Deep Reinforcement Learning with Double Q-learning
Double DQN은 Double Q-learning의 selection/evaluation 분리를 DQN 구조에 최소 변경으로 통합하여 overestimation bias를 크게 완화시키고, Atari 대규모 벤치마크에서 더 안정적이고 robust한 정책을 학습할 수 있음을 보였다.
Background
Deep Q-learning
우선 Q-learning의 업데이트 구조는 다음과 같다 (TD(0) 기준으로 설명):
$$ Q(s,a) \leftarrow Q(S_t,A_t) + \alpha\left[R_{t+1} + \gamma\max_a Q(S_{t+1}, a) - Q(S_t,A_t) \right] $$
이때 $R_{t+1}+ \gamma\max_a Q(S_{t+1}, a)$은 실제 보상과 그 이후 상태에 대한 estimate가 합쳐진 target이 되며 현재 state-action value estimate인 $Q(S_t, A_t)$와의 차이를 TD error로 업데이트된다.
이때 off policy, 즉 behavior policy는 stochastic, target policy는 greedy이기 때문에 exploration과 exploitation을 분리할 수 있어 sample을 매 업데이트마다 재생산할 필요가 없다는 장점을 가지고 있다. 그러나 max operator가 estimation noise를 항상 양의 방향으로 bias시키는, overestimation bias가 발생하며 특히 Q estimation에서 function approximation이 들어가면 더 악화된다는 문제가 있다. 또한 target을 bootstrap로 계산하기 때문에, moving target 문제가 나타나며 이것이 딥러닝과 연결되는 경우 더 문제가 많이 생긴다.
DQN은 이러한 문제를 해결하기 위해 experience replay를 통해 sample correlation을 제거하여 데이터의 i.i.d.를 근사적으로 충족시키려 하며, 또한 target network, 즉 target의 weight를 일정 기간동안 고정시켜 안정적인 학습을 도모한다.
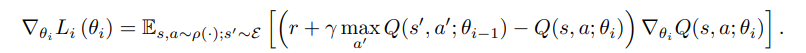
그러나 여전히 overestimation bias를 낮추지 못하며, 이 문제를 본 논문에서는 주요 문제점으로 지적한다.
Double Q-learning

위의 알고리즘을 확인하자. $Q_1$ 업데이트가 일어날 확률과 $Q_2$ 업데이트가 일어날 확률은 각각 1/2이며, 각각의 행동 선택은 단순 maximum이 아닌 서로 다른 action-value function의 greedy action으로 결정된다. 논문에서는 Overoptimism due to estimation errors 섹션에서 Q-learning과 Double Q-learning의 maximization bias에 대해서 더 설명한다.
Overoptimism due to estimation errors

증명은 필자가 상당히 부족하기 때문에 넘어가고, 어떤 것을 설명하는지에 대해서 다루고자 한다.
우선 해당 state에서 모든 action의 true optimal value는 동일하다고 가정할 때, 추정하는 Q에 대해서 V와의 차이가 평균적으로 0, 즉 unbiased이어도 variance는 0보다 큰 값으로 존재한다. 이러한 상황에서
$$ \max_a Q_t(s,a) \geq V^{\*}(s)+\sqrt{C/(m-1)}, $$
즉, max는 평균이 unbiased이어도 positive direction으로 bias가 밀린다는 것을 확인할 수 있다. 추가적으로 논문에서는 action space가 커지면 lower bound가 수학적으로 낮아지는 것처럼 보이더라도, 실제로는 overestimation bias가 더 커진다는 것 또한 언급한다.

그러나 double Q-learning의 경우 그 lower bound가 0으로, 노이즈가 서로 다른 함수에게 각각 selection과 value를 할당하기 때문에 bias가 생기는 구조를 절단하게 되는 것이다.
Double DQN
아키텍처는 다음과 같다.

Target에서 action selection은 학습하고자 하는 네트워크로 parameterized된 Q를 기반으로 하고, 실제로 그에 대한 value를 아웃풋으로 내는 것은 DQN에서 target network, 즉 일정 기간마다 freeze된 네트워크를 사용하는 것을 알 수 있다.

Overestimation bias를 크게 줄이는 것을 확인할 수 있다. DDQN에 따른 학습 방법이 더 좋은 성적을 내는 것 또한 확인할 수 있다. 여기서 더 중요한 실험으로 robustness to human starts 섹션을 확인해보자.
본 논문은 DDQN이 "진짜로" generalization을 했는지, 혹은 그저 deterministic memorization으로 score만 챙긴 것이 아닌지 검증하는 evaluation을 진행하였다. Deterministic한 게임에서, start state가 항상 동일하면 Q-network가 단순 action sequence memorize만 하더라도 높은 성적을 낼 수 있는데, 이것은 RL에서 바라던 바가 아니다. 따라서 Human Starts evaluation은 인간이 한 trajectory에서 임의의 start point를 뽑은 후, 거기서부터 성능을 체크한다.
여기서 결과는 baseline DQN은 deterministic exploitation에 더 가까웠으며, double DQN은 overestimation을 줄이고, stable한 업데이트가 가능했기 때문에 결과적으로 다른 start distribution에서도 좋은 성능을 유지할 수 있었다.
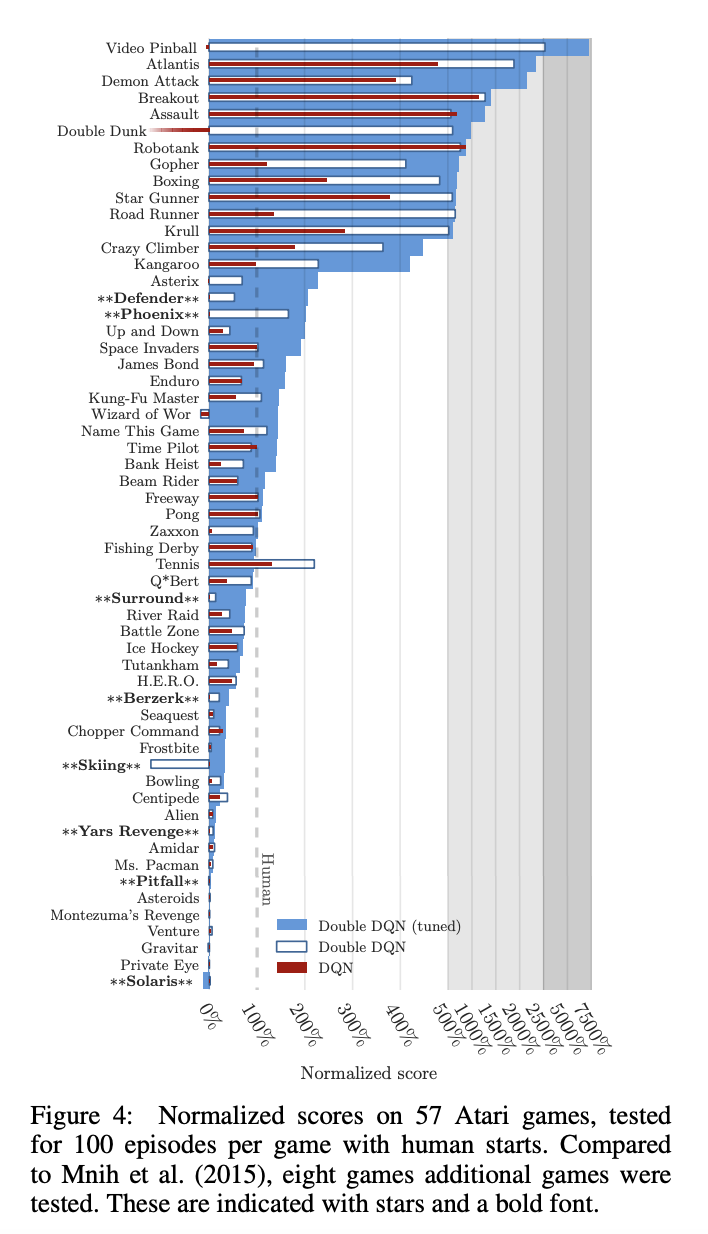
즉 double DQN은 단순 memorization policy가 아닌, generalizable policy에 더 가까워진 것이다. 이만 논문 리뷰를 마치도록 하겠다!