Learning Transferable Visual Models From Natural Language Supervision
Summary & Key Contribution
CLIP는 기존의 이미지 분류 모델이 고정된 클래스 라벨을 예측하도록 훈련되는 것의 한계를 극복하고자,
(이미지, 텍스트) 쌍의 데이터를 활용해 학습된 범용 Vision-Language 모델이다.
- Text Embedding와 Image Embedding을 Contrastive Learning을 통해 정렬시키며 Modality를 연결시키는 방법을 제시하였으며,
- LLM 훈련에 사용되는 엄청난 크기의 데이터셋을 비전 모델의 표현 학습에 사용하는 방법을 제시하였고,
- 이렇게 학습된 CLIP은 Zero-Shot Transfer Learning에 적합함을 보여주었다.
Approach
1. Dataset
이전의 연구들은 주로 세 가지 데이터셋을 사용하였는데,
- MS-COCO
- Visual Genome
- YFCC100M
위의 데이터들은 학습을 위한 양질의 데이터에 있어서는 그 숫자가 적었기 때문에 학습에 있어서 제한이 있었다.
따라서, 본 논문은 새로운 데이터셋을 제시하는데, 이는 (image, text)페어로 인터넷에서 수집한 데이터로 구성되었다. 이렇게 새로 만들어진 데이터를, WIT (WebImageText)라 부른다.
2. Training
우선 기존의 SOTA 모델들은 매우 큰 연산량을 가지는 것에 비해서, ImageNet의 경우처럼 단 1000개의 클래스만 예측하여 일반화된 모델이라 부르기에는 다소 부족한 면이 있었다.
또한 Transformer을 이용한 이미지에 대한 텍스트 생성은 계산량이 많고 느렸기 때문에, 오히려 더 많은 계산량을 요구하는 상황이었다.
따라서 "이 이미지와 어떤 문장이 짝이 맞는가" 와 같이, 문장 생성이 아닌 문장 선택 문제로 테스크를 바꾸어,
bag-of-words 입력을 사용하였다.

이에 더해서, 이미지 → 텍스트 예측이 아닌 이미지와 텍스트의 표현을 학습하는, Contrastive objective을 이용한 학습 방법으로 바꾸어 학습 성능을 늘릴 수 있었다.
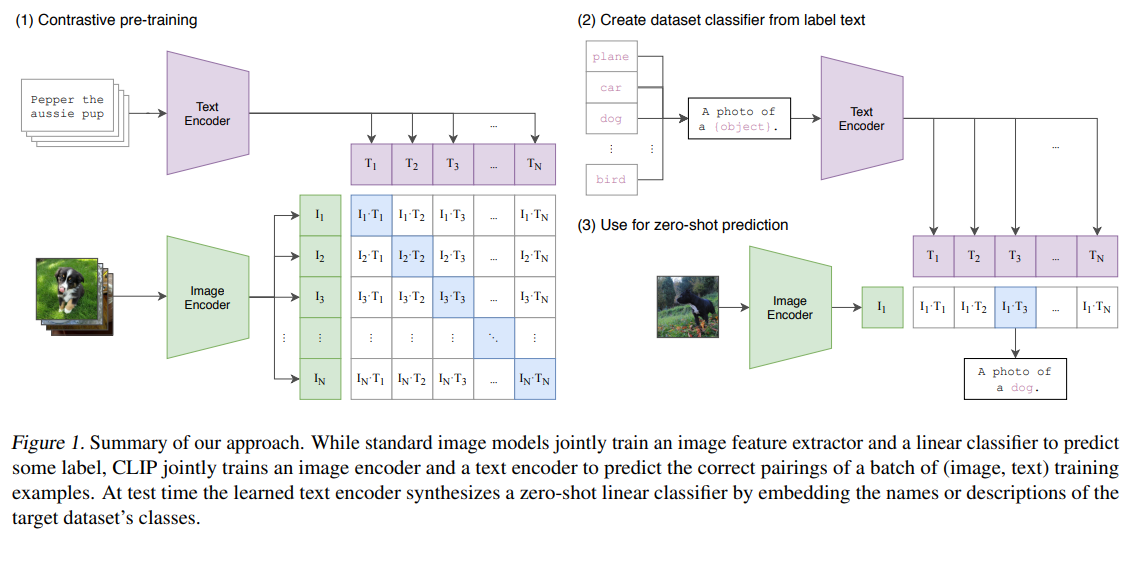
CLIP는 다음과 같이 학습된다:
- 한 배치에 N개의 (image, text) 쌍이 있고,
N * N개의 가능한 조합 중 진짜 쌍(positive)만 맞추도록(daigonal) 학습하며, 남은N^2 - N개의 데이터 쌍은 Negative pair로 간주되어 학습되었다.
따라서 문장 생성을 하거나 문장을 예측하는 것보다는, 문장 짝을 맞추는 것만으로도 표현 학습이 충분이 된다는 것을 확인하고 나서, 본 논문의 2.4는 Transformer Encoder을 텍스트 모델로 사용하여 훈련한다.
이 때 Transformer 모델은 텍스트를 요청하는 훈련 없이, Masked Attention → 마지막 [EOS] 벡터 하나만 추출함으로써 문장에 대한 임베딩을 생성하고, 이를 Contrastive Learning을 통해서 학습하는 절차를 가졌다.
요약
문제⇢ 이미지→문장 생성(Transformer LM)은 토큰 softmax 때문에 연산이 과도하고 느렸다.
해결 단계
1) BoW Prediction → 단어 집합만 예측해도 여전히 비효율
2) BoW Contrastive → “이 이미지와 이 BoW 문장이 짝인가?” 대조 학습으로 4× 효율 상승
3) 최종: Transformer Text Encoder + Contrastive
- BPE(49 K) → Masked-Self-Attention → [EOS] 벡터 (512d)
- 이미지·텍스트 임베딩을 같은 공간에 정렬, Temperature τ는 학습 중 최적화
3. Training
Resnet 5개 모델, ViT 3개 모델을 선정하여 training을 진행하였다.
아래는 CLIP의 Implementation Code다:

Experiments
1. Transfer Learning
Transfer Learning으로 Linear Evaluation(Wx + b)하였을 때에도 성능이 SOTA보다 좋은 것을 확인할 수 있다:

2. Zero-Shot Learning

Zero-Shot Learning은, 모델이 학습 과정에서 한 번도 본 적 없는 클래스 및 테스크에 대해서, 추가 패러미터 업데이트 없이 즉시 추론을 할 수 있는 능력을 의미한다. 이러한 능력이 중요한 이유는:
- 새로운 클래스를 추가할 때마다 대규모 라벨링을 할 필요가 없으며,
- 모델이 사전에 고정된 클래스 셋을 벗어나 현실 세계의 다양한 개념을 유연하게 처리하여 일반화의 능력을 갖출 수 있다.
본 논문에서는 zero-shot 분류 성능을 높이기 위해 다음과 같은 기법을 적용한다:
(1). Prompt Engineering
- 단순히
"cat"처럼 class name만 넣는 것보다,"A photo of a cat."처럼 문장 형태로 텍스트를 구성하는 것이 성능이 더 좋다 - 이렇게
“A photo of a {label}."로 넣으면서 예측하는 경우 ImageNet 성능을 1.3% 높일 수 있다.
(2). Prompt Ensembling
- 서로 다른 프롬프트들(예: "A photo of a big {label}", "A photo of a small {label}")을 사용해 여러 개의 텍스트 임베딩을 생성하고 평균을 내어 정확도를 3.5% 증가시킬 수 있었다.
(3). Context-aware Labeling
- 단일 단어(label)가 가진 다의성 문제를 피하기 위해 문맥을 제공하여, disambiguation을 확보했다.

Zero-Shot CLIP이 few shot으로 학습한 모델들과 비슷하거나 더 나은 성능을 보여주는 것을 볼 수 있다.
3. Robustness to natural distribution shift
Vision Model의 한계로 Robustness가 현저하게 떨어진다는 점이다. 즉 학습한 데이터셋에서 노이즈가 조금 섞여 들어간다거나, 텍츠쳐가 변한다면 성능이 크게 하락한다.
따라서 Vision Model의 우수성을 확보하기 위해서는 일반화 성능과 강건함(Robustness)까지 갖추어야 한다.

이렇게 CLIP가 Robustness에 강하다는 것을 알 수 있다.
Conclusion
CLIP은 “웹 규모 이미지-텍스트 데이터” × “대조 학습”이라는 단순한 조합만으로도
- 범용 시각 표현
- 자연어 기반 제로샷 추론
- 분포 이동에 대한 상대적 강건성 을 모두 달성할 수 있음을 입증했다.
CLIP이 보여준 범용 시각 표현·언어 기반 제로샷 추론·분포 이동 강건성은 분명 큰 진전이지만, 앞서 정리한 여섯 가지 한계는 실제 서비스 / 연구 적용 단계에서 반드시 고려해야 한다.
- 제로샷 한계 → Prompt-tuning·Adapter·LoRA와 같은 경량 미세조정 기법으로 보완 가능
- 대규모 데이터 의존 → 도메인 특화 소규모 데이터에 knowledge distillation·active learning을 적용해 데이터 요구량을 낮추는 연구 필요
- 높은 계산 비용 → 모델 압축(양자화·지식 증류)과 효율적 샘플링 전략이 필수
- 특정 도메인 일반화 어려움 → 메타러닝·도메인 어댑테이션 기법과의 결합이 유망
- 데이터 편향 → Debiasing dataset curation·Fairness-aware fine-tuning 단계 도입이 필요
- 복잡·추상 태스크 한계 → CLIP을 기반 피처로 삼고, 상위에 Reasoning 모듈(LLM, Graph-RAG 등)을 쌓는 하이브리드 아키텍처가 대안
'논문 리뷰 > CV' 카테고리의 다른 글
| YOLO 논문 리뷰 (5) | 2025.08.11 |
|---|---|
| Faster R-CNN 논문 리뷰 (0) | 2025.08.10 |
| R-CNN 논문 리뷰 (3) | 2025.08.09 |
| EfficientNet 논문 리뷰 (3) | 2025.08.04 |
| ViT 논문 리뷰 (1) | 2025.08.01 |