ADVERSARIAL MASKED AUTOENCODER PURIFIER WITH DEFENSE TRANSFERABILITY
Summary
본 논문은 적대적 공격(Adversarial Attack) 으로 교란된 이미지를 정화(purification) 하여 원본에 가깝게 복원한 뒤 분류하는 테스트타임 방어(test-time defense) 기법을 제안한다. 특히, 기존에 주로 사용되던 diffusion 모델 기반 정화 방식이 높은 연산 비용과 낮은 데이터셋 전이 성능을 보이는 한계를 극복하기 위해, 저자는 Masked AutoEncoder(MAE) 를 adversarial purifier 프레임워크에 통합한 MAEP(Masked AutoEncoder Purifier) 를 설계하였다.
MAEP는 추가적인 외부 데이터 없이도 학습이 가능하며, 방어 전이성(defense transferability) 과 공격 일반화(attack generalization) 를 갖추었다. CIFAR-10에서 학습된 MAEP는 ImageNet 데이터셋에 직접 적용했을 때도 기존 ImageNet 전용 diffusion 기반 방어 모델보다 뛰어난 성능을 기록하며, cross-dataset adversarial defense 분야에서 SOTA(State-Of-The-Art) 를 달성하였다.
Preliminary
Adversarial Attack
$\theta$를 패러미터로 가지고 있는 분류기 $C$에 대해서, adversarial attack은 적대적 샘플 $x_a$와 실제 샘플 $x$ 간의 거리를 $\epsilon$ 이하로 제어하면서 모델 예측 손실를 최대화하고자 한다. 즉 아래와 같은 식의 최적화를 수행한다:

Masked Autoencoder

Masked autoencoder은 인코더 $f$를 거치면서 마스킹된 데이터와 마스킹되지 않은 데이터의 표현을 출력하고, 디코더 $g$에서 마스킹된 부분을 복구하여 마스킹된 데이터와 원본 데이터 간의 차이(loss)를 줄이는 과정을 통해 학습된다. 즉,

이다. 이 때 $M$에서 $1$은 보이는 패치, $0$, 즉 $(1-M)=1$은 가려진 패치를 의미한다.
Adversarial Purification
Adversarial purification 기법은 크게 두 가지로 나눌 수 있다.
- 테스트타임 정화(test-time purification): 입력 이미지를 분류기 전에 anti-adversary layer나 별도의 정화 네트워크를 거쳐, 적대적 노이즈를 제거하는 방식이다. 대표적으로 anti-adversary layer는 adversarial 이미지를 정확하게 식별해 경계에서 멀어지도록 변환하지만, 이 과정이 여전히 공격 성공 여부에 크게 의존하므로 강력한 공격에는 취약하다.
- 훈련단계 방어(training-time defense): 학습 시점부터 입력에 노이즈를 추가하거나 데이터 증강을 활용해, 모델이 다양한 교란에 견디도록 만드는 방식이다. 특정 공격 패턴에 맞춰 supervised learning으로 학습된 경우, 새로운 유형의 공격에는 대응력이 떨어지는 한계가 있다.
훈련단계 방어를 구현하는 가장 강력한 프레임워크로는 diffusion 기반 모델인데, 이는 점진적인 노이즈 추가와 제거 과정을 통해 이미지를 복원(reverse diffusion)하는, 근본적으로 설계된 특성이 존재하기 때문이다. 그러나 이러한 방식은 전이성 부족이라는 뚜렷한 한계가 있다. 본 논문에서는 diffusion 기반 프레임워크인 DiffPure가 CIFAR10에서 학습되고 나서 CIFAR100으로 전이하는 경우 여전히 적대적 공격에 취약해짐을 보인다.
Purification Accuracy vs. Clean Accuracy
Purification accuracy는 적대적 이미지 $x_a$를 purifier $P$에 통과시켜 정화한 후, 원래의 clean 이미지 $x$와 동일한 라벨을 얼마나 잘 맞추는지에 관한 정확도이다.
$$ c(P(x_a)) \approx c(x) $$
여기서 $c$는 고정된 사전학습 분류기이다.
Clean Accuracy는 원래 clean 이미지 $x$를 purifier $P$에 통과시킨 후에도 라벨이 바뀌지 않는지에 대한 정확도이다. 즉,
$$ c(P(x)) \approx c(x) $$
따라서 공격이 없는 정상 이미지에 대해서도 purifier가 성능을 해치지 않는지를 검증한다.
이 두 accuracy는 tradeoff 관계를 보이며, 본 논문은 purification accuracy와 clean accuracy 간 gap을 줄이고자 한다.
Method
본 논문은 다음과 같은 loss function을 제안한다:

(참고로 $M$은 masking matrix이며, $M=1, M$은 보이는 패치, $M=0, 1-M$은 보이지 않는 패치를 의미한다.)
Purify loss는 적대적 이미지를 input으로 넣은 후, purifier $g(f(\cdot))$에 마스킹되지 않은 패치(보이는 패치)를 복구하는 과정에서 기존 clean image와 비교하여 같아지도록 학습한다.
두 번째 항은 우리가 알고 있는 MAE의 loss와 비슷한데, 여기에서 $x_a$가 input으로 들어가있는 것을 확인할 수 있다. 이것이 단순히 $x$를 넣었을 때와 어떻게 다른지 생각해보자.
- 만약 $x$를 input으로 넣는다면, 원본의 clean image를 복원하는 과정에서 마스킹되지 않은 패치의 representation + positional encoding을 바탕으로 복원할 것이다.
- 만약 $x_a$를 input으로 넣는다면, 원본의 clean image를 복원하기 위해 purifier 로직 내부에서 올바른 표현으로 복구하고자 하는 학습이 진행될 것이다.
솔직히 두 번째 항에서 $x_a$가 아닌 $x$로 두는 것이 더 좋을 것 같은데, 이에 대한 설명이 존재하지 않아 넘어가도록 하겠다(아쉽다).
학습이 다 완료된 후 encoder만 추출하여 downstream task를 한다. 이렇게 학습하는 경우 훈련단계 방어를 효과적으로 구현하면서도 더 고차원의 학습이 가능하며, 학습 또한 diffusion 기반에 비해서 더욱 쉽다.
따라서 이제 검증해야 할 것은, 실제로 이 모델이 1. Purification accuracy와 Clean accuracy 간의 gap을 줄이는지, 2. 전이학습이 원활하게 이루어질 수 있는지다.
Experiments
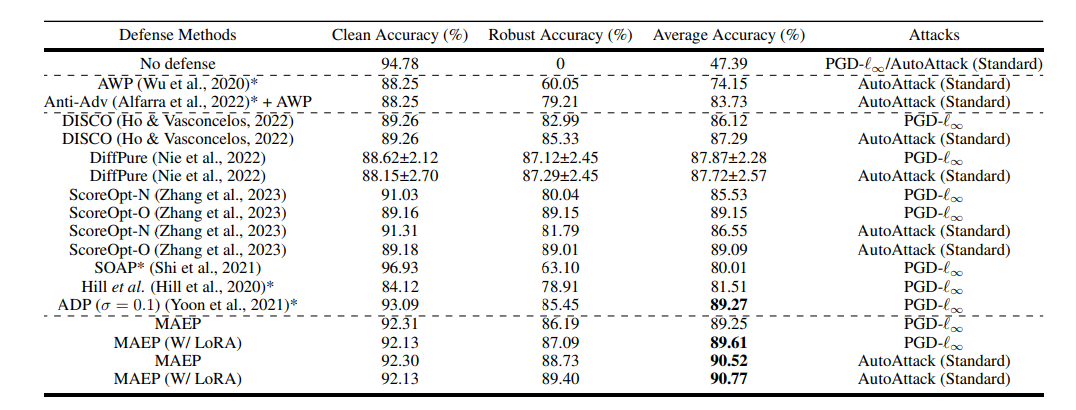

첫 번째 테이블은 CIFAR-10, 두 번째 테이블은 CIFAR-100에 대한 테스트 결과이다. 다른 방법론에 비해서 준수한 성능을 유지하면서 Purification accuracy와 clean accuracy 간 gap도 작은 것을 확인할 수 있다.
이번에는 Transferability에 대해서 확인해보자.

MAEP 방법론이 Diffusion 계열 방법보다 전이성에서 더 우수한 성능을 보이는 것을 확인할 수 있다. 특히 attack(perturbation) budget $\epsilon$을 보면, 공격의 강도가 더욱 세졌는데도 성능이 잘 유지되는 것을 확인할 수 있다. (DISCO나 DiffPure에는 왜 안한거지 ㅡ,ㅡ)
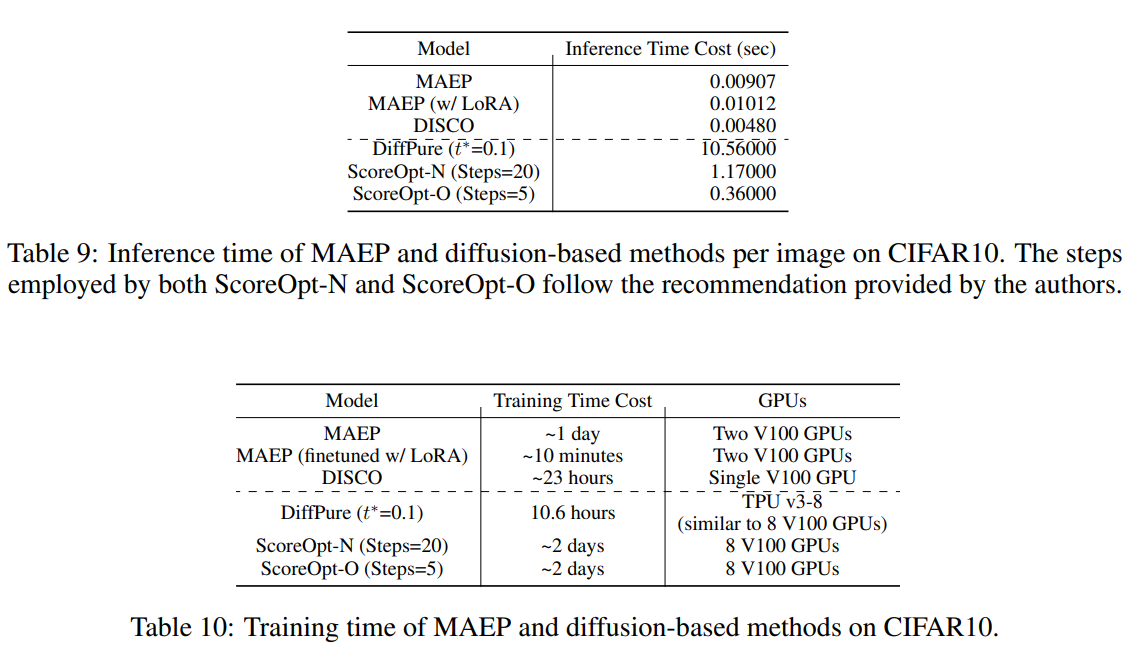
속도도 빠른 것을 확인해볼 수 있다.
Conclusion
본 논문에 대해서 필자가 생각하는 이 논문의 우수한 점은 다음과 같다:
- MAE를 이용하여 적대적 공격 샘플을 clean한 샘플로 복원하는 과정을 학습하게 하여 조금 더 일반화된 모델을 학습했다는 점
- ViT 구조를 이용하여 CNN 계열 모델의 한계인 inductive bias로 인해 일반화 성능이 떨어지는 것을 막은 것
- 마지막으로 다른 테스크에 대해서도 전이학습이 뛰어남을 보인 것
'논문 리뷰 > CV' 카테고리의 다른 글
| BYOL 논문 리뷰 (2) | 2025.08.17 |
|---|---|
| Vision Transformers Need Registers 논문 리뷰 (2) | 2025.08.15 |
| MAE 논문 리뷰 (feat: Inductive Bias) (2) | 2025.08.12 |
| YOLO 논문 리뷰 (5) | 2025.08.11 |
| Faster R-CNN 논문 리뷰 (0) | 2025.08.10 |