Masked Autoencoders Are Scalable Vision Learners
논문을 읽다가 계속 생각난 것이 inductive bias이다. 이에 대해서 설명하기 위해 본 논문을 리뷰하니, 다른 부분은 살짝 힘을 빼겠다..ㅎㅎ
Approach
기본적으로 Encoder-Decoder 구조이며, Transformer 기반이다. 특징은 asymmetric하다는 것이다.

Encoder
Input Image는 $P$개의 패치로 쪼개어지고 토큰 변화가 된다(포지셔널 임베딩 포함). 무작위로 Shuffle한 후, 상위 p%의 input 패치만 보존하여 선택한다. 여기서 핵심은, 단순히 BERT처럼 마스킹한 후 [MASK] 토큰으로 변환하는 것이 아니라 아예 없애버린다는 것이다. 여기서 몇 가지 포인트가 있는데,
- 단순히 sparse operation을 적용하는 것이 아니라 shuffle & select를 하면 GPU 연산을 줄일 수 있다.
- shuffle 과정에서 원래의 위치를 기억한 다음, 각 패치에 대한 representation을 shuffle한 순서를 고려하여 재배열(inverse, unshuffle)한다.
이렇게 전체 $(P, d_{embed})$만큼의 벡터가 채워지며, 이 때 삭제되었던(마스킹되었던) 패치의 토큰은 공유된 learnable token + positional embedding으로 초기화된다.
Decoder
Decoder은 전체 $(P, d_{embed})$ 시퀀스를 입력받으며, 각 패치에 대해서 복원을 출력을 만든다. 복원을 시도하되, loss 계산과 파라미터 업데이트는 오로지 마스킹된 패치에서만 이루어진다. 또한 backpropagation이 인코더까지 전달되어 인코더는 마스킹되지 않은 패치에 대해 더 좋은 표현을 학습하도록 유도된다.
Experiment
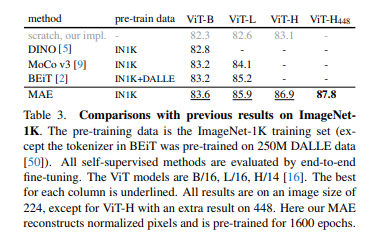
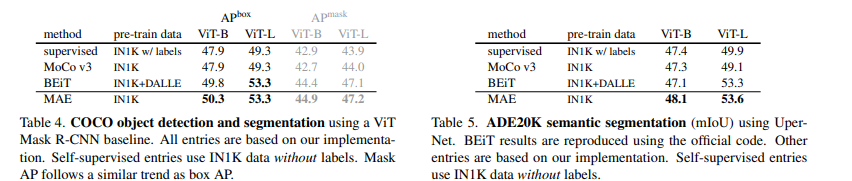

MAE가 다양한 벤치마크에서 일관되게 SOTA성능을 달성하는 것을 확인할 수 있다. 이전 자기지도 학습 방법과 비교했을 때에도 좋으며, 분류 등의 다운스트임 작업 모두에서 기존 접근법을 능가하는 것을 확인할 수 있다.
즉 위의 실험들은 다운스트림 작업 성능 향상에서 MAE 사전학습의 효과를 검증한다고 볼 수 있다.
Inductive Bias
사실 Experiments 좋지만 필자의 생각에 이 논문이 보여주고 싶은 것은 바로 inductive bias이다. 이 논문을 보고 감탄을 어디서 하느냐가 논문 리더로서의 통찰력을 검증할 수 있다고 본다.
본 논문에서 흥미롭게 제시한 사실들은 다음과 같다.
- Masking ratio가 일정 수준일 때 accuracy가 최대일 것이라고 생각하는 것은 상식적이다. 그러나 masking ratio가 20~30%에서 최적일 것이라 생각하는 것에 비해, 65~75%에서 accuracy가 최대가 된다는 연구 결과는 상식적이지 않다.
- Encoding 과정에서 마스킹된 패치는 아예 삭제되는데, 삭제하지 않고 mask 토큰을 두는 경우가 성능이 더 떨어진다. 그렇게까지 많이 masking이 되는데, 그 마스킹마저 제거해버리면 이미지 복구 자체를 못할 것 같다는 생각이 상식적이다.
- 그래도... CNN 기반으로 masking하여 복구하는 것을 딱히 보여주지도 않았고 시도조차도 하지 않았다.


바로 Inductive Bias 때문이다! Inductive Bias를 다시 recap해보면...
Inductive Bias란 모델이 학습 데이터 바깥의 새로운 데이터를 일반화(generalization)할 때, 올바른 예측을 하기 위해 사전에 주어진 구조적 가정이나 제한이고, 즉 학습을 잘 하기 위해 '설계된 편향'인 것이다.
- Linear Regression: 독립변수와 종속변수 간의 관계가 선형적이라 가정하고, 오차는 정규분포를 따른다고 가정한다.
- Decision Tree: 특정 feature의 값에 따라 데이터를 구분할 수 있다.
CNN이 컴퓨팅이 오늘날처럼 발전하기 이전에도, 데이터가 비교적 적을 때에도 NLP보다 먼저 발전할 수 있었던 이유는 바로 그 inductive bias 때문인데,
- Locality: 가까운 픽셀들끼리 더 높은 상관관계를 가진다고 가정한다. 즉, 지역적인 정보(작은 receptive field)만 먼저 보고 점차 큰 패턴을 인식하도록 설계되어 있다.
- CNN은 작은 Kernel을 통해서 국소적인 픽셀 정보들을 이용하여 정보를 추출하기 때문에, 공간적으로 가까운 정보일수록 더욱 연관이 있으며 중요하다는 귀납적 편향을 내포한다.
- Translation Equivariance: "이미지 상의 특정 패턴은 위치에 관계없이 동일한 의미를 가진다"는 가정이다. 특징이 이미지 내 어디에 있든 같은 방식으로 인식된다. 예를 들어, 고양이 귀가 왼쪽 위에 있든 오른쪽 아래에 있든, 동일한 convolution filter로 감지할 수 있다.
- 동일한 필터를 이미지 전체에 공유(weight sharing)하며 적용하기 때문이다.
즉 모델에게 모든 것을 맡길 필요 없이, 우리가 이정도는 해줄게~ 하고 나머지를 모델에게 맡기는 꼴이라 볼 수 있다. 모델이 처음부터 모든 것을 학습하고 예측하는 것이 아니라, 몇 가지 가정들을 미리 설계해준 다음에 나머지 테스크에 대해서만 학습할 수 있도록 해주는 것이기 때문이다.
좋다. 좋은데, 역으로 생각해보면 문제점은 모델이 대상에 대해 깊은 이해가 특별하게 있지 않아도 된다는 뜻이기도 하다.
그러면 한계가 있다. 더 고수준의 이해를 해야 하는 경우, 모델이 자체의 한계에 빠질 수밖에 없다는 뜻이다. 따라서 MAE는 모델의 한계를 끌어올리기 위해, 의도적으로 inductive bias를 제거하였고 이것이 성공을 한 것이다.
그렇게 제거를 한 것이,
- CNN 구조가 아닌 Transformer 구조 사용
- Mask 비율을 75%나 두는 것이 모델이 더 깊은 이해를 하여 성능 개선에 도움이 된다
- Mask를 그냥 두는 것보다 제거하는 것이 모델이 더 깊은 이해를 할 수 있도록 도움을 준다
Conclusion
이 논문이 얼마나 효과적이며 좋은 의미를 내포하고 있는지는 충분히 보았을 것이다.
만약 이 리뷰를 읽어보시는 독자라면 꼭 Inductive bias 부분을 한 번 더 읽어보시기를 권장한다.
'논문 리뷰 > CV' 카테고리의 다른 글
| Vision Transformers Need Registers 논문 리뷰 (2) | 2025.08.15 |
|---|---|
| MAEP 논문 리뷰 (3) | 2025.08.13 |
| YOLO 논문 리뷰 (5) | 2025.08.11 |
| Faster R-CNN 논문 리뷰 (0) | 2025.08.10 |
| R-CNN 논문 리뷰 (3) | 2025.08.09 |