아이디어 자체가 복잡하거나 새로운 알고리즘적 기여가 큰 논문은 아니다.
대신, offline RL의 실패 원인을 꽤 깔끔한 관점으로 분해해서 보여준다는 점에서 가져올 만한 가치가 있다고 생각했다. 따라서 여기서는 논문의 전체 summary보다는, 이 논문이 어떤 문제를 지적하고 그것을 어떻게 바라보는지에 초점을 맞추어 정리하겠다.
Preliminaries
Offline RL의 핵심 문제는 결국 dataset support 바깥에 있는 action에 있다. 학습 과정에서 policy가 데이터셋에 충분히 존재하지 않는 행동을 선택하게 되면, 그 행동에 대한 Q-value는 실제보다 부정확하게 추정될 수 있다. 이는 본질적으로 extrapolation error, 즉 관측되지 않은 영역에서의 잘못된 일반화 문제이다.
이 잘못된 추정은 여러 형태로 나타날 수 있지만, 특히 위험한 경우는 OOD action에 대한 과대추정(overestimation) 이다. 이 경우 actor는 높은 Q-value를 따라 dataset support 바깥으로 더 멀리 이동하고, 그 결과 critic은 다시 더 신뢰하기 어려운 영역에서 값을 예측해야 하는 악순환이 발생한다.
한편, 문제를 단순히 overestimation으로만 볼 수는 없다. 설령 critic의 과대추정이 아주 크지 않더라도, actor가 dataset action으로부터 멀어진다면 critic은 여전히 support 밖 영역을 평가해야 한다. 따라서 offline RL에서는 (1) critic의 OOD value misestimation과 (2) actor의 support 이탈을 구분해서 보는 것이 중요하다. 우선 이 두 가지 상황에서 기존 방법론들의 접근법에 대해서 알아보자.
Action Regularization
TD3-BC[https://arxiv.org/pdf/2106.06860]가 대표적인 논문이다.
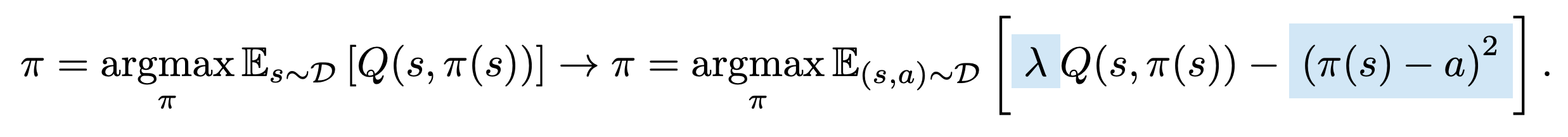
기존에는 actor가 Q를 maximize하는 구조이지만 dataset에 존재하지 않는 action을 하는 경우 패널티가 부여되어, reward maximization을 dataset 내부에서 할 수 있도록 유도하는 방식이다.
Value Regularization
Target Q에서, 만약 actor가 선택한 action과 dataset의 next action의 차이가 큰 경우 penalty를 주는 방식이다. 따라서 dataset에 없는 action에 대한 value를 낮추도록 유도하는 효과가 있다.
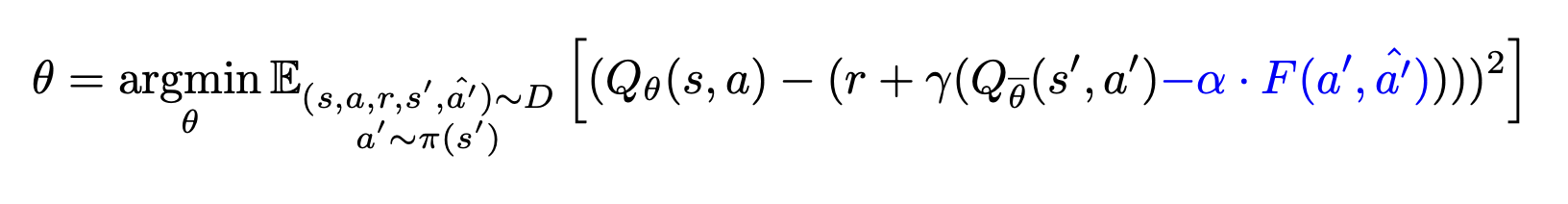
Behavior Regularized Actor Critic
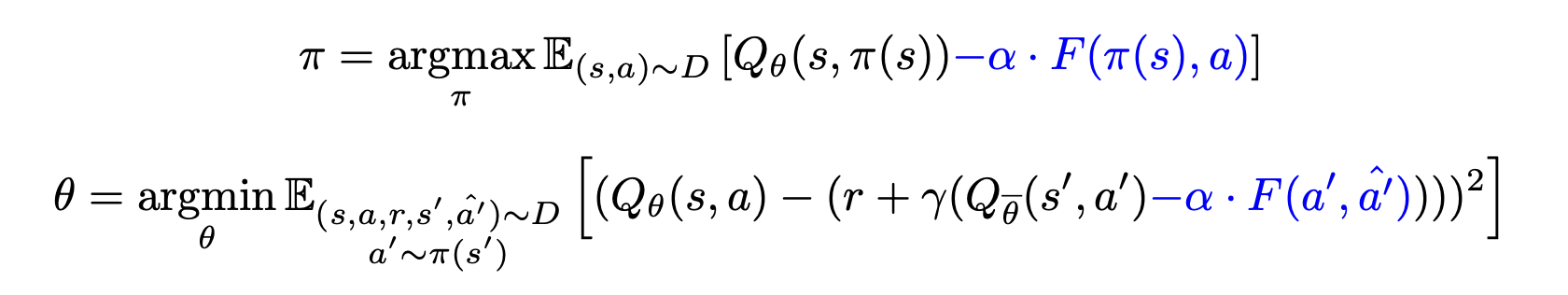
BRAC, 위의 두가지를 합친 방식이다. F에 대한 선택으로, KL divergence, Wasserstein, MMD 등 다양한 선택이 존재하지만 유의미한 결과를 얻지 못했다고 논문에서 밝힌다.
ReBRAC
논문은 BRAC 알고리즘의 핵심적인 한계를 다음과 같이 지적한다. 서로 다른 목적을 가지는 두 가지 regularization을 단일 coefficient로 묶어버렸다는 점이다. 앞서 살펴본 것처럼, 두 regularization은 역할이 다르다.
- Action regularization (actor penalty) → policy가 dataset support를 벗어나지 않도록 제어
- Value regularization (critic penalty) → OOD action에 대한 Q-value의 과대추정을 억제
이 둘은 겉보기에는 유사하지만, 실제로는 서로 다른 failure mode를 다루고 있다. 그럼에도 불구하고 BRAC에서는 이를 하나의 계수로 묶어서 제어한다. 이 구조에서는 다음과 같은 문제가 발생한다.
- actor를 강하게 묶고 싶으면 → critic도 같이 강하게 묶임
- critic의 overestimation을 줄이고 싶으면 → actor까지 과도하게 제한됨
즉, 두 문제를 사실은 독립적으로 조절해야 하는 문제임에도 그렇지 않은 접근을 한 것이며, 결국 하나의 trade-off로만 다뤄지게 되는 것이다. 이에 대한 ReBRAC의 아이디어는 단순하다. 이 두 regularization을 분리해서 각각 다른 계수로 제어하자는 것이다.
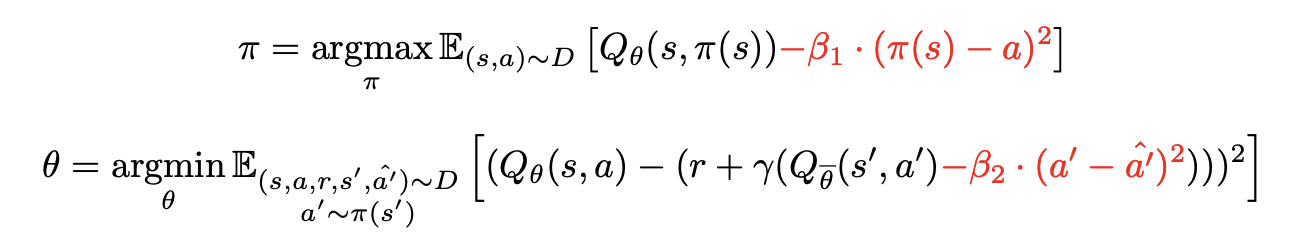
이러한 방식으로 다음과 같은 설정이 가능해진다:
- actor는 dataset support 근처에 유지하면서
- critic은 어느 정도 generalization을 허용하거나 (혹은 더 보수적으로 만들거나)
즉, 기존처럼 하나의 knob이 아니라 서로 다른 두 축에서 offline RL의 안정성을 조절할 수 있게 된다. 이러한 접근이 의미 있는 이유는, 앞서 언급한대로 offline RL의 문제를 두 축으로 분해하기 때문이다.

기존 방법들은 이 두 문제를 하나의 문제처럼 다루거나, 혹은 둘 중 하나만 해결하려고 한다는 문제점이 존재한다. 반면 ReBRAC는 support constraint 문제, value estimation 문제로 명확하게 나누고, 이를 각각 제어하도록 만든다.
Experiments

성능에 관한 statement는 짧게 하고, 결국 "무엇이 중요했는지"에 관한 실험을 보도록 하겠다:
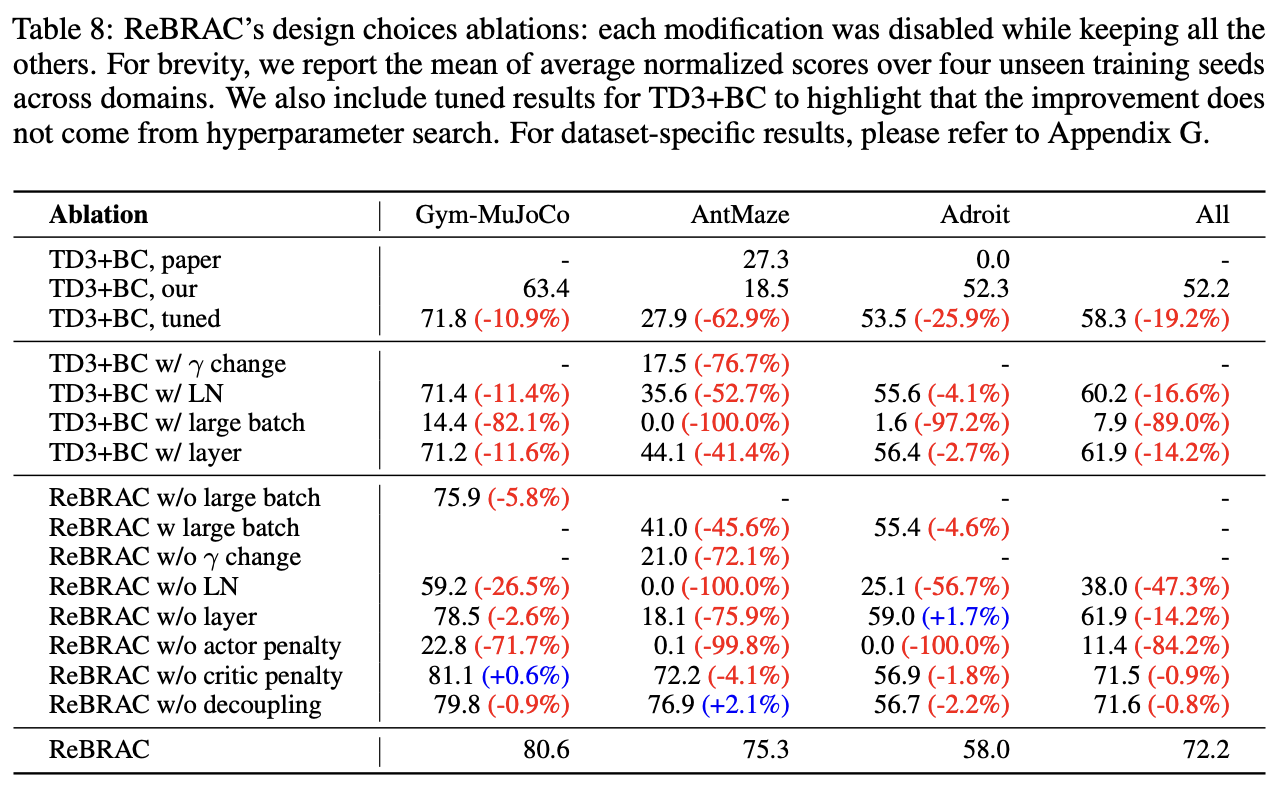
이 ablation 결과는 흥미로운 점을 보여준다. actor regularization을 제거하는 경우 성능이 거의 붕괴하는 반면, critic regularization이나 decoupling을 제거하는 경우에는 성능 저하가 상대적으로 크지 않다.
이는 offline RL에서 가장 본질적인 문제는 critic의 overestimation이라기보다는, policy가 dataset support를 벗어나는 것 자체임을 시사한다. 실제로 actor가 support 내부에 잘 머물도록만 제어해도, critic의 extrapolation error는 크게 문제가 되지 않을 수 있다.
따라서 ReBRAC의 decoupling은 중요한 개념적 정리를 제공하지만, 실질적인 안정성의 대부분은 actor regularization에서 비롯된다고 해석할 수 있다.