Summary
OpenVLA는 로봇 제어를 거창하게 새로 정의하기보다, 언어모델이 이미 잘 하는 일(다음 토큰 예측)로 최대한 끌고 온 접근이다. 입력은 “관측 이미지 + 자연어 지시”이고, 출력은 “로봇 행동(action)들의 문자열(토큰 시퀀스)”이다. 여기서 핵심 트릭은 로봇 행동이 본래 연속값(예: 이동/회전/그리퍼)인데, 이를 이산 토큰으로 바꿔서 LLM의 출력 공간에 얹는다는 점이다. 그러면 학습은 다시 익숙한 형태로 돌아간다. 행동 토큰에 대해서만 cross-entropy를 걸고, 표준 next-token prediction으로 훈련하면 된다.
재미있는 건, 이 설계가 “로봇 제어를 언어모델로 풀었다”기보다 “언어모델의 학습/인프라/스케일링을 로봇 제어에 가져오기 쉬운 형태로 바꿨다”는 데 더 가깝다는 점이다. 그래서 논문 전체가 “어떤 백본/이산화/토크나이저 처리/학습 레시피가 VLA를 만들 때 잘 먹히는가?”라는 실용적 질문에 집중한다.
Preliminaries
미리 알아야 하는 포인트들에 대해서 숙지하고 가자.
Vision-Language Model
최근의 VLM은 대체로 다음 3개의 블록으로 구성된다:
- Visual encoder: 이미지 → 패치 임베딩 시퀀스
- Projector: 시각 임베딩을 LLM 입력 공간으로 매핑
- LLM: 입력 토큰들을 바탕으로 다음 텍스트 토큰을 예측
훈련 목표는 보통 “다음 텍스트 토큰 예측”이다. 즉, 관측(이미지)와 프롬프트(텍스트)가 주어졌을 때, 모델이 다음 토큰의 확률을 맞춘다.
MDP?
로봇 시연(demonstration)은 환경과 상호작용하면서 나온 궤적 데이터다. 생성 과정 자체는 MDP로 모델링할 수 있다. 하지만 OpenVLA의 훈련은 보상/가치함수/벨만식 없이 시연 행동을 맞추는 지도학습(behavior cloning)에 가깝다.
즉, “배경은 제어 문제”인데 “학습은 imitation 방식”이다. 이걸 구분하지 않으면, 왜 tokenization이 그렇게 중요해지는지(=학습을 안정적으로 만들기 위해) 포인트를 놓치기 쉽다.
Discrete LLM vs Continuous Action
언어모델은 기본적으로 이산 vocabulary 위에서 작동한다. 반면 로봇은 연속 벡터인 경우가 많아, 이산 token → 연속 action으로 바꾸는 것이 VLA의 핵심 문제 중 하나이다.
생각해볼 수 있는 대안으로는, 이산 token을 연속 action으로 바꾸어주는 MLP를 새로 구성하거나, action 자체를 이산화하여 LLM의 next token prediction, 즉 classification의 문제로 치환하는 것이다. 본 논문은 후자를 다루는데, 전자의 경우 어떠한 문제가 있는지에 대해서 살펴보자.
Method

핵심 파이프라인을 우선 요약해보면 다음과 같다:
(이미지, 지시문) → LLM(input) → 행동 토큰 시퀀스(next-token prediction) → Action De-Tokenizer → 연속 행동 벡터
이를 조금 더 구조적으로 쓰면:
- 시각 인코더가 이미지에서 시각 토큰을 만든다.
- 지시문 텍스트 토큰과 시각 토큰이 LLM으로 들어간다.
- LLM이 행동 토큰을 “문장처럼” 생성한다.
- 행동 토큰을 연속 행동으로 복원해서 로봇에 보낸다.
Action-to-Token
본 논문은 각 행동 차원을 독립적으로, 256개의 bin 중 하나로 양자화한다. 즉, 행동 벡터의 각 컴포넌트별 1% 분위수와 99% 분위수를 설정한 후 균등 256등분, 이후 이산화(mapping)을 거친다.
시연 데이터에는 종종 이상치 행동(센서가 튀거나, 기록에 오류가 생기거나, 실패 궤적이 존재하거나)이 섞이기 때문에 min, max를 쓰면 그 몇 개가 전체 구간을 늘려버려서 자주 등장하는 행동 범위의 해상도가 떨어진다. 반면 quantile 기반은 “자주 쓰는 구간에 해상도를 집중”시키는 전략이기 때문에 이상치에 둔감한 경향이 있다.
Tokenizer Constraint → Overwrite
이산화로 차원마다 256개 토큰이 필요해진다. 그런데 Llama 토크나이저는 “새 special token”을 무한히 늘릴 수 있는 구조가 아니고, 예약된 수가 제한적이다. 그래서 OpenVLA는 단순화를 택한다. Llama vocabulary에서 거의 사용되지 않는 256개 토큰(마지막 256개)을 골라 그 토큰 id를 행동 토큰 의미로 overwrite한다. 원래 언어에서 거의 안 쓰이던 토큰의 의미를 포기하고, 그 슬롯을 행동 토큰으로 쓰면 언어 능력에 주는 부작용을 줄일 수 있다.
다만 질문은 남는다. 표현 공간이 왜곡(distort)되지는 않을까? 여기서 중요한 관점은 “덮어쓰기 = 공간 전체 파괴”가 아니라, 보통은 다음에 더 가깝다는 점이다.
- 새로운 행동 토큰들은 모델 내부에서 일종의 작은 하위 구조(서브스페이스)처럼 자리잡는다.
- 학습 손실이 행동 토큰 위치에서만 걸리므로, 업데이트도 주로 행동 토큰 및 그와 연결된 경로로 집중된다.
- 그래서 전체 언어 기능이 통째로 망가지기보다는, “행동 토큰을 다루는 회로가 추가/재배치”되는 쪽에 가깝다.
물론 이건 “항상 안전하다”는 뜻이 아니다. 파인튜닝을 얼마나 크게 하느냐(전체 튜닝 vs LoRA), 학습률, 데이터 프롬프트 구성에 따라 텍스트 능력의 미세 손실이 생길 여지는 있다. 하지만 논문은 택한 방향이 minimal한 방식임을 주장한다.
De-Tokenizer
행동 토큰을 연속 행동으로 바꿔주는 부분을 논문은 “action de-tokenizer”로 둔다. 여기서 오해가 생기기 쉬운데, 보통 이 모듈이 “큰 MLP로 똑똑하게 변환”하는 역할은 아니다. 대부분은 다음 중 하나다.
- Bin center lookup: 토큰 id → 해당 bin의 대표값(중앙값)
- Codebook lookup: 토큰 id → 미리 정해둔 코드북 벡터
즉, 디토크나이저는 대개 “복원기”이고, 결정은 LLM이 토큰을 선택하는 순간 이미 끝난다. 이 설계가 주는 장점은 명확하다. 연속 회귀를 직접 최적화하는 불안정함을 피하고, LLM이 잘하는 분류 학습으로 모든 걸 밀어 넣는다.
그러나 직관적으로, LLM은 이미 의미를 잘 아니까, 그 출력을 받아서 연속 행동만 잘 뽑는 작은 head만 학습하면 되지 않나?와 같은 생각이 든다. 충분히 타당한 생각이지만, 보통 로봇 조작에서 문제가 생긴다고 한다.
- 조작은 ‘무엇을’보다 ‘어디를/얼마나/어느 각도로/어느 타이밍에/얼마나 힘으로’가 더 빡세다.
- Frozen VLM의 표현은 대체로 semantic alignment에는 강하지만, 정밀 기하/접촉 국면(phase)을 head가 쉽게 읽어내기 좋은 형태로 제공하지 않을 수 있다.
- 결국 representation을 고정하면, “성공/실패 판단”, “힘 조절”, “접촉 전후 국면” 같은 것을 head나 reward로 떠안아야 하고, 그 순간부터는 학습이 점점 RL에 가까워지고(=credit assignment 문제), 설계 난이도가 급상승한다.
그래서 OpenVLA류 접근은 “차라리 LLM/VLM을 조금이라도 제어에 맞게 휘게 만들자”를 택한다. LoRA가 등장하는 이유도 이 지점이다. (전체를 다 바꾸기보다는 필요한 방향으로 최소한만 움직이려는 전략)
Vision Tokenizer
논문에서는 SigLIP와 DINOv2 특징을 함께 넣은 Prismatic을 사용한다. 이 두 이미지 토크나이저 모델은 다음과 같은 이유로 같이 쓰인다고 한다:
- SigLIP: 언어-시각 정렬(semantic grounding)에 강함
- DINOv2: 패치 수준의 공간 구조(spatial structure)가 더 또렷하게 남는 경향
즉 조작 과제는 목표 물체를 “알아보는 것”에서 끝나지 않고, “정확히 집는 것”이 핵심이라서 공간적 정밀도가 중요하다. 그래서 DINOv2 특징이 도움이 될 가능성이 크다. 추가적인 부분에 대해서는 Experiment에서 더 다뤄보도록 하겠다.
Experiments

우선 Robot manipulation에서 좋은 성능을 보이는 것을 확인할 수 있다.
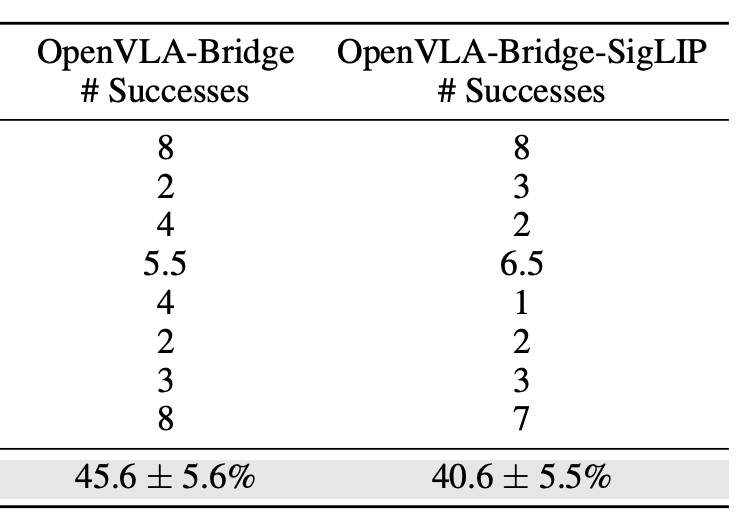
논문의 Table 9 일부를 가져왔다. SigLIP만 있는 경우에 성능이 떨어지는 것으로 보아 DINOv2의 필요성에 관한 설득력이 생긴다. 그러나 DINOv2가 없을 때의 실험도 한번 해봐야 하지 않나 싶은데, 이것은 살짝 아쉬운 부분이다.

Fine-tuning의 필요성을 보여준다. VLM의 hidden 기하 구조를 control-friendly하게 바꾸어줌을 알 수 있다. 다만 head만 따로 붙인 것도 실험에 있었으면 좋지 않았을까하는 생각은 있다.

이제서야 언급하기는 하는데... ㅎㅎ 논문에서 특히 강점으로 주장하는 것은, 개인 local computer로 충분히좋은 성능을 낼 수 있다는 것이다. 따라서 LoRA도 하고... Quantization도 하는 것인데, 성능이 잘 보존되는 것을 확인할 수 있다. 아래도 또 확인해보자:

이만 논문 리뷰는 여기서 마치도록 하겠다.