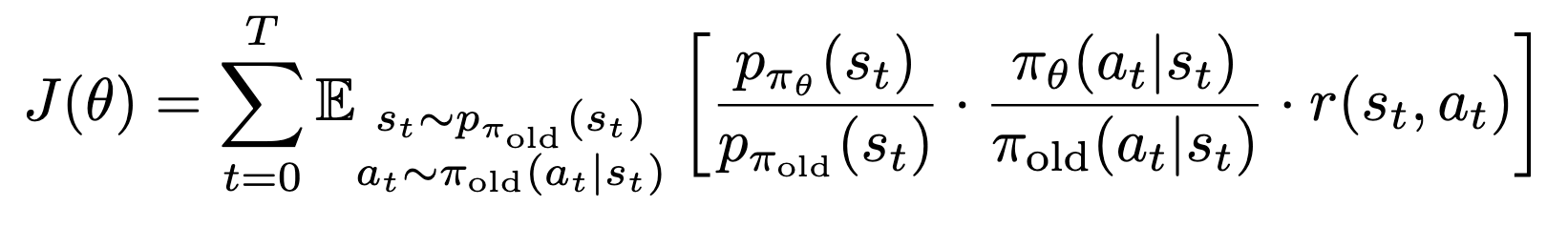
여기서 policy를 따르는 state distribution은 사실상 구하는 것이 불가능하기 때문에, 그 비율을 1로 대체한다. 이대로 gradient를 계산해보면 다음과 같은 수식이 나온다:

Trajectory에 대해서 importance sampling을 하는 경우는 trajectory 전체에 대해서 평균을 취해준 반면, per-step importance sampling의 경우 step마다의 평균의 합으로 그래디언트를 구하는 것을 확인할 수 있다. 저번 포스트에서 baseline을 다룬 것처럼, 추가적으로 분산을 낮추기 위해 R을 advantage로 대체한다.
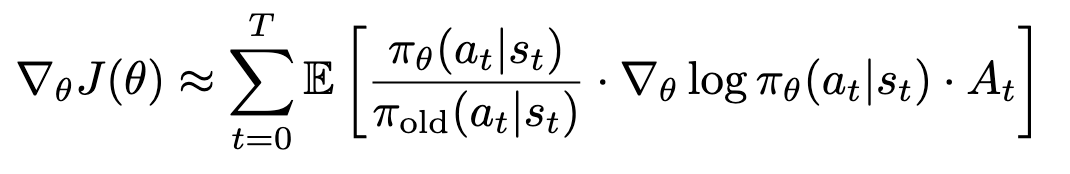
그래디언트가 구해지는 것만으로는 policy gradient가 끝나지 않는다. 여전히 per-step importance ratio가 폭발할 수 있는 문제점은 충분히 있으며, state distribution을 단순히 1로 생략해버리는 것은 정책이 급격하게 변화하지 않았다는 가정이 전제되었기 때문이다. 따라서 다음 포스트에서는 Trust Region을 활용한 TRPO, clipping을 적용한 PPO에 대해서 알아보도록 하겠다.
'Study > Reinforcement Learning' 카테고리의 다른 글
| RLHF 기본적인 정리 (0) | 2025.12.03 |
|---|---|
| Policy Gradient 4: TRPO & PPO (0) | 2025.11.22 |
| Policy Gradient 2 (0) | 2025.11.21 |
| Policy Gradient 1 - REINFORCE (0) | 2025.11.21 |
| Dynamic Programming 3 (0) | 2025.11.10 |