Universal Value Function Approximators
Prologue
전통적인 강화학습에서 상태 가치 함수(State Value Function) $V(s)$는 단 하나의 고정된 목표에 대한 가치를 의미한다. 만약 $V(s)$가 잘 학습된다면 우리는 환경 모델에 대해 알고 있다는 가정 하에, 적어도 모르더라도 좋은 policy를 학습할 수 있다.
하지만 현실의 문제는 그리 단순하지 않다. 에이전트가 마주할 목표는 무수히 많으며, 상황에 따라 목표 자체가 시시각각 변하기도 한다. 이때마다 매번 $V(s)$를 처음부터 다시 학습하는 것은 극도로 비효율적이다. 본 논문은 이러한 한계를 넘어, **상태($s$)와 목표($g$)를 아우르는 범용적인 가치 함수(Universal Value Function)를 제안한다.
우선 $V(s)$에서 $V(s,g)$로 넘어가야 하니 problem setting 자체가 달라질 것이다. 첫째로 $V(s)$는 이상적인 경우에 1차원 tabular 값으로 정해지겠지만, $g$가 들어왔기 때문에 2차원 tabular setting이 된다. 이렇게 $g$가 들어왔으니 reward에 대한 형태도 달라질 필요가 있다.
기존 강화학습에서 목표(Goal)는 보상 함수 $R(s, a)$ 내부에 하드코딩되어 있었던 것을 생각하자. 예를 들어, '좌표 (10, 10)에 도달하면 +1'이라는 규칙이 함수 안에 고정된 상수처럼 박혀 있었던 것을 말한다. 하지만 Universal Value Function을 만들기 위해서는 목표가 더 이상 고정된 상수가 아니라, 상황에 따라 변하는 변수가 되어야 한다. 따라서 보상 함수 역시 목표 $g$를 입력으로 받아, "현재 상태 $s$가 지금의 목표 $g$를 얼마나 만족하는가?"를 평가하는 $R(s, a, g)$의 형태로 확장되어야 할 필요가 있다.
이를 수식으로 표현하면 보통 다음과 같은 거리 기반(Distance-based) 혹은 달성 여부(Binary) 형태를 띠게 된다.
즉, 보상 함수는 이제 절대적인 '좋음'을 평가하는 것이 아니라, 목표 $g$와의 '관계(유사도)'를 평가하는 함수로 재정의되는 것이다. 할인율 또한 달라져야 한다. 만약 $g$가 목표였다면~ 이라는 가정이 있기 때문에, 만약 $g$에 도달한다면 그 보상의 전파를 끊어줄 필요도 있다.
이제 핵심적인 로직들을 확인하자.
1. Value function 근사를 어떻게 진행하는가?
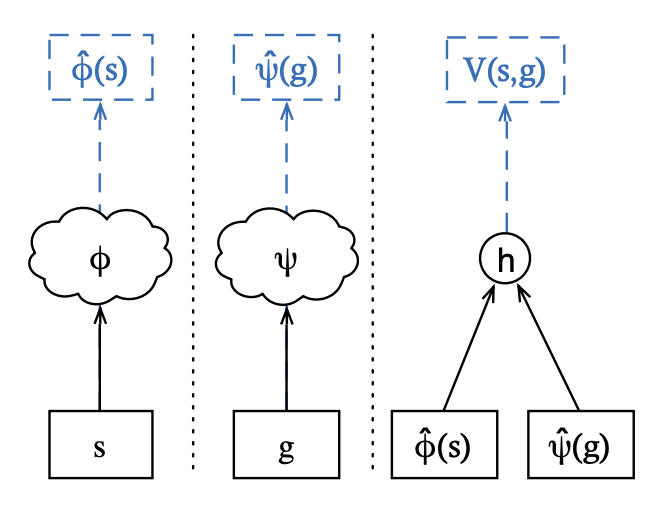
기본적으로 state, goal pair에 대한 value는 $\phi(s)$와 $\psi(g)$에 대한 내적으로 정의된다. 이 내적이 $V(s,g)$를 예측하도록 구성되는 것이다. 어렵게 보이지만, 사실 matrix completion이다.

$U, V$에 대해서, $UV^T$가 $V(s,g)$와 유사해지도록 학습한다. 이때 중요한 점은 임베딩의 차원(Rank)을 낮추고 L2 Norm 제약을 건다는 것이다. 이를 통해 모델은 데이터의 자잘한 노이즈를 무시하고, 상태와 목표 공간을 아우르는 본질적이고 강건한 구조(Robust Manifold)만을 학습하게 된다. 특히 강화학습에서 value function은 방문되지 않은 상태에 대해서 값이 없는 경우가 상당히 많다는 문제점이 있기 때문에, 이렇게 low-rank 근사는 실제 얻어진 보상의 근방에 대한 가치를 예측할 수 있어 하나의 해결책이 될 수 있다. 논문에서 특히 강조하는 내용에 대해서 확인해보자:

우선, 아키텍처는 상태와 목표 사이의 공통 구조를 유지하려고 한다. 왜냐하면 결국 어떠한 목표는 상태와 동떨어진 것이 아니라, 상태 집합의 일부일 것이기 때문이다. 그러한 전략으로, 1) $\phi$와 $\psi$가 공통된 뼈대를 공유하며 head 부분만 분리되는 경우, 2) $\phi$와 $\psi$가 아예 같은 구조를 가져서 matrix $UV^T$가 대칭구조를 이루는 경우이다.
결론적으로 이러한 임베딩 벡터들($U, V$의 $s$, $g$번째 열)은 특정 state와 goal에 대한 유용한 representation이 되며, 특히 위의 전략을 사용하는 경우 상태 간 연관성까지 더욱 잘 표현할 수 있도록 하게 된다는 장점이 있다.
2. Sparse한 value function이라도 어느 정도는 채워져야 한다
Dimension이 큰데도 정말 조금의 state-goal value만 가지고 있다면 학습이 상당히 곤란할 것이다. 어느 정도는 채워져있어야 근사를 하는 것의 의미가 있을 것이기 때문이다. 여기서 Horde라는 개념이 나온다.

우선 $b_1$에서, behavior policy가 어떠한 제약 없이 데이터를 아무렇게나 수집한다. 그렇게 돌아다니며 수집한 데이터를 replay buffer에 저장한다.
이후 $b_2$에서, Horde들이 replay buffer에서 데이터를 꺼내면서 $Q_g$, 즉 목표가 $g$인 경우에의 state-action pair에 대한 가치를 업데이트한다. Off-policy update라고 생각하면 편하다.
11-17에서는 그렇게 만든 $Q_g(s,a)$를 바탕으로 value-goal matrix $M$을 만들고, $M$을 low-rank 분해한다. 이어지는 $b_3$에서는 그렇게 분해된 embedding을 예측하도록 학습된다.
이 방법이 효과적인지에 대한 검증의 두 방법으로, 논문에서는 Interpolation과 Extrapolation을 제시한다.
UVFA가 행렬 분해(Matrix Factorization)에 기반을 두고 있다는 것은, 결국 이 모델이 '빈칸 채우기(Matrix Completion)'에 특화되어 있음을 의미한다. 우리는 모든 상태($s$)와 모든 목표($g$)의 조합을 경험할 수 없다. 그러나 데이터가 Sparse 하더라도 그 안에 저차원 구조(Low-rank structure)가 존재한다면, 경험하지 못한 조합에 대해서도 값을 추론해낼 수 있다. 이를 보간(Interpolation이라 한다.
보간(Interpolation)이 기존 데이터의 분포 내에서 빈칸을 채우는 것이라면, 외삽(Extrapolation)은 분포를 벗어난 완전히 새로운 영역을 예측하는 것이다. 이는 훨씬 더 어려운 문제다. 예를 들어, 에이전트가 1, 2, 3번 방에 있는 목표만 학습했는데, 갑자기 "4번 방으로 가라"는 명령을 받는다면 어떻게 될까? 일반적인 지도 학습이라면 실패할 수밖에 없다. 하지만 UVFA는 대칭성이라는 강력한 무기를 통해 이를 해결한다. 핵심은 상태를 처리하는 네트워크($\phi$)와 목표를 처리하는 네트워크($\psi$)의 파라미터를 공유하는 것이다. 에이전트는 4번 방을 '목표'로 받은 적은 없지만, 탐험 과정에서 4번 방을 '상태($s$)'로서 방문한 적은 있다. 대칭 구조 덕분에, 상태로서 4번 방을 처리하며 얻은 지식은 즉시 목표를 처리하는 능력으로 전이된다. 아래의 실험을 통해 확인해보자.

Conclusion
강화학습에서 가치 함수 $V(s)$는 오랫동안 '고정된 하나의 목표'에 종속되어 있었다. 목표가 바뀌면 에이전트는 무력해졌고, 처음부터 다시 학습해야 했다. 이는 인간의 직관이나 효율성과는 거리가 멀었다. 본 논문은 가치 함수를 $V(s, g)$로 확장함으로써 이 패러다임을 완전히 뒤집었다. **Universal Value Function Approximators (UVFA)**는 다음과 같은 의의를 지닌다.
- 일반화(Generalization): 상태와 목표 사이의 구조적 관계를 학습함으로써, 경험하지 못한 목표에 대해서도 즉각적인 대응(Zero-shot)이 가능하다.
- 데이터 효율성(Data Efficiency): Horde 아키텍처와 결합하여, 한 번의 경험 스트림을 통해 수백 개의 목표를 동시에 학습한다. 이는 추후 HER(Hindsight Experience Replay)와 같은 데이터 효율적 알고리즘의 모태가 되었다.
- 표현 학습(Representation Learning): 상태와 목표를 동일한 임베딩 공간에 매핑함으로써, 에이전트가 환경의 기하학적 구조를 스스로 파악하도록 유도한다.
그러나 문제가 많기도 하다. 우선 구조적 연관성(Shared Structure)에 대한 의존도가 매우 높다. UVFA가 작동하는 전제 조건은 상태와 목표가 저차원 매니폴드(Low-rank manifold) 위에서 서로 연관되어 있어야 한다는 것이다. 미로 탐색이나 로봇 제어처럼 기하학적 법칙이 지배하는 환경에서는 강력하지만, '요리하기'와 '체스 두기'처럼 서로 전혀 다른 성격의 목표(Heterogeneous tasks)를 하나의 신경망으로 묶으려 한다면 성능은 처참할 수 있다.
둘째, 치명적 간섭(Catastrophic Interference) 문제다. 하나의 신경망 파라미터를 공유하여 수백 개의 목표를 동시에 학습하다 보니, 특정 목표 A를 잘하기 위해 업데이트된 그라디언트가 목표 B의 성능을 오히려 떨어뜨리는 현상이 발생할 수 있다. 이로 인해 단일 목표에 특화된 전문가(Specialist) 모델보다 고점(Peak performance)이 낮아지거나 학습이 불안정해지는 경향이 있다.
마지막으로, 목표 정의(Goal Representation)의 어려움이다. 논문의 실험처럼 $(x, y)$ 좌표나 픽셀로 명확히 떨어지는 목표는 현실에 드물다. '맛있는 커피를 만들기'나 '사용자를 즐겁게 하기' 같은 추상적인 목표를 어떻게 수학적인 벡터 $g$로 변환할 것인지는 여전히 해결해야 할 난제로 남아 있다.
'논문 리뷰 > RL' 카테고리의 다른 글
| PlaNet 논문 리뷰 (0) | 2025.12.17 |
|---|---|
| HER 논문 리뷰 (1) | 2025.12.11 |
| PER 논문 리뷰 (0) | 2025.12.05 |
| Exploration by Random Network Distillation 논문 리뷰 (0) | 2025.12.02 |
| Parameter Space Noise for Exploration 논문 리뷰 (0) | 2025.11.29 |