TRAINING DIFFUSION MODELS WITH REINFORCEMENT LEARNING
서당개마냥 강화학습을 공부하면서 살고 있다가 요즘은 강화학습을 열심히 공부하면서 살고 있다. 역시 서당개도 3년이면 풍월을 읊는다더니 점점 이해도 잘 되고 즐거워지는 것 같다.
Summary
본 논문은 diffusion 모델의 denoising 과정을 Markov Decision Process(MDP)로 재해석하고, 각 스텝을 정책(policy)으로 간주하여 정책 그래디언트 기법으로 최적화하는 DDPO(Denoising Diffusion Policy Optimization) 를 제안한다. 기존 reward-weighted likelihood 접근이 sparse reward와 근사적 한계로 인해 불안정했던 것과 달리, DDPO는 각 step의 정확한 likelihood를 활용하여 안정적으로 보상을 반영할 수 있다. 보상 모델을 따로 학습하지 않고도, 모델이 생성한 결과와 프롬프트의 정합도(BERTScore, CLIP score 등)나 aesthetics 같은 black-box 지표를 그대로 reward로 활용할 수 있다. 다양한 실험에서 DDPO는 prompt–image alignment, 이미지 압축 용이성, 미적 품질 등 downstream 목표에 맞게 diffusion 모델을 효과적으로 적응시킬 수 있음을 보였다.
Preliminary
Diffusion Model
Diffusion model의 objective 함수는 다음과 같다:

$\tilde{\mu}$는 foward process(노이즈 추가 과정)에서의 posterion mean으로, 각 step에서 $x_t$와 원본 $x_0$가 주어졌을 때의 $x_{t-1}$의 조건부 기대값이다. 이는 학습하고자 하는 $\mu_{\theta}$의 정답 target 이며, $\mu_{\theta}$ 는 각 스텝 $t$ 마다 노이즈를 제거하면서 생기는 오차 제곱의 평균(MSE)를 최소화하는 방식으로 학습된다. 따라서 posterior mean은 각 denosing 단계에서 모델이 따라야 할 노이즈 제거 방향을 제시하는 핵심 기준점이다.
본 논문에서는 이러한 과정을 하나의 trajectory, $\{x_T, x_{T-1}, \dots , x_0 \} $으로, 각 step을 Markov Decision Process로 간주한다.
Markov Decision Process and Reinforcement Learning
MDP는 에이전트가 초기 상태 $\rho_0$에서 시작하여, 각 타임 스텝 $t$에 대한 $s_t \in \mathcal{S}$에서 행동 $a_t \in \mathcal{A}$를 하며 그에 대한 보상 $R(s_t, a_t)$를 받고, 이후 새로운 state $ s_{t+1} \sim P(s_{t+1} | s_t, a_t) $ (여기서 $P$는 transition kernel이라 한다)로 이동하게 된다.
행동를 policy $\pi (a | s)$라 하고 state와 action의 trajectory(또는 sequence)를 $\tau = (s_0, a_0, \dots, s_T, a_T)$라 하자. 여기서 RL objective는 다음과 같다:

즉 모델은 보상을 최대화하는 방향으로 행동을 하도록 학습된다. 앞서 논문에서 diffusion 과정을 하나의 trajectory이기 때문에 각 step을 MDP로 볼 수 있다고 언급했는데, 나아가 이를 강화학습과 연결지을 수 있음을 알 수 있다.
Reward Weighted Regression
Reward weight의 형태는 다음과 같다.

여기서 $Z$는 normalization constant이다. RWR에서는 이러한 보상 체계를 가중 회귀로 접근하여, reward $r$을 가중치로 두고, 정책이 action $a$를 선택할 확률을 최대화하는 방향으로 정책 모델을 학습한다. 즉
$$ \max_{\theta} {\sum {w_i \log{\pi_{\theta}(a_i)}}} $$
Reward가 큰 샘플일수록 weight가 커지고, 정책이 그 행동을 더욱 잘 맞출 수 있도록 학습된다. 그러나 diffusion model은 앞에서 볼 수 있듯이 최종 likelihood $\log{p_\theta(x_0 | c)}$를 직접 계산하는 방식이 아닌, variational lower bound(ELBO) 방식으로 근사가 되기 때문에 RWR을 도입하는 것에는 한계가 있다.
Architecture
Denoising Diffusion Policy Optimization
앞서 언급한 RWR 방식은 최종 likelihood를 직접 계산하여 weighting regression 문제로 보상을 최대화하기 떄문에 diffusion의 방식과 맞지 않는다는 문제점이 있었다. 그러나 denoising 과정을 multi-step MDP로 재해석하면 likelihood를 직접 계산할 수 있다.
왜냐하면 policy는 $\pi_\theta(a_t | s_t) = p_\theta (x_{t-1} | x_t, c) $이며, 이 분포는 평균 $\mu_\theta$, 분산 $\sigma_{t}^2 I$ 의 가우시안 형태이기 때문이다. 따라서 만들어진 데이터 $x_0$에 대한 보상 $r(x_0, c)$가 제공되면 다음과 같은 policy gradient로 학습할 수 있는 것이다:
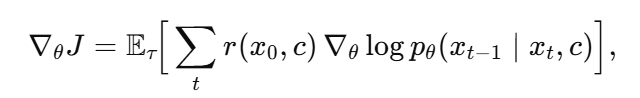
그러나 이 방식에서 trajectory $\tau$는 새로 업데이트된 $\theta$ 패러미터를 가지고 있는 모델의 샘플로부터 나오기 때문에, 매번 업데이트 후 샘플링을 해야 한다는 비효율성의 문제점을 안고 있다. 따라서 본 논문은 importance sampling을 통해 해당 문제를 해결하고자 한다.
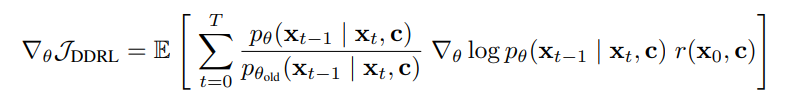
이 때 $\tau$는 과거의 모델 $p_{\theta_{\text{old}}}$ 에서 샘플링된 trajectory이며, 따라서 보정 계수를 위하여 $p_\theta$에 $p_{\theta_{\text{old}}}$를 나누어주어 보정을 통해 과거 데이터임에도 안정성을 보장한다.
본 논문은 업데이트되는 모델이 기존의 모델에 크게 벗어나서 collapse되는 상황을 막기 위해 PPO에서 사용하는 gradient clipping, 즉 trust region 방식을 사용하여 안정성을 더하고자 한다.
Reward Function for Text-to-Image Diffusion
지금까지 "이미지"라고 하지 않고 "데이터"라고 한 이유는, 위의 방법론이 단순히 이미지에만 국한된 방법이 아니기 때문이다. 그러나 본 논문에서는 해당 방법론의 응용 대상을 이미지 생성으로 두었기 때문에, 이제부터는 이미지라고 언급하겠다.
본 논문에서는 세가지 테스크(Compression, Aesthetic, Prompt Alignment)에 대한 방법론을 제공하였는데, 세 테스크 모두 다 reward function 없이 문제를 해결한다는 측면이 인상적이다. 그러나 (체력 이슈로) prompt alignment task를 어떻게 해결하는지에 관한 내용만 다르도록 하겠다.
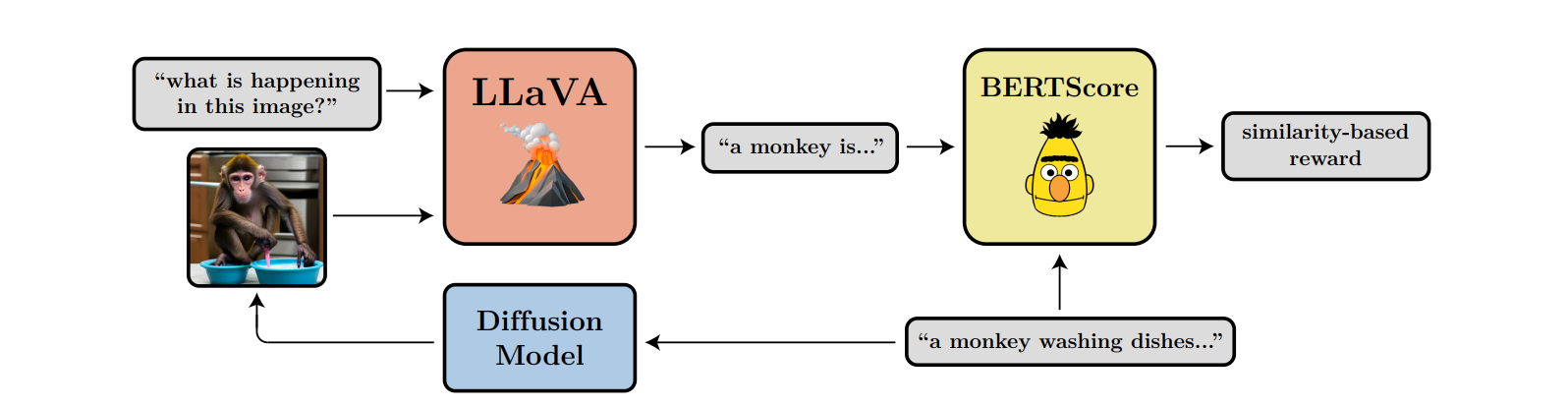
Reward function을 직접적으로 학습하지 않고, 초기 요청 context $c$에 대해서 만들어진 이미지를 VLM인 LLaVA에 넣어주고, 이 이미지에 대해서 설명을 output으로 내도록 한다. 그렇게 되는 경우 초기 요청 $c$와 만들어진 아웃풋이 얼마나 일치하는지 판단한다.
이렇게 만들어진 similarity base reward를 학습 대상인 모델에게 제공하여 강화학습을 하는 방향으로 진행된다.
이러한 방법은 강화학습 모델을 따로 훈련시켜야 한다든지, 아니면 이미지 생성에 대한 human-preference를 통해서 절차를 추가적으로 거친다든지 하는 비효율성이 적다는 장점이 존재한다.
Experiments


논문에서 언급한 방법론들이 실제로 diffusion model이 사용자가 원하는 바에 따라 학습될 수 있음을 확인할 수 있다. 원래 이러한 이미지를 만들기 위해서는 그저 supervised learning step에서 그러한 데이터를 추가해주는, 소위 memorize하는 수밖에는 없는데 강화학습을 추가하니 효과적으로 문제를 해결함을 확인할 수 있다.

이번에는 diffusion model의 강화학습 방법론에 대한 비교를 해보자. SF의 경우 importance sampling을 거치지 않고 각 업데이트시마다 새로이 데이터를 샘플링하는 방법이다.
우선 RWR 방법론에 비해서 DDPO의 성능이 현저히 높은 것을 확인할 수 있다. Importance sampling을 하면 보통 과거의 데이터를 바탕으로 학습하니 성능이 떨어진다고 생각할 수 있지만, 되려 SF 방법론보다 성능이 우수한 것을 확인할 수 있다.
Conclusion
강화학습을 적용하여 모델의 prompt alignment를 추가적으로 향상시키면서도, 동시에 새롭게 보상 모델을 학습하거나 데이터를 추가해주어 지도학습을 하는 것 없이 비용 최적화를 우수하게 했다는 점이 본 논문의 장점이라고 볼 수 있을 것 같다.
우려스러운 것은 보상 모델이 비교적 단순하여 reward hacking이 발생할 수 있다는 것이다. 또한 VLM을 이용하는 경우 VLM의 자체 성능의 한계가 diffusion 모델의 성능 상승을 막을 수도 있다는 생각은 들었다.
Policy gradient 방법에서, 최종 데이터를 바탕으로 일괄적 보상을 주는 것이 아니라 각 스텝에 따라 보상을 따로 주면 조금 더 효율적으로 학습을 할 수 있지 않을까 싶은데, 나중에 알아보도록 하겠다.
'논문 리뷰 > RL' 카테고리의 다른 글
| DDQN 논문 리뷰 (1) | 2025.11.08 |
|---|---|
| MCTS 논문 리뷰 (0) | 2025.10.04 |
| DQN 논문 리뷰 (0) | 2025.09.08 |
| PPO 논문 리뷰 (0) | 2025.09.07 |
| RLHF 논문 리뷰 (0) | 2025.09.02 |