Summary
본 논문은 flow-based policy의 학습 및 추론 과정에서 기존의 instantaneous velocity 기반 flow matching이나 CNF 대신, mean velocity field를 직접 모델링하는 Mean Flow Policy (MFP)를 제안한다. 이를 통해 기존 flow policy가 갖는 다단계 적분(NFE 증가), BPTT 비용, 그리고 실시간 제어에서의 샘플링 병목 문제를 구조적으로 제거한다.
단순히 Mean Flow를 RL에 차용한 것이 아니라, RL 환경에서 Mean Flow를 적용할 때 발생하는 학습의 ill-posedness(해의 비유일성) 문제를 이론적으로 분석하고, 이를 해결하기 위해 Instantaneous Velocity Constraint (IVC)를 도입했다는 점이 핵심 기여다. 특히, mean flow identity가 경계조건 없이 다중 해를 허용한다는 점을 정리하고, IVC가 이를 수학적으로 well-posed한 문제로 만든다는 분석은 이 논문의 이론적 정당성을 뒷받침한다.
이러한 점이 본 논문이 ICLR 2026 Oral에 선정된 이유이며, 그런 만큼 우수한 논문이지만 어디서 논문이 설득력이 떨어지는지에 대해서도 알아보는 시간을 가지도록 하겠다.
Method
Mean Velocity Policy
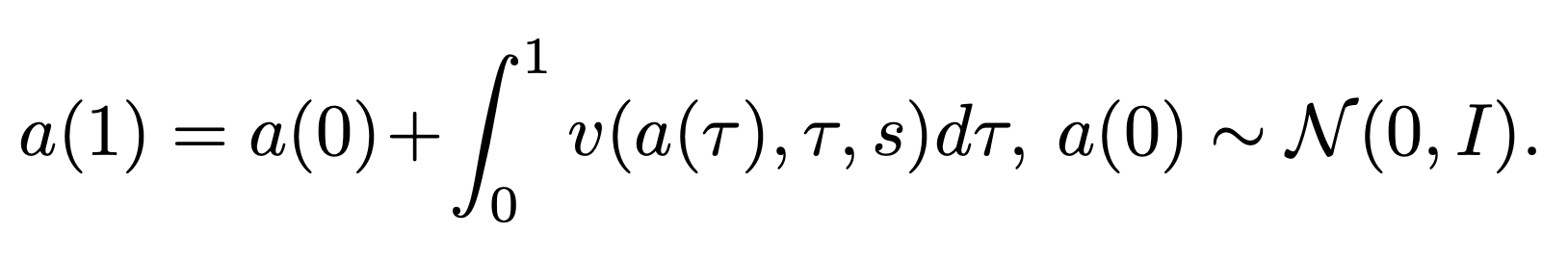
굳이 이를 “action 생성”으로 한정할 필요는 없다. 이는 CNF(Continuous Normalizing Flow)에서의 일반적인 생성 과정과 동일하게, 기저 분포(latent noise)에서 시작하여 연속시간 동역학을 통해 목표 분포의 샘플로 사상하는 문제로 이해할 수 있다.
그러나 CNF를 직접 사용하는 경우, 본질적으로 시간에 대한 연속적 적분이 필요하며, 이는 수치적 불안정성과 다단계 계산 비용을 수반한다. 한편, 이를 완화하기 위해 제안된 Flow Matching은 생성 모델링 관점에서는 효율적이지만, 이를 RL의 정책 학습에 적용할 경우 시간축을 따라 정의된 생성 경로에 대한 역전파(BPTT)가 요구되며, 이는 계산 복잡도와 메모리 측면에서 상당한 부담을 초래한다.
그러나 적분은 평균이다는 말을 어디서 들어봤다면, 적분값 자체를 optimize하면 되지 않을까 싶다. 본 논문은 그렇게 mean flow를 타겟팅하는 전략을 선택한다. 순간순간의 velocity field를 학습하는 것이 아닌, 특정한 인터벌까지 고려된 velocity field의 누적 변화량(적분) 자체를 타겟팅하는 것이다. 따라서 $t$ 시점의 순간적인 velocity field를 $v(a(t), t, s)$라 하면, time interval $[t,r]$에서의 mean velocity $u(a(t), t, r, s)$는 다음과 같이 정의된다:
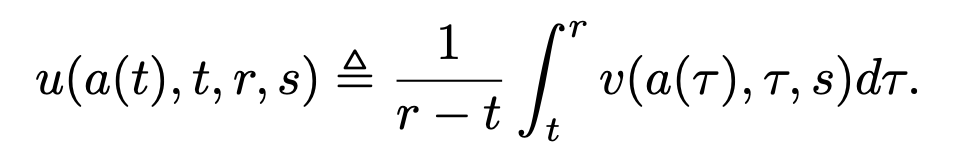
여기서 $u$는 학습 가능한 네트워크로, 보통 $u_\theta$로 부른다. 만약 이상적으로 학습이 잘 된 경우, 실제 action은 다음과 같은 형태가 된다:

이렇게 간단한 방법이 있다니~ 하면 진작에 잘 했으면 맨체스터 유나이티드 갔겠지 마인드마냥 생각할 것이다. 그러나 이 방법은 특별한 장치 없으면 제대로 사용할 수 없다. 그러한 특별한 장치를 알기 이전에, 어떻게 이 Mean flow matching이 학습되는지 알아보자.
$u$에 대한 앞선 정의를 다시 한 번 확인하고, 이를 time $t$에 대해서 미분하면 다음과 같은 식이 등장한다:

Instaneous velocity $v$는 $da(t)/dt$로 정의되며, 우리가 flow matching에서 배운 linear interpolation $a(t)=t\cdot a(1) + (1-t)\cdot a(0)$이므로 $v=a(1)-a(0)$가 된다. $u의 $t$에 대한 미분은 다음과 같이 정의된다:

Computation은 Jacobian-Vector Product로 action 변화와 time step의 변화에 따른 변화율을 계산함으로써 $O(n)$으로 계산할 수 있다. 따라서 mean-flow matching loss는 다음과 같다:

이렇게 action sampling 자체는 올바르게 할 수 있는 모델이 완성된다고 가정하자. 그런데 우리는 policy iteration을 통해서 policy 자체의 성능을 올려야 한다. 이에 대해서 논문은 다음과 같은 방식을 제시한다:

사실 간단하다. 여러 action을 샘플링하고, 그 중에서 가장 $Q$가 높은 action을 선택하여 policy를 업데이트하면 된다. 얼핏 보면 간단하지만, 논문에서는 이러한 방법이 policy improvement를 보장한다는 것을 제시한다:

여기서 $\Delta_N$은 best-of-N advantage gain이다. 더 자세한 증명은 논문의 appendix를 찾아보자.
이렇게 "이상적인 경우"에 policy가 실제로 성능이 향상될 수 있음을 알았다. 그러나 아까 설명했듯이 mean flow matching은 문제가 있다. (13)의 식에 있는 $\epsilon_A$는 mean flow matching으로 인한 오차에서 발생하는 항목이다. 이번에는 이 error가 왜 일어나는지에 대해서 알아보고, 이를 해결하고자 하는 instantaneous velocity constraint(IVC)에 대해서 알아보도록 하자.
Instantaneous Velocity Constraint

다음 Theroem을 확인하자:

식 (8)을 활용하여, 학습하고자 하는 $u_\theta$와 true mean velocity field $u^*$를 빼주면 $\Delta_u + (t-r)\frac{d}{dt}\Delta_u=0$이 되며, 이 형태를 풀어주고 적분하면 $(r-t)\Delta_u = C(a,r)$이 되고, $t$에 무관한 적분 상수 $C(a,r)$이 튀어나와 (16)과 같은 형태가 나오는 것이다. 따라서 $\Delta_u$는 유일한 값이 아닌 여러 값이 나올 수 있으며, 특히 더 문제가 되는 것은 $t\rightarrow r$일때 그 값이 발산한다는 것이다. 따라서 $t\approx r$의 경계 조건이 필수적이게 된다.


간단하지만 강력하다. $\Delta_v$의 norm을 bounded로 설정하면, $C(a,r)$이 반드시 0이 되어야 하는 조건으로 만족되어 $\Delta_v$도 0이 되고, 따라서 $\Delta_u$도 0이 된다. 따라서 경계조건 설정만으로 해의 유일성이 보장되는 결과가 나온다.
최종적으로 다음과 같은 loss로 policy가 학습된다:

알고리즘은 다음과 같다:

오해의 소지가 있어서 말하자면, offline Pre-training step에서는 best-of-N이 없다. From scratch을 하지 않고 바로 온라인으로 튜닝했을 때의 성능을 보고싶기는 한데 일단 이정도로만 이해하자(온라인 알고리즘이다! 근데 실험에서의 비교군이 너무 적어서 아쉽다).
Experiments
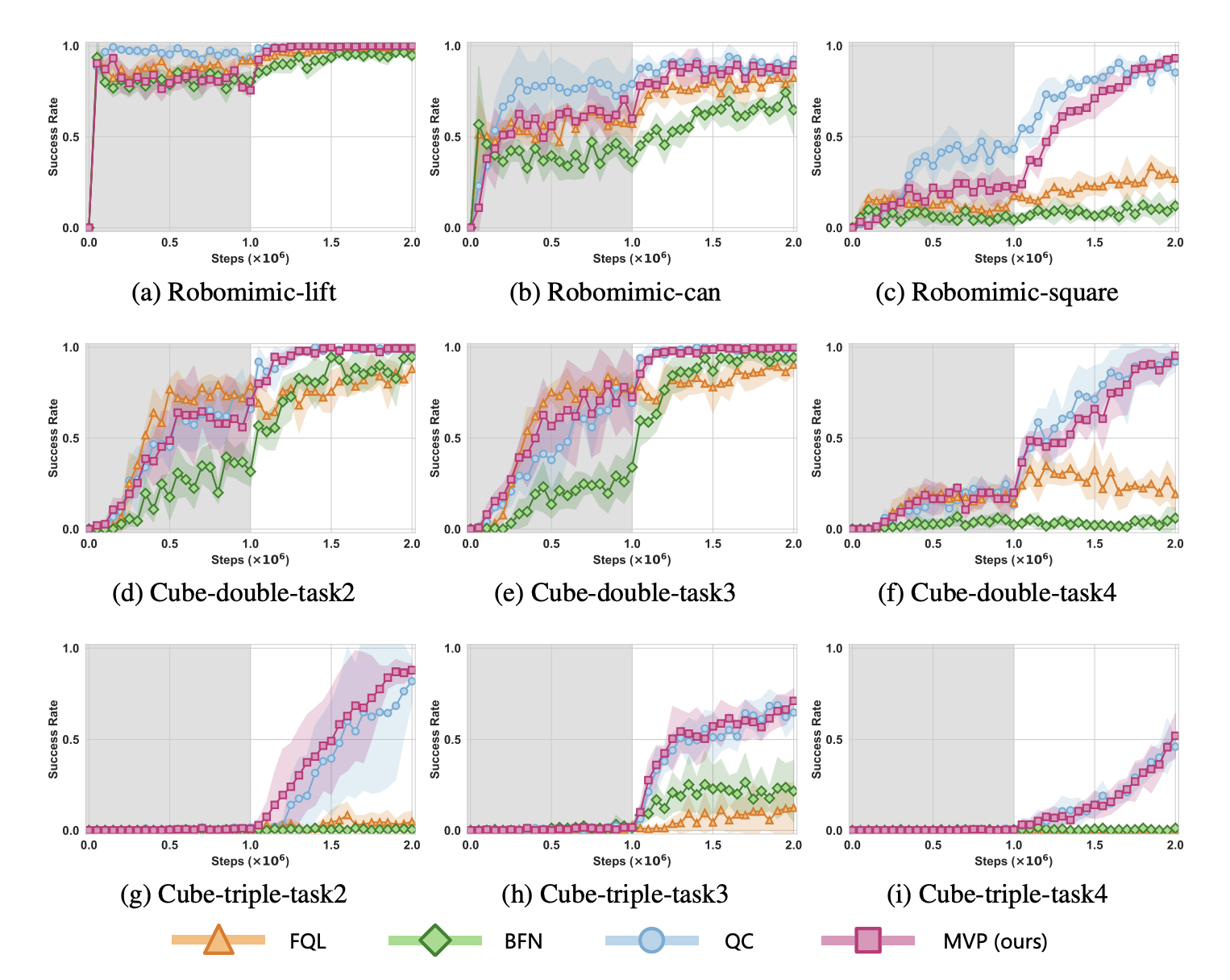
Offline-to-Online RL 알고리즘 간의 비교이다. 좋은 성능을 내는 것은 맞으나 솔직히 비교 대상 자체가 잘못되지 않았나 싶고, 온라인 알고리즘의 베이스라인 자체를 조금 두었으면 좋겠다는 생각이 있다.

IVC contraint hyperparameter에 대해서도 robust한 것을 알 수 있다. $\lambda=0$일 때도 학습이 잘 나오기는 하고, 실험을 다른 것을 돌려보지 않은 점이 흠이다. 그러면 Best-of-N 때문에 학습이 잘 된 것이 아닌가? 다만 이론적으로 해의 유일성을 보장하면서, BPTT 없이 flow policy를 만들었다는 것이 고무적인 점이라고 보면 될 것 같기도 하다.


먄약 실제 추론에서 best-of-N을 사용하지 않는다면 설득력 있는 자료이고, 아니면 설득력이 떨어지는 자료라고 본다. 다만 best-of-N을 쓰지 않고, 또 policy를 직접 적합시키지 않고 latent만 조정하는 방법론들이 있으니 실전 사용에서는 설득력이 있을 것 같기도 하다.
그리고 mean flow가 가지는 약점을 조금 더 이야기해보자면, 결국 generative modeling에서 쓰이지 않은 이유는 결국 평균에서의 유리함이지, pointwise에서 유리한 것은 아니라는 것이다. 근본적인 문제가 있는 것으로 보이지만 이에 대해 실험을 보이지 않은 것은 살짝 아쉬운 면이 있다.
아무튼 논문 리뷰는 여기서 마치도록 하겠다!