Summary
본 논문은 Offline RL을 Partial Optimal Transport 문제로 재해석하여, 데이터에 섞인 suboptimal expert 행동을 그대로 Behavior Cloning 복제하지 않고 좋은 행동의 부분집합만 골라(stitch) 정책을 추출하자는 방법을 제안한다.
Preliminaries
Partial Optimal Transport
본 논문에서는 다음과 같은 특수한 Optimal Transport(OT) 최적화 문제, Partial Optimal Transport를 다룬다:
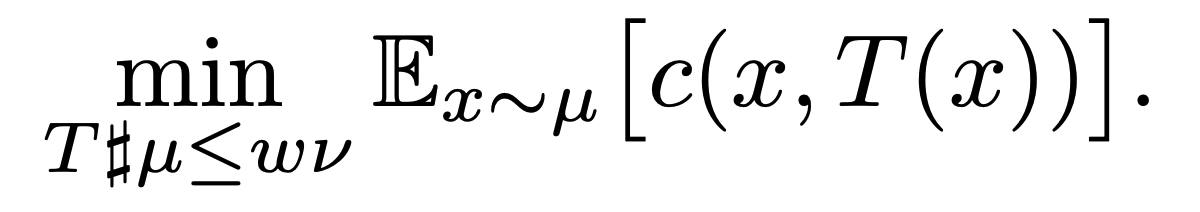
Monge와 형태가 살짝 다르다. Monge의 정확한 제약 term인 $T\sharp \mu = \nu$가 아닌 어떤 scale coefficient $w$가 곱해진 형태의 하한, 즉 $T\sharp \mu \leq w\nu$의 제약을 두는 형태이다. 즉 타깃 분포 $\nu$의 전체 질량을 맞추는 것이 아닌 $\nu$의 일부분, sub-measure에만 $\mu$를 수송하는 것을 허용한다.
이 제약은 Monge 문제와 구조적인 차이를 만든다. Monge OT는 $T\sharp \mu = \nu$가 강제되기 때문에, 입력 분포와 모든 질량이 타깃 분포 전체와 정확히 대응되어야 한다. 반면 위와 같은 부등식 제약에서는 비용 $c$에 따라 타깃 분포 $\nu$ 중 가장 유리한 부분만 선택적으로 매칭하는 것이 가능하다.
이러한 최적화 방법이 논문에서 활용된다. Offline RL에서 데이터는 그대로 따라하는 경우 전문가가 아닌 데이터도 섞여 있어 그대로 BC를 하면 sub-optimal하기 때문에 좋은 행동만 추출하자는 것에 대한 아이디어로 이러한 Partial OT를 사용하는 것이다. 우선 dual form이 어떻게 구축되는지 확인하고, 실제 method로 넘어가도록 하자.
부등식 제약을 함수 근사의 환경에서 다루는 것은 어렵기 때문에, dual을 도입한 최적화 문제로 변하게 된다. 우선 측도 부등식 제약 $T\sharp \mu \leq w\nu$이 dual로 변하는지 확인하자. 우선 임의의 함수 $f\geq 0$에 대하여
$$ \rho \leq \eta \Leftrightarrow \sup_{f\geq 0} \left(\int f d\rho - \int f d\eta \right) \leq 0 $$
이 성립한다. 증명은 어렵지 않지만 따로 다루지 않겠다.
이러한 사실을 partial Monge에 대입하면, 제약 $T\sharp \mu \leq w\nu$는
$$ \sup_{f\leq 0}\left(\int f(T(x)) d\mu(x) - w\int f(y)d\nu(y)\right) \leq 0 $$
와 동치가 된다. 즉, primal을 라그랑지안으로 쓰면
$$ \min_T \sup_{f\leq 0}\left[\int c(x,T(x))d\mu +\int f(T(x))d\mu(x)-w\int f(y) d\nu(y)\right] $$
가 된다. 이제 여기서 $f^c(x):=\inf_y \{c(x,y) - f(y)\}$로 정의하자. 그러면 모든 $x,y$에 대해서 항상 $f^c(x)+f(y)\leq c(x,y) $가 성립한다.
이제 $\int f^c(x) d\mu(x)$가 어떻게 $\inf_T \int c(x, T(x)) -f(T(x)) d\mu(x)$가 같아지는 조건이 필요하다. 바로 Normal Integrand이다. $c(x, y) -f(y)$가 $y$에 대해서 lower-semicontinuous이고 $x$에 대해서 measurable하며, 이 epigraph가 측정 가능해야 한다. 즉 점별 최소화 및 적분이 가능하며, measurable selection이 가능하면 Rockafellar interchange theorem에 의해서
Method
- Cost $c(x,y)$는 $-Q(s,a)$
- Transport map $T$는 $\pi(s)$
- Target 분포 $\nu$는 $\beta(\cdot | s)$, 즉 데이터가 제공하는 행동 후보 풀
- Source 분포는 $\mu$ $d^D(s)$
이다. 따라서 실제로 최적화하고자 하는 dual 형태는 다음과 같다:

Cost를 minimize, 즉 Q를 maximize하는 policy를 만들면서, 동시에 데이터셋 내부에 있는 선택을 하도록 제약을 내리는 것이다. $w$가 큰 경우, 데이터셋 내부에 있는 행동을 해야 한다는 제약이 커질 것이고 $w$가 작아지는 경우 Q maximization을 더 할 수 있도록 유도된다. 이런 제약 하에서, policy는 결과적으로 dataset support 내부에서 Q가 큰 action만을 선택하게 하여 expert data만 stitching할 수 있게 되는 것이다. GPT의 정리를 확인해주자:

이 방식의 장점은 크게 두 가지로 요약할 수 있다.
첫째, 기존의 BC/KL 기반 오프라인 RL 방법들과 달리, 본 방법은 행동 모방 강도를 조절하는 추가적인 하이퍼파라미터 $\alpha$ 를 필요로 하지 않는다. 전통적인 접근에서는
$$\max_\pi \;\mathbb E[Q(s,a)] \;-\; \alpha\,D(\pi(\cdot|s)\,\|\,\beta(\cdot|s))$$
와 같이 $\alpha$ 가 정책 개선과 안정성 사이의 균형을 직접적으로 제어한다. 반면, 본 논문에서는 정책 최적화 자체를 partial optimal transport 문제로 재정의함으로써, 행동 제약은 OT의 구조적 제약으로 암묵적으로 포함된다. 그 결과, BC를 위한 별도의 정규화 계수 없이도 정책은 데이터 분포의 지지집합(support) 안에서 자연스럽게 제한된다.
둘째, Wasserstein-1 기반 방법들과 달리, dual potential $f$ 에 대해 1-Lipschitz와 같은 강한 함수 제약이 요구되지 않는다. 본 논문에서의 $f$ 는 partial OT에서 등장하는 라그랑주 승수에 해당하며, 단지 $f \ge 0$ 이라는 비음성 제약만을 만족하면 된다. 이는 $f$ 가 거리 함수나 critic 역할을 하는 것이 아니라, 어떤 action이 선택 가능한지를 구분하는 선택 함수(selection potential) 로 작동하기 때문이다. 이러한 완화된 제약은 신경망 기반 근사에서의 학습 안정성과 구현 용이성을 크게 향상시킨다.
Pseudocode는 다음과 같다.

Experiments
본 논문은 실험에 앞서 state-action value function인 Q를 어떻게 학습할지에 관한 베이스라인을 정해둔다.
- PPL: 본 논문의 아이디어를 그대로 검증하기 위해, behavior policy와 그에 대한 Q function을 conservative하게 우선 학습하고, 고정된 Q 위애서 새로운 policy를 학습
- PPL-CQL: 사전학습 없이 CQL을 이용한 Q learning, 그리고 본 논문의 알고리즘 그대로 policy 학습
- PPL-R: TD3-BC 기반의 BRAC 오브젝티브를 cost(Q)로 사용, 즉 cost 자체가 $Q(s,a)-\alpha \| \pi(s) - a \|^2 $이다.
실험 결과는 다음과 같다:
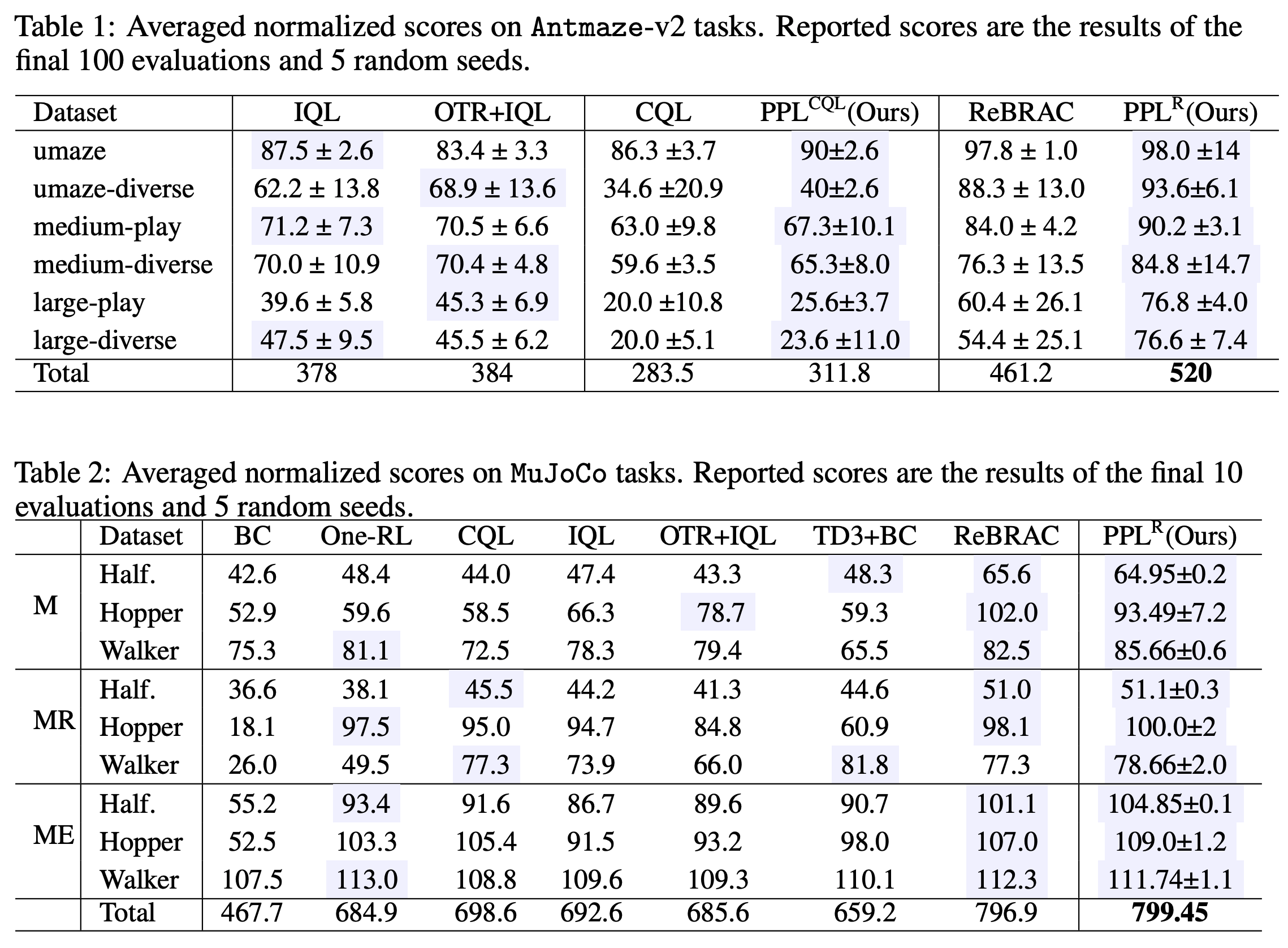
사실 요즘은 다른 method와 비교한 것의 결과를 보여주는 것은 그냥 그런갑다 한다 ㅋㅋ 잘나오니까 쓰겠지...

w 파라미터에 대한 결과이다. 전체적으로 w에 대해서 다 비슷한 성능을 내는 것울 보면 적당히 robust하다고 볼 수는 있다. 근데 보다보니까 왜 실험 때문에 논문이 한 번 reject되었는지 알 것 같기도... 뭔가 인사이트를 주기는 어려운 것 같다.
OT를 이렇게도 사용할 수 있구나 느꼈고, Partial OT에 대해서 새로 알게 되었고 특히 Offline RL에 잘 어울릴 것 같다. 이만 리뷰는 여기서 마치겠다.