Deep Reinforcement Learning from Human Preferences
Summary
본 논문은 명시적 보상 함수 설계의 한계를 지적하며, 정책이 생성한 trajectory segment에 대한 인간의 선호 피드백만을 이용해 보상 모델을 학습하고, 이 보상 모델이 다시 정책 학습을 안내하는 방법을 제안한다.
이 접근법은 사람이 직접 정의하기 어려운 보상 구조나 분포에도 적용 가능하며, 전체 상호작용의 1% 미만 피드백으로도 충분히 일반화된 보상 모델을 학습하여, 복잡한 Atari 게임과 로봇 제어 과제에서 정책을 효과적으로 개선할 수 있음을 보여준다.
이를 통해 인간 피드백의 비용 문제를 해결하면서도, 기존 방식보다 훨씬 복잡한 행동을 학습 가능하게 한 첫 사례라는 점에서 의의가 있다.
Architecture
Settings
다음과 같은 Notation을 먼저 숙지하고 가자.
- $\mathcal{O}$: agent(policy model)이 관찰하는 상태 집합
- $\mathcal{A}$: agent(policy model)의 행동
- $\sigma$: 관찰-행동 쌍의 경로(trajectory), $\sigma = \{ (o_0, a_0), (o_1, a_1), \dots , (o_{k-1}, a_{k-1}) \} \in (\mathcal{O} \times \mathcal{A} )^k$로 표기된다.
두 개의 trajectory에 대해서 사람이 선호하는 trajectory를 $\sigma^1$라 표기하고, $\sigma^2$는 선호되지 않는 trajectory를 의미한다. 추가적으로, 보통 $\sigma^1 \succ \sigma^2$로 표기한다.
RLHF를 통한 보상 모델의 학습 과정은 다음과 같다:

여기서 중점적으로 봐야 하는 사항은 (1) 단순 이진 신호인 trajectory 쌍 $\sigma^1 \succ \sigma^2$을 어떻게 연속 신호로 모델링하는가와 (2) Human-preference인 만큼 데이터가 비교적 부족한 문제를 어떻게 해결하는가이다.
Optimizing the Reward Model
우선 인간의 선호와 일치하는 신호를 가지는 보상 모델 $\hat{r}$이 주어졌다고 가정하자. 보상 모델은 이진 선호가 아닌 연속 신호를 제공하며, 이 연속 신호는 Bradley-Terry model의 input으로 사용된다. 즉,
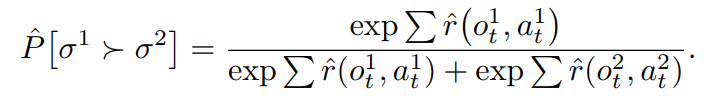
어떠한 trajectory $\sigma^1$이 $\sigma^2$보다 더욱 선호될 확률은 두 구간의 누적 보상을 비교하는 softmax 형태로 표현된다. 이렇게 하면 단순히 이진적 신호를 확률적인 연속 신호로 바꿀 수 있을 뿐만 아니라, 나아가 reward를 선호 척도로 해석할 수 있다는 장점이 존재한다.
Loss function은 다음과 같다:
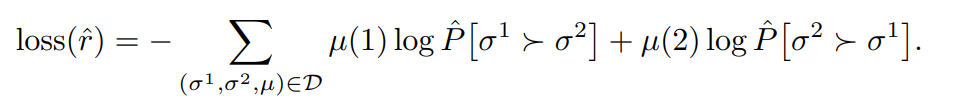
Cross-entropy loss이다. 여기서 $\mu$는 실제 사람이 선호한 데이터에 대한 정답 label이다.
Reward 모델에 주어지는 데이터는 비교적 적다. 그럼에도 불구하고 이것이 큰 문제가 되지 않는 이유는, reward 모델은 직접 환경을 완전히 학습할 필요가 없으며 단지 사람이 라벨링한 "이 궤적이 다른 궤적보다 더 낫다"라는 선호 기준에 대해서 패턴만 잘 잡으면 충분하기 때문이다.
또한 전체 trajectory를 제공하여 승/패만 결정하는 것이 아니라, trajectory를 잘라 짧은 클립으로 두어 pairwise 비교를 하기 때문에 한 개의 데이터가 여러 step에 영향을 줄 수 있다는 장점도 있다.
또한 loss function이 연속 확률 신호에 따른 업데이트를 제공하기 때문에, 더 안정적으로 학습할 수 있게 된다는 장점이 있다.
본 논문에서 제시하는, 보상 모델에 대한 추가적인 최적화에 관한 내용도 다뤄보자.

- 단일 모델을 사용하는 것이 아니라, 데이터셋 $D$에서 부트스트래핑으로 여러 예측기를 학습한 후, 독립적으로 정규화한 뒤 평균하여 variance를 줄이고, robustness를 높인다.
- Validation 데이터를 두어 보상 모델이 적은 데이터에 의해 과적합되는 위험을 줄인다.
- 사람의 오차를 고려하여, 사람이 10% 확률로 무작위로 응답한다고 가정하여 robustness를 키운다.
이러한 최적화 방법으로 인해 데이터가 부족함에도 문제 없이 보상 함수를 모델링하고 학습할 수 있는 것이다.
Experiments
다음과 같은 실험 세팅을 먼저 확인하자.
| 방식 | 설명 | 데이터 소스 | 시간/비용 | 기대 성능 |
|---|---|---|---|---|
| Human Feedback | 에이전트가 1~2초짜리 trajectory segment 쌍을 보여주고, 사람이 어느 쪽이 나은지 선택 | 작업자(contractors)의 선호 | 쿼리당 3~5초, 총 30분 ~ 5시간 인간 시간 | RL과 비슷하거나, 일부 과제에서는 오히려 더 나음 (더 잘 shaping된 reward 제공 가능) |
| Synthetic Oracle | 사람 대신, 실제 환경의 true reward가 더 높은 segment를 자동으로 선택 | underlying true reward | 추가 비용 없음 | RL과 거의 동일 (oracle은 실제 reward와 일치) |
| Real Reward | 전통적인 RL 환경이 주는 보상을 직접 관찰하고 최적화 | environment reward signal | 환경에서 직접 제공 | 최상의 baseline, 목표는 이를 근접하게 따라잡는 것 |
Synthetic oracle은 human feedback 방식이 얼마나 잠재력 있는지에 대한 평가 방식이며, 가상의 최대 성능치(upper bound) 역할을 한다.
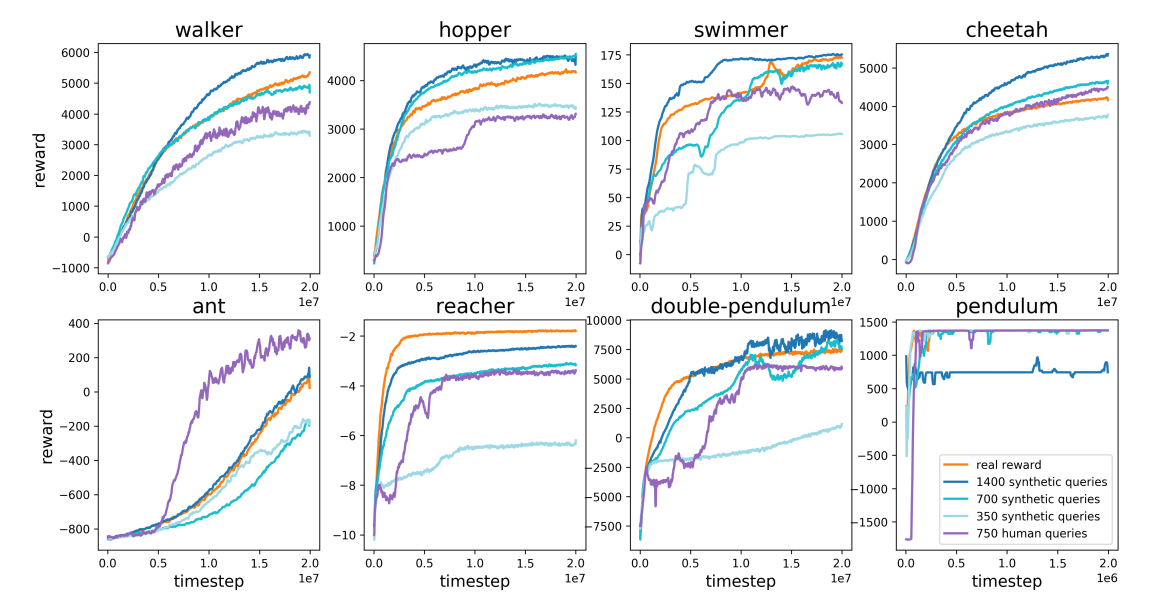
Robot simulation에서 실제 reward를 explicit하게 제공하는 것보다 human feedback을 제공하는 경우가 더 좋을 수 있으며, 추가적으로 synthetic oracle을 확인하여 성능의 잠재성을 체크해보면 정책 모델이 더욱 발전할 수 있다는 사실을 알 수 있다. 다른 실험도 있지만, abalation study를 먼저 보도록 하자.
Abalation study에서 baseline RLHF 모델(original)에서 가한 modification의 종류는 다음과 같다:
- Random queries: Labeling 효율을 고려하지 않고, 아무 쿼리나 랜덤으로 골라서 사람에게 보여주어 label
- No ensemble: 보상 모델을 여러 개 학습하는 것이 아닌 단일 보상 모델을 학습
- No online queries: 보상 모델을 업데이트하지 않고, 초기 정책 모델의 행동에 대한 feedback로 학습한 보상 모델로 유지
- No regulatization: 보상 모델 학습 과정에서 L2 regularization 제거
- No segments: 단일 step 단위로만 비교하여(trajectory를 구간 분할하지 않음) 보상모델 학습
- MSE error for reward model: CE loss가 아닌 MSE loss를 바탕으로 한 최적화

Original의 경우가 다른 modification들에 비해 일관성이 높거나, 성능이 더 높은 것을 확인할 수 있다. 논문에서는 또한 추가적으로 단일 trajectory를 바탕으로 학습하는 것의 보상은 sparse해져 적절한 보상 모델링이 되지 않으며, 따라서 짧은 클립으로 나누어 보상 모델에 제공하는 것이 더 유리하다고 언급한다.
'논문 리뷰 > RL' 카테고리의 다른 글
| DDQN 논문 리뷰 (1) | 2025.11.08 |
|---|---|
| MCTS 논문 리뷰 (0) | 2025.10.04 |
| DQN 논문 리뷰 (0) | 2025.09.08 |
| PPO 논문 리뷰 (0) | 2025.09.07 |
| DDPO 논문 리뷰 (0) | 2025.09.02 |