Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Summary
본 논문은 기존의 Fast R-CNN의 문제점인
- Selective Search 알고리즘을 통한 region proposal 알고리즘의 latency
- Region proposal을 통한 detection을 제외한 end-to-end 학습은 가능하지만, detection 학습 및 추론 과정을 end-to-end로 수행하지 못하는 단점을 해결하며 속도와 모델의 완성도를 끌어올렸다.
Preliminary
Fast R-CNN
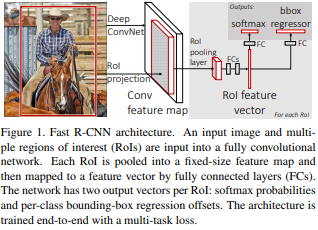
Selective Search를 통해 region proposal을 생성한 후, 원본 이미지를 Conv Network에 입력하여 Feature map을 얻는다. 생성된 RoI는 Feature map 상에 투영(project)되어 RoI Pooling을 거쳐 고정 크기의 feature vector로 변환된다.
이 feature vector는 FCNN을 통해 classification이 수행되며, 동시에 bbox regression을 통해 Bounding box의 위치와 크기가 조정되도록 학습된다.

이 방법은 기존의 R-CNN에서 제시하는 SVM을 이용한 분류를 제거함으로써 추론 시간 및 학습 과정에서의 복잡성을 줄였지만, 여전히 Region proposal 자체는 다른 파이프라인을 사용하여, 아직 fast라 하기에는 무리인 감이 있었다.
Method
Faster R-CNN은 Region Proposal Network(RPN)를 도입하여, 기존 Fast R-CNN에서 사용하던 Selective Search와 같은 외부 region proposal 알고리즘의 연산 비용과 병목 문제를 해결하였다. 이를 통해 region proposal 단계를 신경망 내에 통합함으로써, 속도와 정확도를 동시에 향상시킬 수 있었다.
네트워크 구조부터 우선 보자:
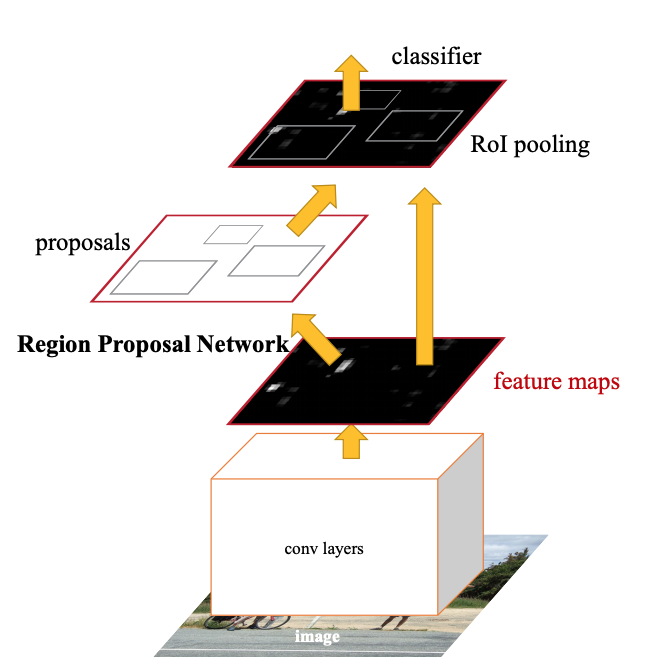
- 원본 이미지가 pretrain된 CNN 모델(논문에서는 VGG-16)에 입력되어 feature map이 추출된다.
- Feature map은 RPN에 전달되어 적절한 region proposal들을 만든다.
- Region proposals와 feature map을 통해서 RoI pooling을 수행하여 고정된 크기의 feature map을 얻는다.
- 이후 fully connected layer을 통과하여, 객체 인식과 bounding box regression을 동시에 수행한다.
Region Proposal Network

Backbone CNN의 convolution feature map의 크기는 $H × W × C$이고, 일반적으로 $C=512$이다. 이 feature map에 대해서 채널 수는 유지한 채로 3 × 3 convolution을 진행하고, 이후 1 × 1 convolution을 통해 classification과 bounding box를 위한 브랜치를 따로 만든다.
이 때 1 × 1 convolution을 통해서,
- Bounding box regression: 1 × 1 convolution → 출력 채널 수 = 4k (각 앵커마다 Δx, Δy, Δw, Δh 오프셋)
- Classification: × 1 convolution → 출력 채널 수 = 2k (객체 / background 이진 분류)
로 만든다고 하는데, 이때 k가 어떤 것을 의미하는지 알아보자. 본 논문에서 bounding box를 CNN에 end-to-end로 연결시키는 데에 핵심이 되는 anchor이다.
Anchor
만들어진 feature map의 좌표를 중심으로 배치하는 참조 박스다. 각 좌표마다 {박스 크기 (스케일) } × {박스 비율 (종횡비)}만큼의 참조 박스를 둘 수 있다. 즉 H' × W' 크기의 feature map가 있다면, Anchor의 개수는 H' × W' × {박스 크기 (스케일)} × {박스 비율 (종횡비)}가 되는 것이다.
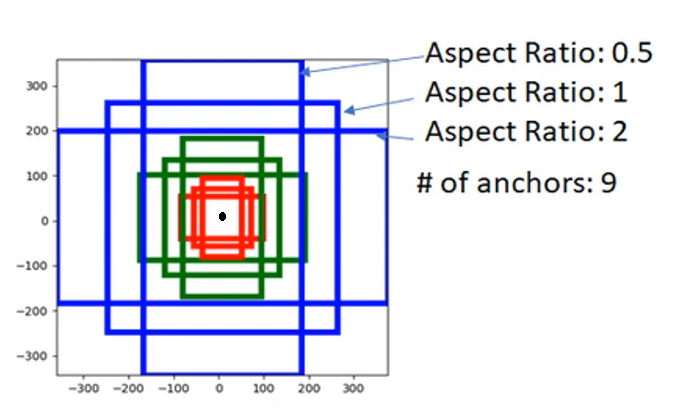
본 논문에서는 기본 설정으로 스케일 {128², 256², 512²}, 종횡비 {1:1, 1:2, 2:1}, 즉 k=9개의 앵커를 각 좌표마다 두게 되는 것이다. 이 앵커는 위치에 따라 변하지 않으며(translation invariant), 단일 feature map에서 다양한 크기 및 비율을 처리할 수 있다(multi-scale)는 장점이 있다.
라벨 할당 규칙

이렇게 만들어진 Anchor를 전부 다 사용하는 것은 아니다. 우선 GT(Ground Truth) 박스와의 IoU(Intersection of Union)을 계산하면:
- Positive: IoU ≥ 0.7 인 앵커, 각 GT박스와 IoU가 가장 높은 앵커 (객체로 학습하기 위해)
- Negative: IoU ≤ 0.3 인 앵커 (배경으로 학습하기 위해)
- Ignore: etc. 학습 안정성을 위해 제거
이렇게 만들어진 Positive/Negative 앵커는 RPN의 classification 및 regression branch에 전달된다. Classification은 Positive·Negative 모두 사용되지만, Regression은 Positive 앵커에 대해서만 손실이 계산된다. Ignore로 분류된 앵커는 두 가지 손실 계산 모두에서 제외된다.
NMS (Non-Maximum Supression)
객체 탐지를 하면 한 객체에 대해서 IoU가 positive로 만들어지는 박스가 여러 개 나온다. 이것을 그냥 두면 중복 탐지도 되어 mAP가 떨어지며, 사람이 보기에도 지저분해지고, 필요하지도 않은 학습을 여러 번 하게 된다.
따라서 겹치는 박스들 중에서, 가장 좋은 박스 하나만 남기고 나머지를 제거하는 후처리를 진행하면 되는 것이다!
RoI Pooling
Recap: Pooling
Pooling은 CNN에서 feature map의 크기를 줄이거나(downsampling) 고정 크기의 출력을 만드는 연산이다. 목적으로는 연산량 절감, 작은 이동 및 변형에 대한 불변성 부여, fully connected layer의 입력 차원 고정이 있다.

RoI Pooling
RPN에서 뽑은 proposal box는 앞서 설명했듯이 크기가 여러가지이며, 실제로 Bounding box regression을 거치게 되면 크기가 완전히 제각각이 된다. 이렇게 되면 FC layer에 넣기에는 크기가 고정되지 않아 문제가 생긴다. 따라서 RoI pooling은 다음과 같은 과정을 거치는데:
- Proposal 좌표를 feature map 크기에 맞게 매핑
- Proposal 영역을 H1 × W1 그리드로 변환 (논문에서는 7 × 7)
- 각 그리드에 대해서 Max pooling 수행
이렇게 되면 모든 RoI가 H1 × W1 × C 크기로 통일되어 FC layer에 입력으로 넣어줄 수 있다.
Multi Task Loss
RPN Loss
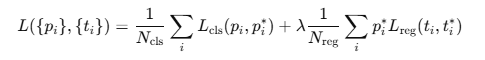
첫 번째 항의 경우 Positive(객체), Negative(배경) 모든 앵커에 대해서 loss가 계산되며, $p$은 배경인지, 배경이 아닌지에 대한 softmax 확률값이다. 따라서 $L_{cls}$는 cross-entropy loss로 계산된다.
두 번째 항의 경우 Bbox regression에 대한 loss를 계산하는 것이며, 이때 이진 값인 $p^{*}$이 1일 때, 즉 객체일 때에만 loss를 계산하게 된다.
Detection Head Loss
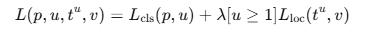
이번에는 실제 클레스에 대한 예측을 하게 된다. 신기한 점은 bbox regression loss를 한 번 더 계산한다는 것이다.
RPN loss에서 처음 만들어진 Anchor는 단순한 박스이기 때문에, 실제 객체 위치와 오차가 크다. 따라서 RPN loss에서는 오차를 빠르게 줄여서 그럴듯한 proposal으로 만드는 것이 중요하다고 한다. 이때는 객체를 놓치지 않아야 하니, Recall이 중요하겠다.
반면 Detection head loss에서는 더 정밀한 객체 위치를 찾는 것이 중요하다. 이번에는 precision이 중요하게 되겠다.
Alternating vs Joint Training

논문에서는 RPN 학습, Detection Head 학습... 을 반복하여 하나의 공유된 convolution network를 RPN/Det가 함께 쓰는 통합 네트워크가 완성된다.
현재는 이 loss를 합쳐서, $L_{total} = L_{RPN} + L_{Det}$로 동시에 학습된다고 한다.
Inference
추론 단계는 다음과 같다:
- Image input 후 feature map 변환 → 학습된 RPN에서 각 anchor box마다 IoU/NMS 적용 후 proposal 추출
- RoI pooling → Detection head
- 클래스별로 중복 박스가 또 생기기 때문에, NMS 한 번 더 적용 후 최종 출력
Results
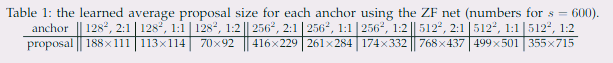
훈련 후 실제로 만들어진 anchor들의 평균 shape이다. 대체로 비율이 그대로 잘 유지된 것을 확인할 수 있다.
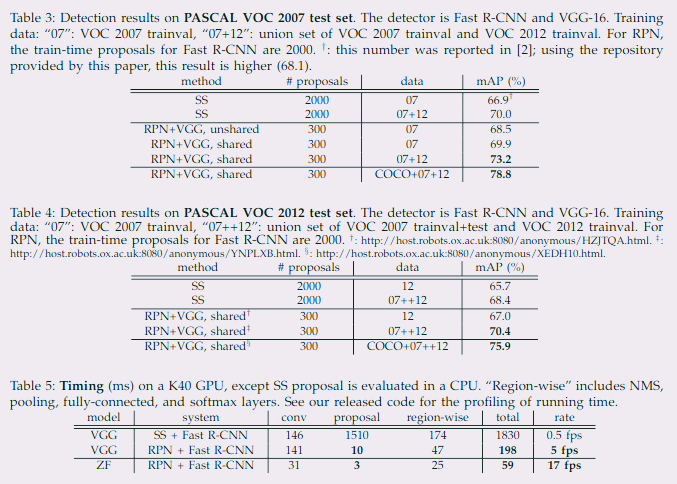
Faster R-CNN이 더 적은 proposal로도 높은 mAP를 유지하며, Selective Search 대비 수십 배 빠른 추론 속도를 달성한다는 것을 확인할 수 있다.

Faster R-CNN은 앵커 설정과 λ 값에 대해 민감도가 낮고, 기본값 근처에서 대부분 안정적인 성능을 낸다는 것을 확인할 수 있다.

속도의 주요 병목 원인이었던 Selective Search 알고리즘을 해결하여 정말 빨라진 것을 확인할 수 있다.
지금까지 본 논문 중에서 구조 및 학습 방법을 이해하는 것이 가장 복잡하고 까다로웠던 것 같아 체력적으로(?) 힘들었다. 주말이기도 하고... 그래서 이쯤에서 마무리하고 다음에는 YOLO로 돌아오도록 하겠다!
REFERENCE
https://www.youtube.com/watch?v=kcPAGIgBGRs
'논문 리뷰 > CV' 카테고리의 다른 글
| MAE 논문 리뷰 (feat: Inductive Bias) (2) | 2025.08.12 |
|---|---|
| YOLO 논문 리뷰 (5) | 2025.08.11 |
| R-CNN 논문 리뷰 (3) | 2025.08.09 |
| CLIP 논문 리뷰 (1) | 2025.08.05 |
| EfficientNet 논문 리뷰 (3) | 2025.08.04 |