Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Summary
Model-free RL은 본질적으로 매우 높은 샘플 복잡도를 가지며, 특히 on-policy 계열은 과거 데이터를 재사용할 수 없어 비효율적이다. Off-policy 방식은 샘플 효율성을 확보할 수 있지만, bootstrapping과 function approximation 때문에 수렴이 불안정하고 하이퍼파라미터에 민감하다는 문제가 있다.
DDPG 계열은 off-policy의 이점을 가지지만 deterministic policy 구조로 인해 탐험이 어렵고, actor-critic의 상호 의존성 때문에 불안정성이 크다. 한편 soft Q-learning 기반 maximum entropy RL은 탐험성과 robustness를 크게 향상시키지만, continuous action space에서는 정책을 샘플링하기 위해 별도의 sampler 네트워크를 학습해야 해서 실용성이 떨어진다.
SAC는 이러한 한계를 해결하기 위해 maximum entropy framework를 actor-critic에 직접 통합하고, policy를 Gaussian neural network로 parameterize하여 복잡한 approximate inference 없이도 soft optimal policy를 근사한다. 또한 Q-network와 별도의 soft value network를 도입하여 학습 안정성을 높이고, replay buffer를 활용해 off-policy에서도 높은 샘플 효율을 유지한다.
Soft Policy Iteration의 MDP, tabular setting에서의 수렴성을 다루는 내용이 중요하다고 생각하지만, deep RL에 대한 내용을 주로 다루고자 생략하도록 하겠다. 중요한 내용이니 꼭 참고하자
Soft Actor-Critic
우선 Maximum Entropy Reinforcement Learning을 확인하자. Standard RL의 경우 $\sum_t \mathbb{E}_{(s_t,a_t)\sim\rho_\pi}[r(s_t,a_t)]$을 최대화하는 반면 SAC에서는 policy의 entropy가 포함된
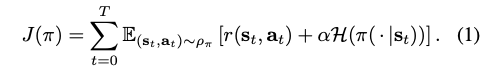
을 최대화하고자 한다. 여기서 정책의 엔트로피는
$$ \mathcal{H}(\pi(\cdot|s)) = \mathbb{E}_{a\sim\pi}[-\log\pi(a|s)]$$
로 정의된다. 즉 RL은 보상을 단순히 최대화할 뿐만 아니라 exploration을 하는 것을 추구하기 때문에, entropy를 추가하여 policy가 stochastic, 즉 exploration을 할 수 있도록 만든다.
V-Network
Value function 또한 entropy를 포함해서 정의된다. 기존의 value function이
$$ V(s)=E_{a\sim\pi}[Q(s,a)] $$
라고 하면, entropy를 포함하게 되면
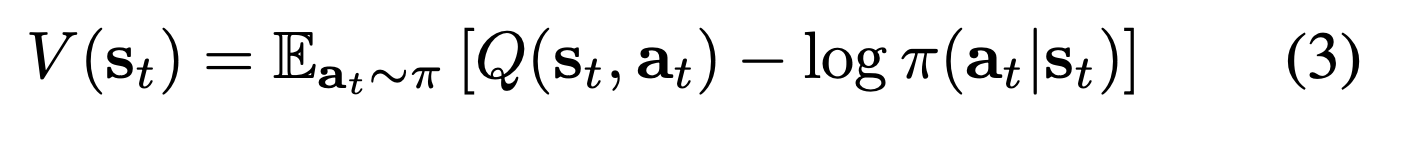
과 같은 수식이 된다. 우선 고정된 Q와 $\pi$에 대해서, state value function은

을 최소화하도록, 즉 bellman equation을 만족하도록 V-network을 backup하는 과정이다. 논문에서는 이러한 V-network가 반드시 필요한 것은 아니라고 하지만 훈련 과정에서의 stability을 가져오며 편리성을 준다고 하는데, 이후에 다시 확인해보자.
Q-Network
Q-Network도 훈련되어야 하는 구조이다.

여기서 target value는 $\hat{Q}$가 되며, $\hat{Q}$는 value network의 EMA를 이용한다. EMA의 존재성으로 인해 target Q가 안정화될 수 있다는 장점이 있다. Target Q를 왜 굳이 V를 레퍼런스로 하는가? 그냥 target Q 자체를 먼저 안정화하면 되지 않는가?
- Q는 V보다 차원이 $|\mathcal{A}|$배 만큼 더 크다. 따라서 분산이 커질 가능성이 높다.
- Q는 bootstrap이 더 깊으며, 오차가 더 빨리 폭발한다. 즉 V 오차의 경우 $\pi$의 오차에만 영향을 받지만 $Q$의 경우 $V$ 오차 또한 받기 때문에, 더 불안정하다.
- SAC는 V를 통해 Q와 $\pi$를 중계하는 구조이기 때문에, $\pi$가 Q를 직접적으로 망치지 못하도록 한다.
Policy(Actor)
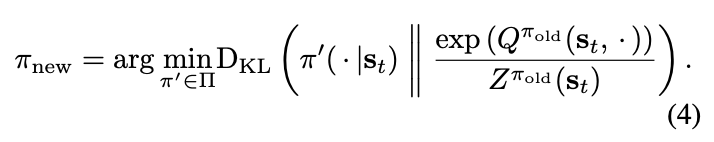
나중에 다루겠지만 이렇게 만들어지는 최적 정책은 Q에 비례한 Boltzmann distribution, 즉 softmax over Q의 형태가 된다. (왜 soft actor-critic라 하는지에 대한 이유이기도 하다)
$$ \log \pi(a\mid s) \propto \exp(Q^\pi(s,a))$$
형태의 Boltzmann 분포를 따르는 것을 의미하지만, continuous action space에서는 이러한 분포를 그대로 표현하는 것이 불가능하다. 따라서 실제 구현에서는 정책을 특정 parametric family로 제한해야 하며, SAC에서는 tractable한 정책 클래스 Π로서 Gaussian policy를 사용한다.
이러한 제약을 만족하도록, 즉 목적식을 만족하도록 하는 방법으로 likelihood ratio policy gradient를 사용하는 방법도 있지만 이의 경우 분산이 지나치게 크다는 문제점이 있다. Policy가 직접 샘플링한 action에 대해서는 미분이 불가능하므로, 본 논문에서는
정책을 Gaussian으로 parameterize한 뒤 reparameterization trick을 이용하여 action을
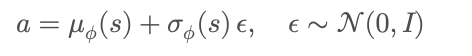
으로 φ에 대해 미분가능한 deterministic transformation으로 바꿔 안정적인 정책 업데이트를 수행한다.

이제 알고리즘을 확인해보자:

여기서 Q-network를 두개 두어 안정성을 더한 것을 확인할 수 있다.
Experiments

더 높은 성능과 빠른 수렴 속도를 확인할 수 있다. 이만 논문 리뷰를 마치도록 하겠다 피곤이슈 ㅠㅠ
'논문 리뷰 > RL' 카테고리의 다른 글
| Parameter Space Noise for Exploration 논문 리뷰 (0) | 2025.11.29 |
|---|---|
| TD3 논문 리뷰 (0) | 2025.11.28 |
| DDQN 논문 리뷰 (1) | 2025.11.08 |
| MCTS 논문 리뷰 (0) | 2025.10.04 |
| DQN 논문 리뷰 (0) | 2025.09.08 |