Intro
강화학습의 이슈 중 하나로 exploration vs. exploitation tradeoff를 생각할 수 있다. 즉 하던 것을 더 잘할 필요가 있으면서도(exploitation) 동시에 잠재적인 더 보상을 더 많이 얻기 위한 새로운 행동(exploration)을 해야 할 필요가 있으며, 이 두 목표를 달성하는 것이 강화학습의 목표 중 하나이다.
이를 위해 epsilon-greedy 방법을 사용하는 것이 우리가 보통 알고 있는 것이며, 아니면 soft MDP objective, 즉 policy에 엔트로피 항을 넣어 policy가 유사한 보상에 대해 한쪽으로만 쏠리는 선택을 하지 않도록 제어할 수도 있다. 그러나 두 방법론이 문제가 되는 케이스를 확인해보자:

매 스텝마다 앞, 뒤로 1만큼만 가는 카트가 딱 오른쪽 정상에 도달해야 보상을 50만큼 얻고(0 지점에서 앞으로 10만큼을 움직여야 함), 움직일 때마다 -1만큼의 보상을 얻는다고 가정해보자. 이 경우 보상이 아직 어디에 있는지 모르는 정책이 epsilon-greedy라고 한다면, 보상을 결국 얻으려면 1/2확률로 앞으로 가는 선택을 연속으로 10번 해야 하기 때문에 보상 지점에 달성하기가 너무 어려우며, 보상 지점까지 도달하기 위해서는 평균적으로 10^2만큼의 스텝을 기다려야 한다. (Random walk 참고) 그렇게 되면 discount rate에 따라 다르겠지만, 설령 도달하더라도 보상이 음수가 될 것이다.
Entropy base도 똑같다. 초기에 objective가 정책을 uniform하도록 강제하기 때문에, 앞, 뒤로 가는 확률이 1/2가 되고 결국 골짜기에서 앞뒤로 진동만 하는 결과가 나올 것이다.
이러한 경우에는 보통 Upper Confidence Bound 방법으로 해결하는 것이 맞다.
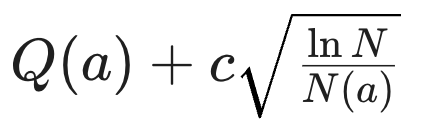
UCB 방법은 하지 않은 행동에 대해서 더 높은 확률적 가중치를 주도록 하여 정책이 보상에 도달할 수 있도록 유도하기 때문에 위와 같은 문제에 대해서는 적합하다고 볼 수 있다. 그러나 이 방법은 Deep RL에서는 사실상 불가능하다. 우선 discrete state/action space라고 가정하더라도, 만약 그 space가 너무 크다면 저장하는 것 자체가 불가능할 것이다. Continuous의 경우에도 카운트 자체에 대한 기준이 모호해지는 문제가 나올 것이다.
따라서 본 논문은 이러한 문제를 해결하기 위해, action에 노이즈를 추가하는 것이 아닌 Parameter 자체에 노이즈를 추가하는 방법으로 이러한 문제를 해결하는 전략을 제시한다.
Parameter Space Noise
방법은 간단해서 빠르게 설명하고 넘어가고자 한다. 우선 다음과 같이 parameter에 노이즈를 추가한다.
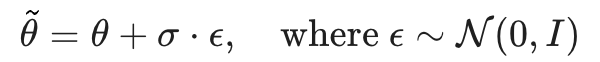
여기서 $\sigma$는 노이즈의 크기를 정하는 scale factor인데,

노이즈를 적용해서 만든 policy $\tilde{\pi}$가 기존의 policy와 크게 달라지지 않는다면 스케일을 키우고, 그렇지 않으면 스케일을 낮춘다. DDPG의 경우에는 L2 distance, DQN의 경우에는 KL divergence를 distance metric으로 사용한다.


이 부분을 참고하자. Off-policy의 경우 behavior policy network에 noise를 추가하고, target policy는 변형 없이 그대로 학습하면 된다. 그러나 on-policy의 경우 perturb된 policy가 학습도 하는 구조이기 때문에, 원래의 네트워크를 알고 있어야 업데이트가 가능하다. 이러한 경우에는 Gaussian policy를 이용하여 파라미터 자체를 확률 변수로 모델링하고, 우도비(Likelihood Ratio)이나 재파라미터화 트릭(Reparameterization Trick)을 통해 파라미터 분포의 평균(Mean)과 분산(Variance)에 대한 그래디언트를 직접 계산하여 업데이트한다. 그냥 ES랑 다를 것이 없지 않느냐? 아니다.
ES의 경우에는 random noise를 주어서 행동을 한 후 보상을 얻는 구조이기 때문에 미분 그래프가 끊어지는데, Gaussian policy를 통한 reparameterization의 경우 보상 → 행동 → 파라미터 → $\phi, \Sigma$로 이어지기 때문에 그 경로를 그대로 가져올 수 있다.
추가적으로, 본 논문에서 DQN에 대해서는

와 같은 설명을 추가한다. DQN은 value-base이기 때문에 Q에 perturbation을 추가하더라도 그 Q가 크게 변하지 않는다는 문제점이 있어 노이즈 추가가 어려운데, 따라서 본 논문은 따로 policy head를 추가하여 이 policy가 탐험을 할 수 있도록 perturbation을 적용한다.
Experiments

여기에서 특히 Enduro, Freeway 같이 exploration을 일관적인 방향으로 해야만 보상을 얻는 경우에서 더 좋은 성적을 달성하는 것을 확인할 수 있다.

중요한 실험 결과이다. Chain length에 대해서는 아래의 그림을 참고하면 된다:

Chain이 길어지게 되면 epsilon greedy은 아까 말했듯이, 제대로 된 보상을 얻기 위해서는 N^2만큼의 평균적 기다림이 있어야 하기 때문에 N의 증가에 대해서 제곱만큼 에피소드를 소비해야 하며, 이는 사실상 체인이 조금만 길어져도 불가능해지는 것을 알 수 있다. Bootstrapped DQN은 그나마 상황이 낫지만, chain이 길어지는 경우 문제 해결력이 상당히 떨어지는 것을 알 수 있다. 반면 Parameter space에 노이즈를 추가한 경우에는 N과 거의 관계 없이 문제를 전부 다 해결하는 것을 확인할 수 있다.

적응형 노이즈를 추가하는 경우가 효과적임을 알 수 있지만, 항상 그것이 맞는 방법이 아니다. 따라서 본 논문은 보상 체계가 어떻게 구성되어 있는지에 따라 방법론의 효과가 달라질 수 있음도 서술한다.
이만 마치도록 하겠다!
'논문 리뷰 > RL' 카테고리의 다른 글
| PER 논문 리뷰 (0) | 2025.12.05 |
|---|---|
| Exploration by Random Network Distillation 논문 리뷰 (0) | 2025.12.02 |
| TD3 논문 리뷰 (0) | 2025.11.28 |
| SAC 논문 리뷰 (0) | 2025.11.15 |
| DDQN 논문 리뷰 (1) | 2025.11.08 |