Policy가 더 좋다는 것은 다음과 같은 definition에 의해 표현된다.
$$ \pi\geq\pi' \text{ if and only if } v_{\pi}(s) \geq v_{\pi'}(s), \forall s\in\mathcal{S} $$
어떤 policy가 모든 state에서 더 큰 expected reward, 즉 value를 제공한다면 그 policy가 다른 policy보다 더 좋다고 말할 수 있는 것이다. 그렇다면 우선, "모든 policy 중에서 가장 좋은 policy가 존재할 수 있는가"에 대한 의문이 제기될 것이다.
이러한 존재성을 확인하기에 앞서서, Bellman Optimal Equation을 먼저 확인해보자.
$$ v_{*}(s) = \max_a \sum_{s',r}p(s',r\mid s,a)(r+\gamma v_{*}(s')) $$
Optimal value function은 $v_{*}(s)=\max_\pi v_\pi(s)$이며, 즉 어떤 policy를 따라갔을 때 얻을 수 있는 long-term return들 중 가장 큰 return을 주는 value function이다. 이를 action 관점에서 해석하면, optimal policy는 각 state에서 가장 좋은 action을 선택하는 policy와 동일해진다. 따라서 optimal value function은 “optimal policy 하에서의 expected return”과 “가능한 action들 중 최선의 action을 선택했을 때 얻는 기대 return”이 일치하는 형태를 만족해야 한다. 이 recursive relationship이 Bellman Optimal Equation이다.
이 equation을 하나의 mapping, 즉 v라는 함수를 또다른 v로 매핑하는 operator의 관점으로 볼 수 있다. 즉
$$ (T^{*}v)(s) = \max_a \sum_{s',r}p(s',r\mid s,a)(r + \gamma v(s')) $$
에서 v라는 함수가 주어지면, 그것을 input으로 받아서 "새로운 함수"를 output으로 돌려주는 operator가 되는 것이다.
이 operator 관점이 중요한 이유는, 이 operator가 contraction임을 보일 수 있고, 그 결과 유일한 fixed point가 존재함을 보일 수 있기 때문이다. 그리고 그 fixed point가 바로 optimal value function $v_{*}$ 이다.
Banach Fixed Point Theorem
Fixed point란 $ f(x) = x $를 만족하는 어떤 점 $x\in\mathcal{X}$를 의미한다. 만약
$$ \exists v^{*}\in\mathcal{V} \text{ s.t. } T^*(v^*)=v^* $$
라고 하면, $v^*$는 fixed point를 만족하며
$$ v_{*}(s) = \max_a \sum_{s',r}p(s',r\mid s,a)(r+\gamma v_{*}(s')), $$
즉 Bellman Optimal Equation을 만족하므로 $v^{*}$는 optimal value function이다.
이러한 optimal value function 존재성은 Banach Fixed Point Theorem으로 증명할 수 있다.

우선 $(\mathcal{V}, \|\cdot\|_{\infty})$가 complete metric space임을 확인해보자. Value는 bounded이며 state와 action은 finite하다고 가정하겠다. Complete space는 모든 Cauchy sequence가 limit이 존재하는 경우를 의미하며, sup-norm은 well-defined metric이다.
이제 임의의 Cauchy sequence $v^{(k)}$를 생각하자. 이는
$$ \|v^{(k)}-v^{(l)}\|_{\infty}\rightarrow 0, (k,l \rightarrow \infty) $$
를 의미한다. Sup norm은 가장 차이가 많이 나는 component 간의 거리를 metric으로 정하기 때문에 모든 state $s$에 대해서

가 성립힌다. 여기서 $v^{(k)}(s)\in\mathbb{R}$이고 $\mathbb{R}$은 complete space이므로, 각 state $s$에 대해서 limit가 존재한다.
각 component가 limit을 가지기 때문에, 그 함수 $v^{(k)}$ 또한 limit을 가진다. 따라서 임의의 Cauchy sequence $v^{(k)}$가 수렴하므로 $(\mathcal{V}, \|\cdot\|_{\infty})$가 complete metric space가 된다.
이제 contraction인지 확인해보자.
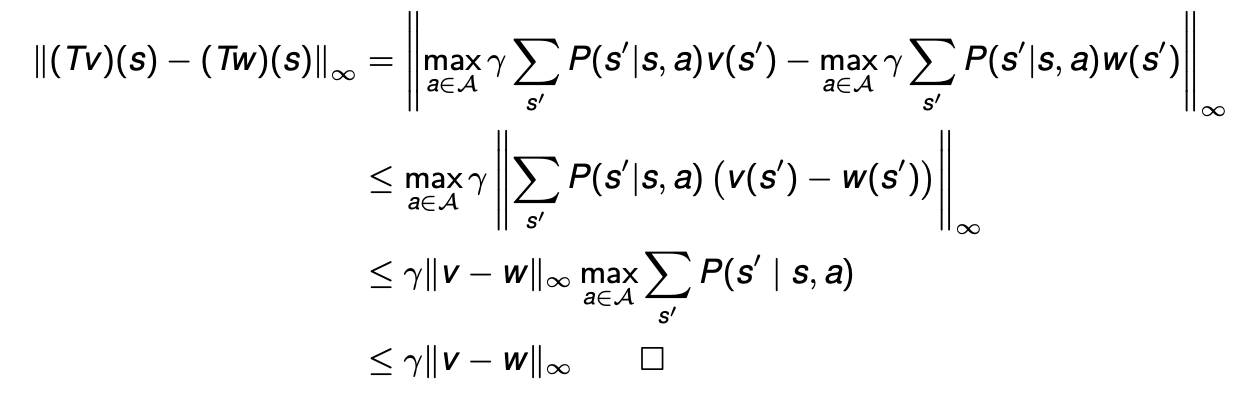
따라서 Banach Fixed Point theorem에 의해
$$ \exists v^{*}\in\mathcal{V} \text{ s.t. } T^*(v^*)=v^* $$
를 얻을 수 있으며 그 최적점은
$$ v^{(k+1)} \leftarrow T^{*}v^{(k)} $$
의 iteration을 통해서 얻을 수 있음이 증명된다.
이렇게 최적의 value가 유일하게 존재함을 확인했으니, 최적의 policy 또한 최적의 value function이 존재한다면 얻을 수 있다는 것이 정당화된다. 다만 주의해야 할 점은 최적 policy는 반드시 하나인 것은 아니라는 것을 명확하게 알아두자. 반례로,
A와 B라는 state가 있고, 각 state에서 자기 자신으로 돌아가거나, 다른 state로 옮겨가는 action이 존재하고, 자기 자신에게 가는 경우 보상이 1, 다른 state로 옮겨가는 경우 보상이 -900인 경우를 가정하자.
Deterministic policy는 $A^S$만큼 존재하므로, 이 경우는 4개의 deterministic policy가 존재한다. 그 중에서 최적의 policy는 각자의 state에서 자기 자신으로 돌아가는 움직임만 하는 policy 두 개이다. 즉 존재하지만 unique는 아니게 되는 것이다.
결론적으로 최적의 value function가 존재하고, 따라서 정의에 의해 $v_* (s) = \max_\pi v_\pi(s)$이며, 그리고 finite MDP에서 action space가 finite이기 때문에 $v_*(s) = \max_a Q_* (s,a)$이므로 각 state에서 이 max를 달성하는 action이 반드시 있기 때문에, 그 action을 취하는 deterministic policy가 optimal policy임을 확인할 수 있다. 이제는 Dynamic Programming의 정의를 알아보자.

즉 environment를 완전하게 알고 있다는 전제 하에서 optimal policy를 구하는 방법들의 집합을 Dynamic Policy라고 한다! 그렇다면
$$ v_{*}(s) = \max_a \sum_{s',r}p(s',r\mid s,a)(r+\gamma v_{*}(s')) $$
의 closed form 형태를 바로 구할 수 있을까?
그렇지 않다. 이 식은 max operator 때문에 비선형 형태이며, 선형 방정식처럼 단순 역행렬 형태로 한 번에 closed-form으로 풀 수 없다. 따라서 optimality는 결국 iterative method를 통해서만 접근할 수 있다. 대표적인 접근 방식 두 개가 존재하며, 첫 번째는 policy를 개선하면서 올라가는 Policy Iteration이고, 두 번째는 Bellman Optimal Operator 자체를 반복 적용하여 수렴시키는 Value Iteration이다.
다음 포스트에서는 이러한 optimal value function을 실제로 찾아내는 방법 중 하나인 Policy Iteration에 대해 다루어보자.
'Study > Reinforcement Learning' 카테고리의 다른 글
| Dynamic Programming 3 (0) | 2025.11.10 |
|---|---|
| Dynamic Programming 2 (0) | 2025.11.10 |
| Bellman Equation (0) | 2025.11.10 |
| Markov Decision Process (0) | 2025.11.09 |
| Definition of Reinforcement Learning (0) | 2025.11.09 |