Summary
IQL(Implicit Q-Learning)은 dataset support 위에서의 Bellman optimality를 근사하면서, OOD(Out-of-Distribution) action을 직접적으로 평가하지 않도록 만드는 Q-learning 방법이다.
IQL이 다른 Offline RL과 어떻게 다른지에 대해서 알아보기 위해, 우선 다른 대표적인 offline RL 방법론의 연구들을 살펴보고 IQL이 어떻게 문제를 풀고자 했는지 알아보도록 하자.
Preliminaries
Offline Reinforcement Learning
Offline RL은 Online RL과 달리 환경과 상호작용할 수 없기 때문에, 이미 주어진 데이터셋만을 이용해 정책을 학습해야 한다. 이때 중요한 능력 중 하나는 stitching이다. 즉, 데이터셋에 존재하는 여러 부분적인 trajectory 조각들을 조합하여, 데이터에는 직접 존재하지 않는 더 나은 trajectory를 구성할 수 있어야 한다. 아래 그림은 이러한 stitching의 개념을 직관적으로 보여준다:

빨간 선과 파란 선이 Offline Dataset이라고 했을 때, 사실 가장 효율적인 trajectory는 따로 있음(주황 선)을 알 수 있다. 이렇게 Offline Data에서 sub-optimal한 trajectory들을 잘 이어붙여서 optimal에 도달할 필요가 있다. 이렇게 Policy improvement라는 단 하나의 목표만 가진다면 Offline RL이 크게 어려운 문제가 아닐 것이다. 그러나 실제 Offline RL의 어려움은, 데이터셋에 존재하지 않는 Out-of-Distribution(OOD) 영역에 대한 value estimation이 매우 부정확해질 수 있다는 점에 있다. 특히 Q-learning 기반 방법에서는 policy improvement를 위해 unseen action의 value를 평가하게 되는데, 이 과정에서 함수 근사기는 데이터셋 밖 영역으로 값을 **과도하게 외삽(extrapolation)**하게 되고, 이는 심각한 성능 저하로 이어진다.
따라서 Offline RL의 핵심 문제는, 데이터를 벗어나지 않으면서도(policy constraint / safety) 동시에 더 나은 행동을 구성하는 것(stitching / improvement) 사이의 trade-off를 어떻게 다루느냐에 있다. 이에 대해서 알려진 방법으로, Value를 conservative하게 만들거나(ex: CQL), Actor을 conservative하게 제어하거나(ex: TD3-BC), 혹은 두 가지를 전부 다 제어하는 방식(ex: BRAC)을 사용한다.

그러나 본 논문이 이 방식들에 대해서 제기하는 문제는, 이러한 접근들이 여전히 policy improvement와 distributional safety 사이의 trade-off를 근본적으로 해결하지 못한다는 점이다. Policy를 데이터 분포 근처로 강하게 제한할 경우, 학습된 정책은 behavior policy에서 크게 벗어나지 못해 충분한 성능 향상을 이루지 못한다. 반대로, 이러한 제약을 완화하면 unseen action에 대한 value estimation이 불안정해지며, 함수 근사기의 외삽 오류로 인해 성능이 급격히 저하될 수 있다.
IQL은 이러한 문제를 당연히 완전히 해결하지는 못하지만, OOD action을 직접적으로 평가하지 않는 방식으로 문제를 재정의함으로써, 기존 방법들에서 나타나던 불안정성을 완화한다.
논문 리뷰를 하는 필자 입장에서 조금 더 강조하고 싶은 것은, IQL은 Action 혹은 Value constrained method가 근본적으로 가지는 문제를 해결하지는 못하며, Offline RL의 문제를 풀고자 하는 하나의 방법론이라고 생각하는 정도면 충분할 것이다.
Implicit Q-Learning
IQL이 결국 하고자 하는 것은 다음과 같은 loss function을 최적화하는 것이다:
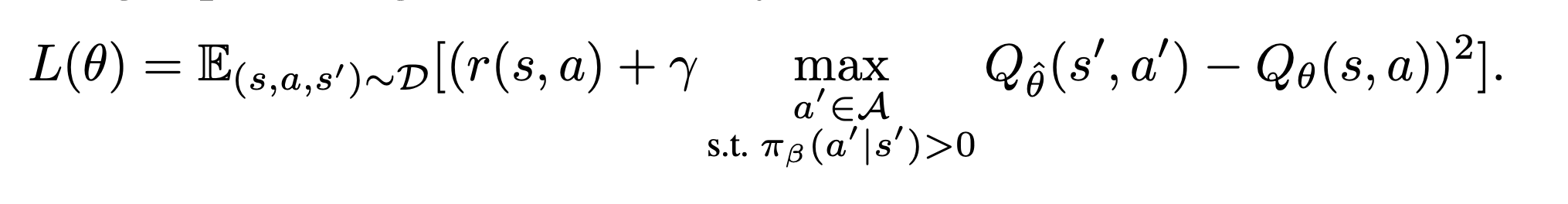
여기서 $\pi_\beta$는 dataset policy로, offline data를 의미한다. IQL이 하고자 하는 것은, dataset에 존재하는 action들로만 target Q를 만들겠다는 것이다. 그런데 여기서 한 가지 문제점이 존재한다. 바로 max는 $O(N)$ operator이라는 점이다. 이것이 문제가 되는 이유는, 매 iteration step마다 Batch size × N만큼의 연산이 필요해서 비효율적일 수 있는 방식이기 때문이다. 더 중요한 문제는 아무리 데이터셋 내부에 존재하는 action이라고 하더라도 max 연산자를 사용하여 타겟을 만드는 것은 overestimation error를 만들게 되어 학습의 불안정성을 증폭시킬 수 있다. 이에 대해서 IQL은 Expectile Regression이라는 방법으로 문제를 해결하고자 한다.
Expectile Regression
앞서 살펴본 것처럼, IQL은 max 연산을 직접 사용하지 않으면서도 dataset support 위에서 높은 value를 근사하고자 한다. 이를 위해 사용하는 핵심 도구가 바로 Expectile Regression이다. 우선 간단한 질문부터 생각해보자:
어떤 값들의 집합이 있을 때, "좋은 값"을 대표하는 하나의 값을 고르려면 어떻게 해야 하는가?
- 평균(mean): 모든 값을 동일하게 반영 → 지나치게 보수적
- 최대값(max): 가장 큰 값만 사용 → 불안정
우리가 원하는 것은 그 중간이다. 큰 값들을 더 강조하면서도, 완전히 하나의 값에만 의존하지 않는 방식인 것이다. 이 역할을 하는 것이 expectile이다. Expectile은 다음과 같은 최적화 문제의 해로 정의된다:

여기서 loss $L_2^\tau$는 다음과 같다:

이 loss의 핵심은 비대칭성에 있다. $x > m$인 경우, weight는 $\tau$로 반영되고, 반대의 경우 $1-\tau$로 반영된다. 만약 $\tau$가 0.5인 경우 양쪽이 동일해지므로 평균이 되며, 0.5보다 큰 경우 upper tail을 강조하여 1로 다가갈수록 max에 가까워지는 효과가 있다. 결국 IQL은 다음과 같은 loss function을 최적화한다:

그러나 expectile을 TD target에 직접 적용할 경우, 환경의 transition stochasticity까지 함께 반영되는 문제가 발생한다. 즉, 특정 action이 실제로 좋은 것이 아니라, 우연히 좋은 상태로 transition된 “lucky sample”일 수도 있음에도 불구하고, 높은 target value로 반영될 수도 있는, action quality + transition randomness가 섞인 형태가 된다.
이를 해결하기 위해 IQL은 action에 대한 variability와 환경의 stochasticity를 분리한다. 먼저, 상태 s에서 dataset action들에 대한 Q 값의 expectile을 통해 value function V(s)를 학습하고, 이후 이를 이용하여 Q-function을 TD 방식으로 업데이트한다. 이러한 구조를 통해 IQL은 action의 질을 반영하면서도, transition에서 발생하는 randomness로 인한 불안정성을 효과적으로 완화한다. 아래의 문구를 확인하자:

Policy extraction은 Advantage-weighted regression을 수행한다:

알고리즘은 다음과 같다:

추가적으로, 논문에서 IQL 방식 또한 policy improvement를 보장할 수 있음을 보이는데, 나중에 확인해보면 좋겠다. 사실 실험 결과는 엄청 드라마틱하게 좋지는 않지만, 하나의 접근 방법으로 생각해보면 될 것 같다:

이만 논문 리뷰를 마치도록 하겠다.