Proximal Policy Optimization Algorithms
Summary
본 논문은 기존 Policy Gradient 방법의 한계를 지적한다. 정책 업데이트마다 새로운 trajectory를 샘플링해야 하고, 동일 trajectory를 반복 사용하면 정책이 붕괴된다는 점이다. 이를 해결하기 위해 제안된 TRPO(Trust Region Policy Optimization)는 KL divergence 제약을 통해 과도한 업데이트를 막지만, 제약식 최적화의 복잡성 문제가 있다.
이에 보다 단순하면서도 효과적인 PPO(Proximal Policy Optimization)를 제안한다. PPO는 (1) Clipped Surrogate Objective로 업데이트 크기를 제한하거나, (2) KL penalty 항의 $\beta$ 값을 자동 조정하는 방법을 통해 안정성을 확보한다. 이러한 접근은 구현이 간단하면서도 기존 방법보다 높은 효율과 우수한 성능을 보여준다.
Preliminary
Policy Gradient Method

여기서 $\hat{A}_t = Q(s_t, a_t) - V(s_t)$ 로, advantage를 의미한다. $V(s_t)$는 현재 state $s_t$에 있는 것의 가치, 즉 $s_t$에서 앞으로 나오는 모든 행동 값 / 상태들에 대한 가치의 평균이며 $Q(s_t, a_t)$는 $s_t$에서 행동 $a_t$를 하는 것의 가치를 의미한다. 결국 $\hat{A}_t = Q(s_t, a_t) - V(s_t)$는 현재 상태의 가치 평균 대비 행동 $a_t$를 하는 것의 가치가 얼마나 이점을 주는지에 대한 term인 것이다.
이 방법은 앞서 언급했듯이, 정책 업데이트마다 새로운 trajectory를 샘플링해야 하여 사실상 불가능하고, 동일 trajectory를 반복 사용하면 정책이 붕괴된다는 점이 한계이다. 따라서 기존 trajectory를 그대로 사용하면서 정책이 붕괴되지 않도록 해야할 필요가 있고, 이는 TRPO(Trust Region Policy Optimization)이 해결책 중 하나가 된다.
Trust Region Method

여기서 KL은 비선형 함수이기 때문에 제약식 자체가 복잡해지기 때문에 다음과 같은 방법을 사용한다:
- $\theta \approx \theta_{\text{old}} + \Delta \theta$ 로 정한 후
- 목적함수 $L(\theta) = \hat{\mathbb{E}}_t [\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}} \hat{A}_t] \approx L(\theta_{\text{old}}) + \nabla_\theta L(\theta)^T \Delta \theta $ 로 taylor 근사
- KL 제약의 경우 $\hat{\mathbb{E}}[KL(\pi_{\text{old}} || \pi_\theta)] \approx \frac{1}{2} \Delta \theta ^T F \Delta \theta $로 2차 근사. 여기서 $F$는 fisher information matrix
따라서 앞선 제약식은 다음과 같은 근사된 최적화 문제로 변형된다:
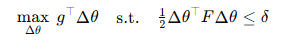
이는 사실상 QP(Quadratic Program)으로 바뀌게 되며, 즉 제한된 크기의 타원 내에서 $g$와 최대한 같은 방향으로 가도록 학습된다. 이 최적화 문제에 관한 closed form solution은 다음과 같다:
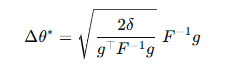
그러나 이 방법은 fisher information matrix $F$의 역행렬을 계산해야 하기 때문에 직접적으로 역행렬을 계산할 수 없어, conjugate gradient 방법으로 근사적으로 $F^{-1}g$를 계산해야 하며, 이 근사만으로는 온전하지 않아 line search 또한 사용하여 제약 조건을 확인해야 한다.
논문에서 라그랑지안으로 풀어 문제를 해결하는 것도 언급하지만, 이 방법은 $\beta$ 값의 튜닝 문제로 복잡하다는 것을 해결하기에는 역부족임을 알 수 있다.

Proximal Policy Methods
Clipped Surrogate Objective

TRPO에서 최적화하고자 하는 대상(제약 X)은 다음과 같았다:
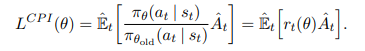
본 논문에서는 policy 최적화에 대한 제약 조건으로 clipping을 사용한다:
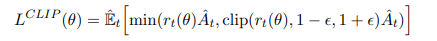
본 논문에서 $\epsilon = 0.2$로 설정한다.
매우 단순하게도, 이 방법은 기존 정책에 대한 새로운 정책의 비율, 즉 변화가 커지는 경우 clipping을 통해서 그 변화를 막는 것을 알 수 있다. 또한 기존의 업데이트 방법(CPI)와 비교하여 더 보수적인 값(min)을 선택하여 과도한 업데이트를 방지한다는 측면에서 안전하다고 할 수 있다.
Adaptive KL Penalty Coefficient
본 논문은 $\beta$값을 자동으로 튜닝하는 방법 또한 제시한다. $d = \hat{\mathbb{E}}_t[KL(\pi_{\theta{\text{old}}}||\pi_\theta)]$에 대해서, 미리 설정한 임계 범위 밖으로 $d$값이 설정되는 경우 $\beta$ 값을 조정하면 된다. 논문에서는 다음과 같은 방법을 사용하였다:

Algorithm

Value function(VF)에 대한 학습또한 필요하기 때문에 $L^{VF}_t(\theta) = (V_\theta(s_t)-V_t^{targ})^2$를 사용한다. $S[\pi_\theta]$는 정책 함수 $\pi$에 대한 entropy이며, 모델이 다양한 탐색을 하도록 하는 장치다. Uniform 분포에 가까울수록 entropy가 높고, 상수로 분포가 수렴하는 경우(degenerated) entropy가 0으로 되는 것을 생각하면, 정책 모델이 특정한 선택만 하지 않도록 유도함을 알 수 있다.
Pseudo code는 다음과 같다:

Experiments
본 논문은 다음과 같은 objective를 바탕으로 실험을 통해 각 방법을 비교/분석하였다.
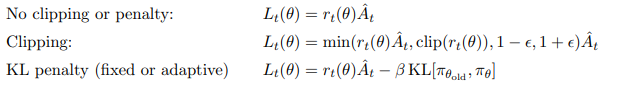
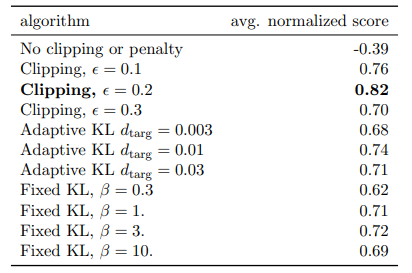
우선 본 논문에서 제시한 PPO방법(Clipping, 적응적 KL 방법)과 vanilla PG 방법, TRPO의 목적식을 라그랑지안으로 변형하여 적합한 방법 간 벤치마크 테스팅에 대한 성능 비교를 보면 clipping 방법이 우수함을 알 수 있다.
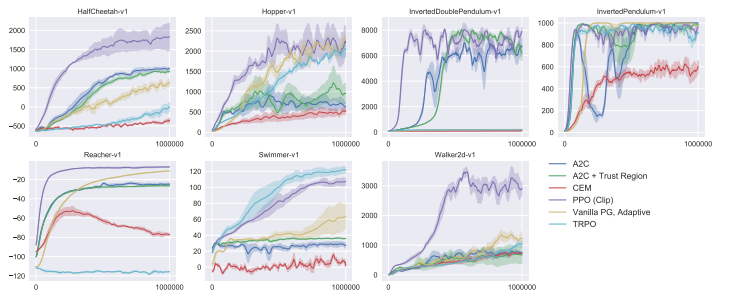
PPO (Clip) 방법이 다른 방법들보다 전체적으로 우수한 성능과 높은 일관성을 보이는 것을 확인할 수 있으며, 특히 같은 iteration 대비 성능이 더 빠르게 증가하는 것으로 보아 상당히 효율적임을 알 수 있다.
'논문 리뷰 > RL' 카테고리의 다른 글
| DDQN 논문 리뷰 (1) | 2025.11.08 |
|---|---|
| MCTS 논문 리뷰 (0) | 2025.10.04 |
| DQN 논문 리뷰 (0) | 2025.09.08 |
| RLHF 논문 리뷰 (0) | 2025.09.02 |
| DDPO 논문 리뷰 (0) | 2025.09.02 |