EXPLORATION BY RANDOM NETWORK DISTILLATION
Intro
Epsilon-greedy나 Energy-base stochastic policy는 아무튼간에 탐험을 잘 하도록 설계된 것이기는 하지만, 그 자체로 너무나도 한계가 많다. 이전 포스트에서도 언급했듯이, 어딘가로 탐험을 쭉 해봐야 하는 상황인 경우 앞서 언급된 방법은 너무나도 비효율적이다.
Suton & Barto 초반부에서 UCB, Upper Confidence Bound를 통해서 이러한 문제를 해결할 수 있다는 것을 배웠다.
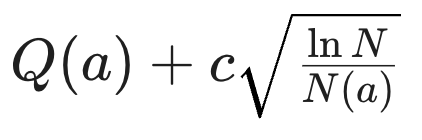
즉 하지 않은 행동에 대한 추가 보너스를 제공하여 정책이 자연스럽게 가보지 않은 상태에 대해서 더 좋은 것이라고 간주하게 하는 것이다. 그러나 이 방법은 Deep RL에서 사실상 불가능하다. 왜냐하면 단순히 discrete space를 가정하더라도 space가 너무 크다면 그러한 Q + 보너스를 저장하는 것이 어려우며, continuous로 가면 카운트 자체에 대한 기준이 모호해지는 결과가 나오기 때문이다.
그래서 사실 나온 것이 parameter space noise라는 것이고, 일관적으로 탐험을 쭉 밀고 나가는 힘이 생기기 때문에 숨겨진 보상을 찾게 될 수 있는 것이다. 이 방법은 문제가 없을까?
사실 쭉 밀고 나가는 것이 장점이지, 아직 이 방법은 space가 continuous한 경우에는 여전히 문제가 많다. 눈을 가리고 탐험을 시키는 것인데 보상을 어떻게든 받기만 하면 성공이라고 간주하기 때문이다. 이 방법은 어디까지나 선택할 수 있는 경우의 수가 작을 때에 유리하지, 선택의 경우의 수가 너무 많으면 "보상을 얻는다" 자체도 불가능에 가깝기 때문이다.
그래서 다시 돌아와서, UCB를 어떻게든 써야 하는 상황이다. 따라서 이 논문의 핵심은, continuous space에서 어떻게 UCB의 아이디어를 활용하냐는 것이다!
(논문이 발상의 전환이기에, 이번 리뷰는 구체적인 수식을 최대한 두지 않고 아이디어 위주로 설명하도록 하겠다.)
Method
Image Classification 모델을 하나 생각해보자. 이 모델이 많이 본 데이터에 대해서는 잘 맞출 것이기 때문에 loss가 낮을 것이고, 보지 못한 데이터일 수록 loss는 높아질 것이다. 그렇다면 탐험의 입장에서 보자. Loss가 작다는 것은 그만큼 모델이 많이 봤다는 것, 즉 많이 경험해본 state라는 결론이 나올 것이다. 반면 loss가 크다면 모델이 보지 않은 데이터일 가능성이 높으니, 해당 state는 경험을 거의 하지 못한 state임을 알 수 있다.
그대로 UCB의 아이디어 -- 적은 탐험을 한 경우 더 많은 보너스를 준다는 것과 일치하게 된다! 그러나 이런 궁금증이 들 것이다.
State에 대한 label이 있어야 모델이 훈련하여 예측을 한다/못한다가 있을 것이다. 그런데 애초에 그 state 자체의 라벨링이 말이 안되기 때문에 UCB를 사용하지 못하는 것이 아닌가?
본 논문은 Random initalized된 모델이 정답 target을 주는 신박한 방법으로 그 문제를 해결한다. 그다음에 해당 모델의 아웃풋을 predictor 모델이 예측하는 것으로 탐험이 얼마나 되었는지에 관한 지표를 만드는 것이다! 필자는 이 내용을 읽으면서, 어 그렇게 아무렇게나 초기화된 랜덤 네트워크를 타깃으로 제공해도 괜찮은가? 비슷한 인풋에 대해서 일관적이지 않은 아웃풋을 내뱉는다면, Predictor가 학습을 통해 일반화(Generalization)를 할 수 없지 않을까? 하는 의문 말이다. 만약 타깃 값이 뒤죽박죽이라면, Predictor는 학습 자체가 불가능할 것이고 모든 State에서 Loss가 높게 나올 것이기 때문이다. 하지만 결론부터 말하자면 "전혀 문제없다. 오히려 랜덤 네트워크가 '신경망'이라는 점이 핵심이다."
여기에는 두 가지 중요한 포인트가 숨어 있다.
첫째, 타깃은 '움직이는 과녁'이 아니다.
타깃 네트워크는 초기에 랜덤하게 생성되지만, 이후 가중치(Weight)가 고정된다. 즉, 결정론적(Deterministic)인 함수다. 아무리 엉뚱한 값을 뱉더라도, 똑같은 입력 $x$가 들어오면 언제나 똑같은 출력 $y$를 뱉는다. 정답지가 변하지 않으므로 Predictor 모델은 충분히 이 매핑 관계를 학습할 수 있다.
둘째, 이것이 가장 중요한데, 랜덤 네트워크도 '유사성(Locality)'을 보존한다.
논문에서 사용하는 타깃 모델은 CNN(합성곱 신경망) 구조를 가진다. CNN은 태생적으로 입력 이미지가 비슷하면 출력 특징(Feature)도 비슷하게 나오는 연속성을 가진다. 만약 타깃 함수로 '해시 함수(Hash Function)'를 썼다면 어땠을까? 입력 픽셀이 하나만 달라도 출력값이 완전히 달라지기 때문에, Predictor는 비슷한 상태들 사이의 연관성을 전혀 찾지 못했을 것이다. (이 경우엔 정말로 모든 State를 다 따로 외워야 한다.) 하지만 타깃이 신경망이기 때문에, 비슷한 상태(State)는 비슷한 타깃 벡터(Target Vector)를 가진다는 성질이 유지된다. 덕분에 Predictor는 단순히 개별 상태를 달달 외우는 것이 아니라, "이런 모양의 이미지는 저런 식의 벡터로 변환되는구나" 하는 경향성을 학습하게 된다.
Loss function은 다음과 같다:
$$\| \text{Predictor}(x) - \text{Target}(x) \|^2 + \lambda ||\theta||^2$$
Predictor Network는 타깃의 아웃풋에 따라 학습하게 되어, 결국 많이 방문한 state에 대해서는 낮은 loss를 가질 수 있는 구조가 완성되는 것이다. 여기서 regularization term은, initalized된 패러미터가 0 근처로 머물도록 하여 보지 않은 데이터에 대해서 우연히 타깃을 맞추어 "가본 곳"으로 착각하지 않도록 만들어준다.
이렇게 방문하지 않은 state에 대해서 exploration 보너스를 추가해주어 학습하는 것이 본 논문의 방법론인 것이다. 게임 점수 에피소드마다 초기화되지만, 탐험은 에피소드가 달라지더라도 그대로 유지된다. 왜냐하면 탐험을 해서 잘못된 결과로 가게 되면 오히려 점수가 낮아진 것이 되니 모델은 탐험이 아닌 안전한 경로만 파악하려고 할 것이기 때문이다.
한가지 더 의문에 대해서 답해보자. Actor-Critic 알고리즘의 경우에는 이렇게 얻어지는 실제 보상과, 탐험 보너스를 얻을텐데 Critic이 이 두개를 합쳐서 학습하면 성격이 다른 두 가지 메트릭을 학습하는 것이기 때문에 학습 성과가 낮아지지 않겠는가에 대한 의문이다.
본 논문은 따라서 실제 Reward에 대한 value function과, 탐험 보너스에 대한 value function을 두 개의 head로 두어 따로 학습하는 구조를 취한다. 따라서

로 최종 Critic baseline이 만들어지게 되는 것이다.
Experiments

몬테주마의 복수는 기본적으로 숨겨진 행동들을 발견해서 문제를 해결해야 하는 게임이기에, 다른 방법에 비해서 월등한 성과를 보이는 것을 확인할 수 있다.

실험 결과에서, Dual-value, 그리고 non-episodic이 탐험을 잘 하는 것을 확인할 수 있다. (그렇게 차이가 나나 싶긴 하다 ㅋㅋ)
Conclusion
너무 장점만을 말한 것 같으니 문제점에 대해서 서술하고 마치도록 하겠다.
우선 모델은 항상 forgetting 문제가 있다. 즉 과거에 본 데이터에 대해서 학습을 하고, 새로운 데이터로 계속 데이터를 학습하다보면 과거의 데이터는 잊게 되고, 그렇게 되는 경우 방문한 상태임에도 더 높은 탐험 보너스를 줄 수 있다는 것이 문제라는 것이다. 다음 번에는 이 문제를 해결하는 논문에 대해서 알아보도록 하자!
'논문 리뷰 > RL' 카테고리의 다른 글
| UVFA 논문 리뷰 (0) | 2025.12.10 |
|---|---|
| PER 논문 리뷰 (0) | 2025.12.05 |
| Parameter Space Noise for Exploration 논문 리뷰 (0) | 2025.11.29 |
| TD3 논문 리뷰 (0) | 2025.11.28 |
| SAC 논문 리뷰 (0) | 2025.11.15 |