VISION TRANSFORMERS NEED REGISTERS
Introduction
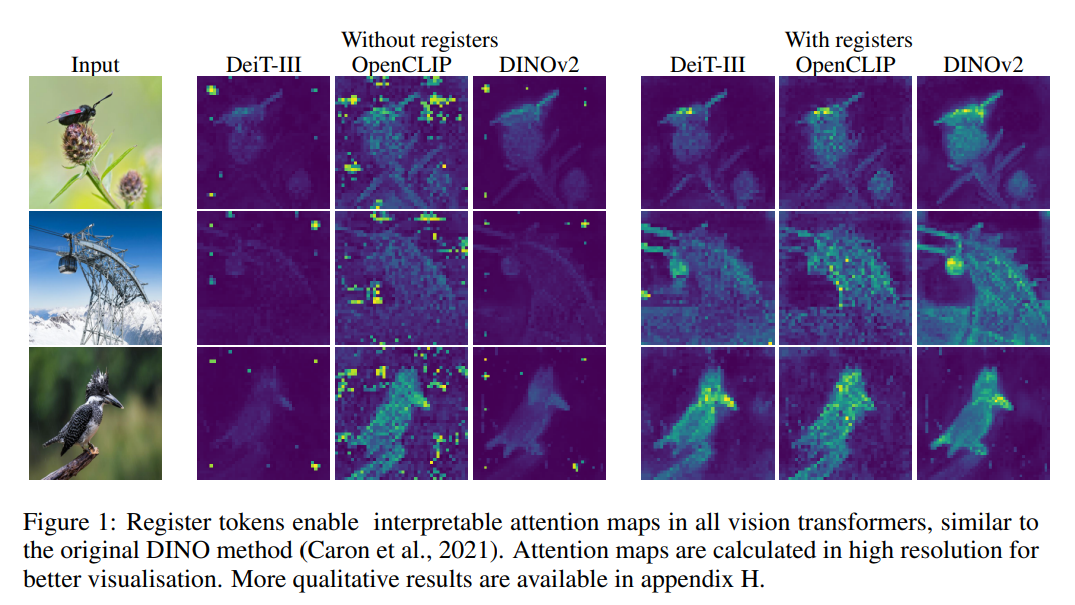
위의 사진에서, DeiT-III 모델이나 DINOv2 모델의 attention map을 보자. OpenCLIP와 다르게 객체의 형태를 뚜렷하게 잡지 못하는 것을 확인할 수 있다. 그것은 둘째 일로 하더라도 전혀 상관도 없어보이는 위치에서 빛이 나는 것을 확인할 수 있다.
무엇이 문제일까?
- 모델의 설명성: 위의 세 모델 전부 CV 분야에서 좋은 성적을 거두는 모델들이다. 그러면 이제 이 모델이 왜 좋은지에 대해서 설명하려고 할 때, OpenCLIP는 사진 속 객체를 잘 탐지한다고 대답할 수 있지만, DeiT-III나 DINOv2는 이러한 대답을 하기 어렵다. 말 그대로 black-box인 것이다.
- Activation: Attention Map을 보면 DeiT-III나 DINOv2는 전혀 알 수 없는 위치에서 attention map이 크게 활성화되어 있는 것을 볼 수 있다. 이는 분명 이미지의 global representation에 관한 영역일 것이지만, 이에 해당하는 패치의 represenation의 norm이 커서 local information을 누를 가능성이 있어보인다.
실제로, DINOv2는 전반적인 성능이 우수함에도 Localization task에서는 성능 저하를 보인다. 본 논문은 이를 문제로 지적하고, Register 토큰([REG])을 추가해 Global과 Local representation의 균형을 맞추고 해석 가능성을 개선하는 방법을 제안한다.
Experiments
본 논문은 실험을 통해서 다음과 같은 사실들을 밝힌다. 우선 outlier와 non-outlier을 구분해주자:
- 토큰 벡터의 norm이나 분포 위치가 다른 토큰들과 비교해 다르거나, attention feature map에서 의미가 없는 위치에 강한 값을 가진 경우를 outlier token이라 한다.
- Non outlier의 경우 attention 상에서 의미 있는 영역에 위치하는 경우를 가리킨다.
Non-Outlier 토큰이 DINOv2 모델에서 특히 그 존재감이 강한데, 다음과 같은 그림에서 확인할 수 있다:

또한 모델의 크기, 레이어 수, 학습 반복 횟수가 증가하다가 어떤 임계치를 넘으면 non-outlier 토큰의 비중이 증가하기도 한다.

Outlier 토큰이 그 자체로만 보면 모델의 성능을 저해할 것처럼 보이지만, 반드시 그런 것은 아니다.

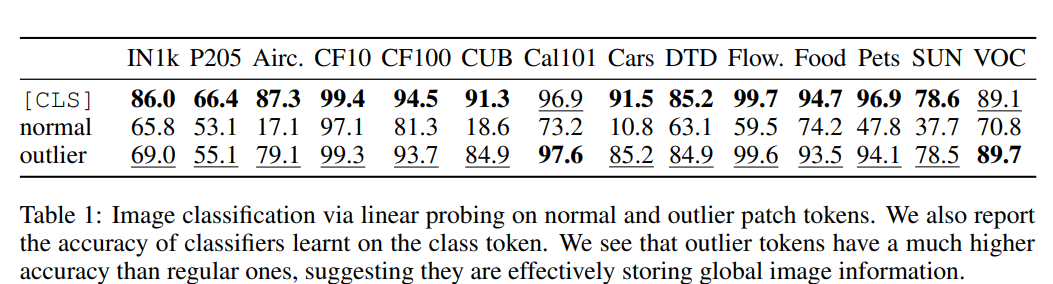
이렇게 outlier 토큰은 locality 성능에 저해하는 요소로 작용하는 것으로 확인되지만, 그럼에도 전역적 정보를 파악하는 것에 있어서는 상당히 우수한 성능을 보이는 것을 확인할 수 있다.
즉 이러한 아웃라이어 비율을 조절하는 것이 특정 테스크 성능 향상으로 귀결될 수 있다는 생각을 할 수 있다. 이를 어떻게 구현하는지, 그리고 구현이 어떤 결과를 일으키는지 확인해보자.
Methods & Results
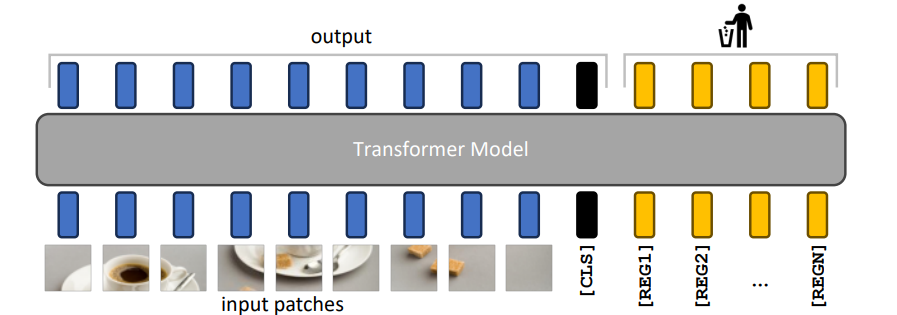
일반적인 ViT구조와 다르게, 아무 의미 없는 register token [REG]을 두면 outlier token의 비율을 획기적으로 즐일 수 있다. [REG] 토큰을 포함하면서 학습한 후, 학습이 완료되면 [REG] 토큰을 단순히 버리기만 하면 된다.
직관적으로 이 방법이 왜 가능한지 생각해보자. [REG] 토큰은 소위 깡통, 즉 의미가 없는 토큰이다. image 데이터가 있는 패치와 다르게 랜덤 값으로 initalize된 토큰이기 때문에, 지역적 정보는 input patches가 위치한 토큰, 전역적 정보는 [REG]토큰에서 학습될 가능성이 높아진다.
즉 전역적 이해를 위한 공간을 마련해주었다고 생각하면 된다. 이전에는 전역적 이해를 할 수 있는 공간이 존재하지 않았기 때문에, 설명 불가능한, 의미가 없는 위치에서 attention이 활성화되었다. 그러나 이번에는 [REG]토큰을 도입하여 학습하는 것이 전역적 이해를 위한 공간을 따로 마련해주어 모델이 실제 input 위치에서 데이터의 local 특성에 대해서 학습할 수 있는 것이다.
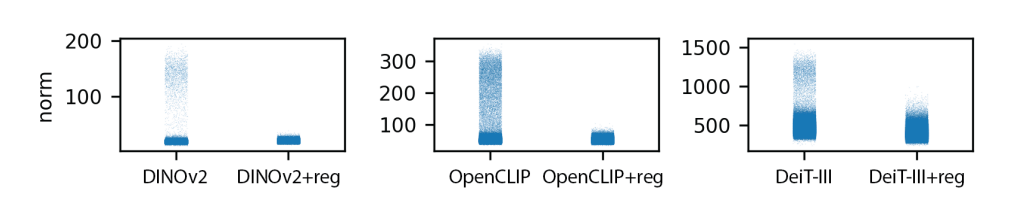
우선 실제로 Norm의 분포가 안정화된 것을 실험 결과를 통해서 확인할 수 있다.
이제 중요한 점은 다음과 같다. (1) 기존 input token에서 지역적 정보만을 전담하여 학습할 수 있게 했기 때문에 지역적 정보에 연관된 테스크에 대해서는 성능이 증가해야만 한다. (2) 새로운 학습 방법은 기존 성능을 최대한 해치지 않는 선에서 진행되어야 한다. 즉 만약 지역적 정보에 관한 능력이 증가했더라도, 이 증가는 전역적 정보에 대한 능력을 잃지 않는 것을 전제하여야 그 정당성이 더욱 유지된다.
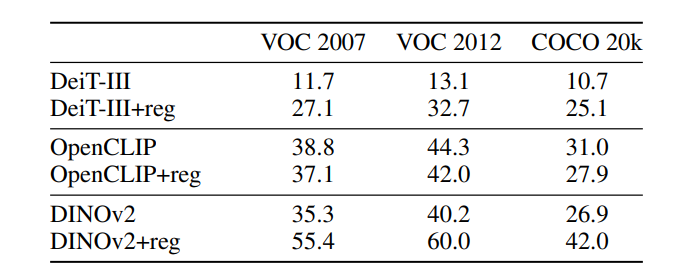
지역적 정보에 관련된 테스크 성능이 늘어남을 확인할 수 있다. 논문은 다만 OpenCLIP에서 성능이 줄어든 것은, CLIP은 이미 지역적 정보를 학습함에 있어서 outlier token의 영향이 크지 않았기 때문이라 설명한다.

완벽하다. 전역적 정보에 관한 테스크 성능은 떨어지지 않았으며, 오히려 소폭 오른 것을 확인할 수 있다.
결론적으로, 본 논문이 제시하는 방법론은 그 목적을 충분히 달성할 수 있음을 보여준다고 말할 수 있을 것이다.
Conclusion
내 소감을 쓰고자 한다. 모델이 서로 다른 정보를 같은 공간이 아닌 다른 공간에서 학습하여 혼재되지 않도록 하는 방법이 있음을 배웠으며, 상당히 놀라운 것 같다.
이것으로 무언가 영감이 떠오르는데 나중에 아이디어를 구체화해보고자 한다!
'논문 리뷰 > CV' 카테고리의 다른 글
| DINO 논문 리뷰 (2) | 2025.08.17 |
|---|---|
| BYOL 논문 리뷰 (2) | 2025.08.17 |
| MAEP 논문 리뷰 (3) | 2025.08.13 |
| MAE 논문 리뷰 (feat: Inductive Bias) (2) | 2025.08.12 |
| YOLO 논문 리뷰 (5) | 2025.08.11 |