You Only Look Once: Unified, Real-Time Object Detection
Summary
본 논문은 R-CNN 계열 모델들과 다르게 객체 검출에 대한 새로운 접근방식을 제안한다. R-CNN 기반 모델들은 객체 탐지와 객체 인식을 따로 나누어 추론하고 학습되는, multi-task 문제이지만 YOLO는 해당 문제를 하나의 회귀(regression) 문제로 재정의한다.
따라서 객체 탐지 파이프라인이 하나의 신경망에서 구성되어 있기 때문에 기존의 객체 탐지보다 더 빠른 성능(155 FPS)을 달성할 수 있다.
Method
Unified Detection
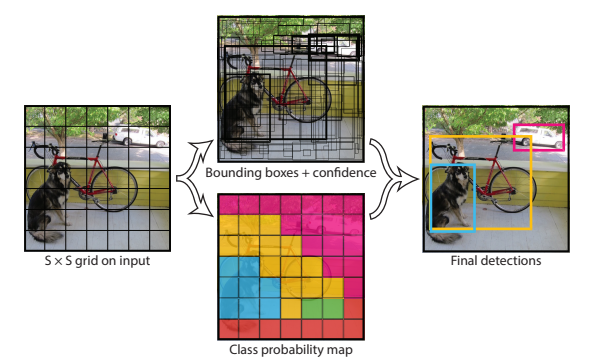
Detection을 위한 과정을 알아보자.
- Input image가 모델에 들어오면 $S × S$ 그리드로 쪼개어진 후, 각 그리드에서는 $B$개의 학습된 bounding box를 가져서 객체를 탐지하며 confidence score를 낸다( [x, y, w, h, confidence] 산출). Confidence score은 bounding box가 얼마나 객체를 포함하고 있는지에 대한 값(IoU)과 그것이 학습된 객체 중 하나임을 나타내는 확률 값으로 이루어져 있다. 즉, $\Pr{(\text{Object})} * \text{IoU}^{\text{truth}}_{\text{pred}}$ 이다.
- 각 그리드는 또한 Object가 존재할 때 그것이 어떤 클래스에 속하는지에 대한 확률, $\Pr{(\text{Class}_i | \text{Object})}$를 예측한다. 각 클래스에 대한 확률값은 그리드 셀 단위로 하나만 예측된다. 즉, $B$개의 박스가 존재하더라도 클래스 확률은 동일하게 공유된다.
- $\Pr{(\text{Object})} * \text{IoU}^{\text{truth}}_{\text{pred}} * \Pr{(\text{Class}_i | \text{Object})}$의 값은 $\Pr{(\text{Class}_i)} * \text{IoU}^{\text{truth}}_{\text{pred}}$가 되고, 이는 각 bounding box마다 class-specific한 confidence를 제공한다.
- 이렇게 만들어진 $S × S × B$ 만큼의 bounding box에 대해서 NMS를 통해서 최종 박스들을 선택한다.
Network Design

논문을 참고해주면 좋을 것 같다. 여기서 왜 1 × 1 kernel을 두는지에 대해서 조금 더 일반적인 설명을 해보겠다. 1 × 1 커널을 두는 것의 장점은 다음과 같다:
- 차원 축소: 1 × 1 conv는 공간 정보는 그대로 두고, 채널 방향의 계산만 한다. 예를 들어서 $H × W × 1024$인 경우 1 × 1 kernel의 개수를 256개로 두면, conv를 거치고 나서 $H × W × 256$으로 채널이 줄어든다. 압축으로 인한 연산 과정 개선을 달성할 수 있다.
- 채널 간 결합: 1 × 1 conv는 단순한 압축이 아니라, 각 채널별로 독립적으로 있던 정보를 섞어서 새로운 feature 표현을 만들어 더욱 표현을 풍부하게 만들 수 있다.
Training
중요한 것은 Loss라 생각하기에, 이 부분을 중점적으로 다루겠다.
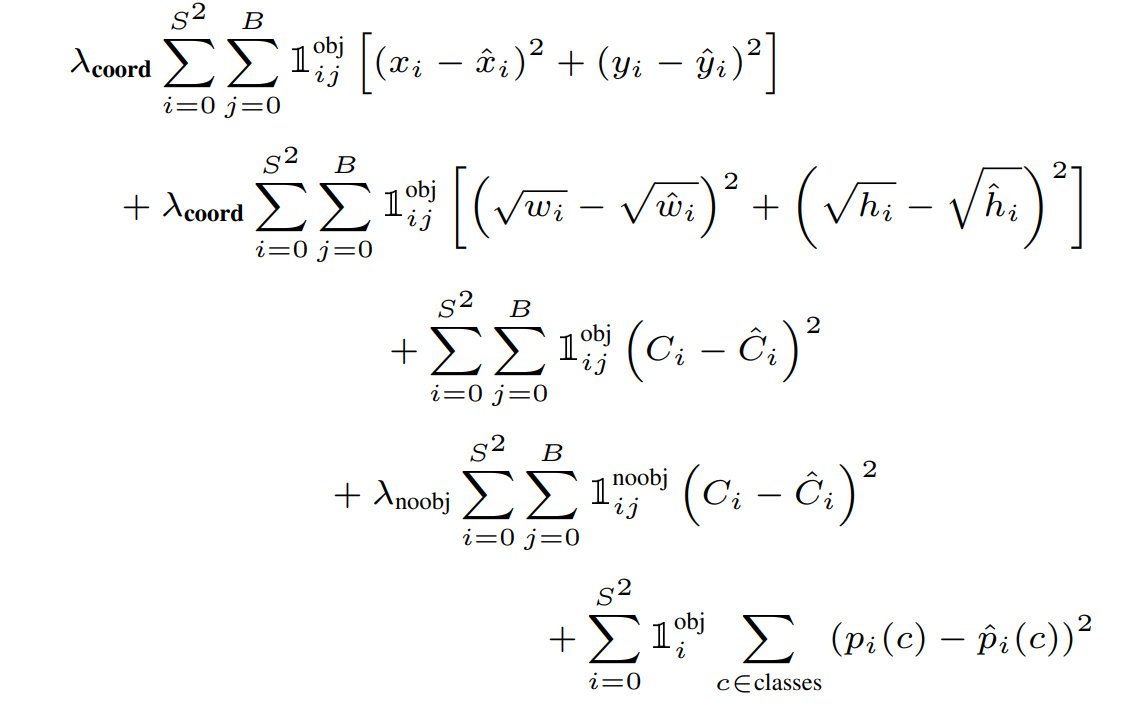
여기서 $\mathbb{1}$은 indicator function이다.
- Object가 존재하는 그리드 셀 i의 bounding box predictor j에 대해서, 좌표 x와 y의 loss 계산. 좌표값 간 차이를 계산
- Object가 존재하는 그리드 셀 i의 bounding box predictor j에 대해서, 너비 w와 높이 h에 대한 loss 계산. 큰 박스에서의 오차는 작은 박스에서의 오차보다 중요성이 낮아야 하기 때문에, square root를 통해서 작은 박스가 더 많은 패널티를 받도록 계산된다.
- Object가 존재하는($C_i=1$) 그리드 셀 i의 bounding box predictor j에 대해서, confidence와 비교하여 loss 계산
- Object가 존재하지 않는 ($C_i=0$) 그리드 셀 i의 bounding box predictor j에 대해서, confidence와 비교하여 loss 계산. False Positive에 더욱 많은 패널티를 줄 수 있도록 $\lambda$ 계수가 존재함
- Object가 존재하는 그리드 셀 i에서 실제 클래스와 예측된 클래스의 확률 간 loss 계산
SSE를 쓰는 것은 구현도 쉽고 미분도 간단하여 안정적으로 동작한다는 단점이 있지만, YOLO의 테스크에서는 mAP를 늘리고 싶은 것과 정확하게 일치하지 않는다는 문제점이 있다.
또한, 한 이미지에서 대부분의 grid cell은 객체가 없기에, Loss 계산의 경우 confidence를 전부 0으로 수렴하게 모델이 안정될 수 있다(보통 클래스 불균형이라는 문제를 이야기한다).
따라서 YOLO에서는 Loss 항에서 No-object에 대한 영향도를 줄여 positive cell의 gradient가 충분히 반영되도록 한다. 또한 Localization에 대해서도 가중치를 부여하여 위치 정확도를 더욱 강조할 수 있다.
Experiments
정확도에 대한 논의보다는 real-time에 대한 논의를 하는 것이 맞다. 준수한 성능과 빠른 추론이 YOLO의 장점이기 때문이다.
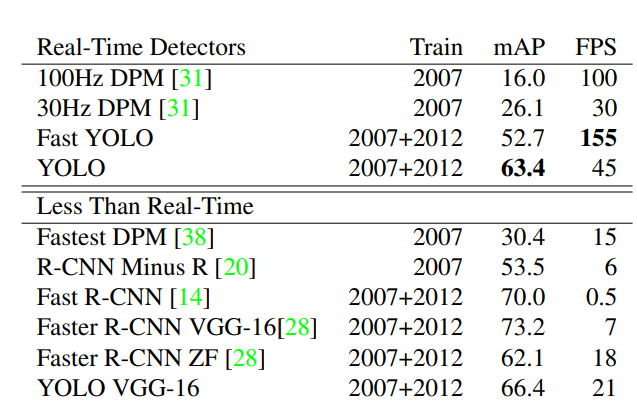
Faster R-CNN의 mAP에 비해서는 다소 떨어진 모습을 보이기는 하지만, 그럼에도 FPS가 최대 20배 이상 늘어날 수 있다는 것이 특징이다.
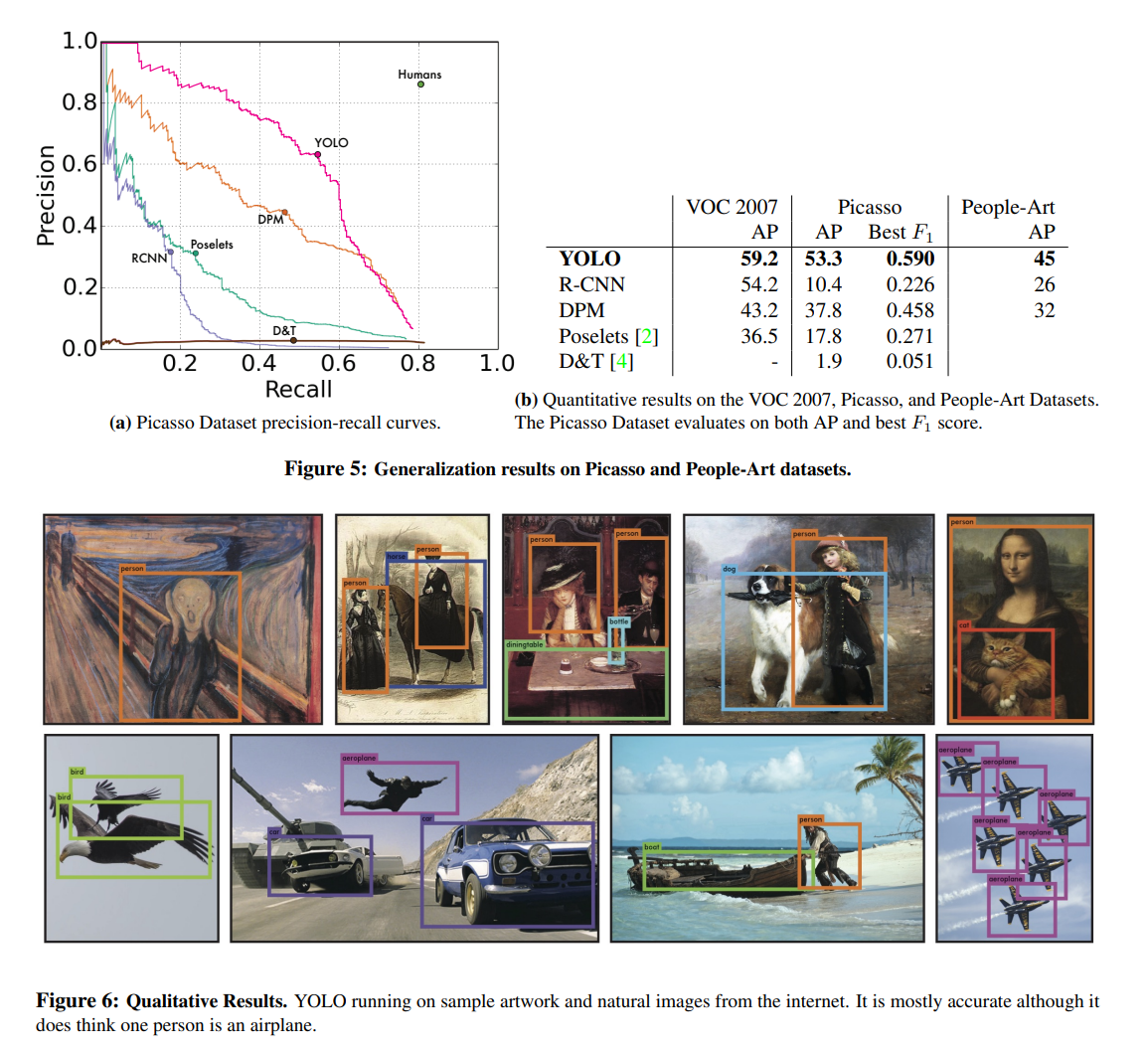
또한 이미지 전체를 보며 표현에 대하여 학습하였기 때문에, artwork에서의 사람 탐지 성능 향상 등 더 일반화 자체에 대해서는 더 좋은 성과를 낼 수 있다는 것이 이 모델의 특징이다.
다음 번에는 이 YOLO 모델을 어떻게 더욱 성능을 끌어올릴 수 있는지를 다루는 논문들에 대해 리뷰하도록 하겠다! 대충하는 감이 있어 반성 중 ㅠㅠ
'논문 리뷰 > CV' 카테고리의 다른 글
| MAEP 논문 리뷰 (3) | 2025.08.13 |
|---|---|
| MAE 논문 리뷰 (feat: Inductive Bias) (2) | 2025.08.12 |
| Faster R-CNN 논문 리뷰 (0) | 2025.08.10 |
| R-CNN 논문 리뷰 (3) | 2025.08.09 |
| CLIP 논문 리뷰 (1) | 2025.08.05 |