Summary
Metric-Aware Abstraction (METRA)는 unsupervised skill discovery 문제를 “상태 공간 커버리지” 관점에서 재정의한 RL 방법이다. 기존의 unsupervised Goal-Conditioned RL(GCRL) 혹은 skill discovery 방법들은 Mutal information(MI)를 최대화하여 서로 다른 skill들을 분리하는 데 집중했으나, 이 접근은 skill 간 분리 자체는 잘 되어도 거리를 반영한 분리를 보장하지 못한다는 한계를 가진다. 또한 skill discovery를 위한 state 간 거리를 측정하는 방법이 유클리디안으로 제한되어 있어, scalable하지 않다는 문제점이 있다.
METRA는 이 문제를 두 가지 새로운 방법을 도입함으로써 해결한다. 첫 번째는 Wasserstein Dependency Measure(WDM)으로 MI를 대체하는 것이고, 두 번째는 distance metric으로 temporal distance를 사용한다는 것이다.
이러한 주요 방법을 통해서 METRA는 명시적인 goal 없이도 다양한 locomotion behavior를 발견할 수 있으며, 학습된 representation을 이용해 zero-shot goal-reaching까지 가능함을 보인다. 특히 pixel-based Quadruped / Humanoid 환경에서 unsupervised locomotion skill discovery를 달성한 최초의 방법이라는 점에서 의미가 있다.
Preliminaries

우선 Pure Exploration 계열 방법은 명시적인 목표나 구조 없이 상태 공간을 무작위로 탐험하는 방식인데, 상태 공간이 커질수록 의미 있는 상태를 발견할 확률이 급격히 감소한다. 고차원 환경에서는 이 접근이 사실상 확률적 우연에 의존하는 탐색, 즉 비효율적인 샘플링 문제로 귀결된다.
이러한 한계를 극복하기 위해, 기존 연구들은 agent의 행동을 보다 의도적으로 분산(diversify) 시키는 방향으로 발전해왔다. 대표적인 접근이 Mutual Information(MI) 기반 skill discovery로, latent skill과 state 간의 MI를 최대화함으로써 서로 다른 행동 양식을 학습하도록 유도한다. 이 방식은 skill 간 구분(separation) 은 잘 달성하지만, 상태 공간을 얼마나 “멀리” 탐험했는지에 대한 고려는 포함하지 않는다는 한계를 가진다.
그 이유는 MI가 본질적으로 KL divergence에 기반하기 때문이다. KL은 두 분포가 얼마나 다른지를 측정할 뿐, 그 차이가 기하적으로 얼마나 떨어져 있는지에 대해서는 전혀 반응하지 않는다. 결과적으로 MI 기반 방법들은 서로 다른 skill이 각도만 다를 뿐, 실제로는 상태 공간의 좁은 영역에 밀집된 행동들을 학습하는 경향을 보인다. 즉, skill diversity는 확보되지만, state coverage는 제한된다.

본 논문은 이러한 관점에서, unsupervised RL이 scale에 실패하는 핵심 원인을 "분리는 되지만 확장은 되지 않는" 점에 집중한다. 따라서 이 문제를 해결하기 위해서 metric-aware인 Wasserstein 기반 measure와 temporal distance를 도입한다.
Method
우선 Wasserstein Dependency Measure에 기반한 최적화이다.

Mutal information에 있는 KL divergence를 Wasserstein으로 치환한 것이고, 해당 형태는 다음과 같다:

Kantorovich-Rubenstein duality에 의해서 이 optimization식은 비교적 단순한 아래의 형태로 표현된다:

여기서 $f:\mathcal{S}\times\mathcal{Z}\rightarrow\mathbb{R}$는 1-Lipschitz constraint를 만족하는 함수, 즉
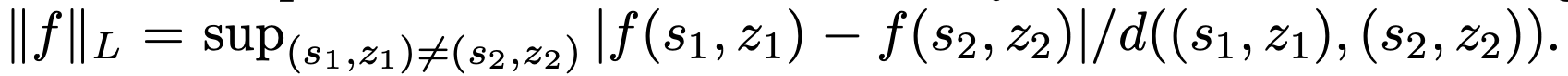
이다. 본 논문에서는 이 함수 $f$를 $f(s,z)=\phi(s)^\top \psi(z) $로 parameterize하며, 이때 $\phi(s)$는 state를 embedding space로 project하는 함수이며, $\psi(z)$는 goal condition을 embedding space로 project하는 함수이다. 이상적인 경우에 $f$는 state가 goal condition과 얼마나 매치되는지를 가리키는 함수여야 하지만, 이를 직접적으로 parameterize하는 것은 사실상 불가능에 가깝다. 따라서 두 임베딩 모델의 내적으로, 즉 bilinear 형태로 두는 것이 실질적인 구현에 더욱 단순하며 학습 안정성 및 확장성에 더 유리하다.

결국 위와 같은 형태로 목적함수가 도출되며, 본 논문에서는 $f$로 parameterize된 목적 함수와 relaxization된 목적 함수의 차이를 일정한 조건에서 epsilon 범위 아래로 둘 수 있음을 보였으니 한번 확인해보면 좋을 것 같다.
여기서 한 개 더 주목할 점은, Wasserstein MI에서 terminal state와 goal condition을 비교하는 것이 중요하다는 것이다. 결론적으로 아래의 (5)번 식에서 (6)번 식으로 telescopic term으로 전개가 되며,
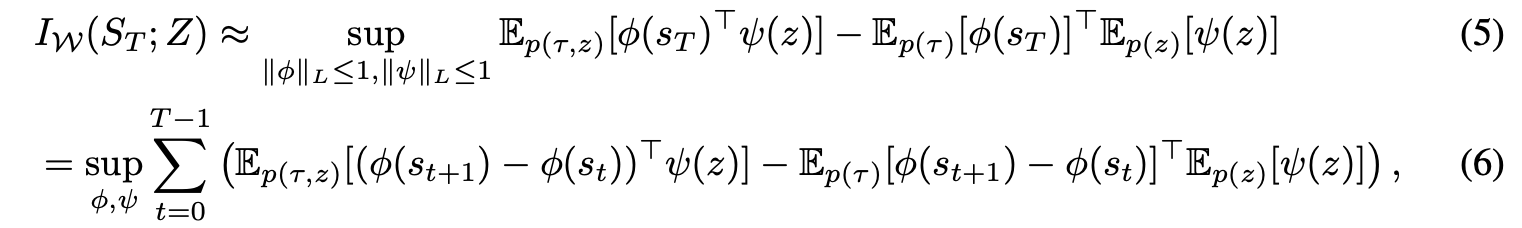
최종적으로 다음과 같은 형태가 됨을 알 수 있다.

여기서 $\psi(z)=z$로 두는 이유는, 목적함수를 크게 단순화하기 위해서이며 (7)번의 식으로 유도할 수 있기 위함이다. $r(s,z,s')=(\phi(s)-\phi(s'))^\top z$는, skill $z$를 주었을 때 상태가 latent space에서 $z$방향으로 이동하면 보상을 주는 것으로 전이 방향과 latent direction의 정렬만이 학습 신호가 되는 것이다.
이러한 과정을 거치면서, WDM의 복잡한 dual form이나 추가적인 장치 없이 단순한 형태로 Wasserstein MI를 최대화할 수 있게 되는 것이다. 우선 full objective를 보면서 temporal distance가 어디서 나타나는지 확인해보자.

Temporal distance는 한 state에서 다른 state로 가기 위해 움직여야 하는 단위를 의미한다. State 이동이 forward, backward가 다를 수 있으니 대칭되지 않는 형태를 가지고 있는데, 이는 Unsupervised Skill Discovery에서 합리적인 선택지로 보인다. 그러나 분명 temporal distance로 제약을 걸었다고 하는데 그러한 제약이 어디에도 안보인다.
바로 $\|\phi(s)-\phi(s')\|$에 있다. 인접 상태에 대해서는 temporal distance가 반드시 1이니, Lipscitz constraint를 만족하려면 $\|\phi(s)-\phi(s')\|\leq 1$이 되는 것이다. 이것을 이해한 상태로 objective를 다시 봐보자. 그러면 아래의 항

은 한 스텝에서 허용된 최대 이동량을 1로 제약을 둔 상태에서, 그 스텝을 여러 번 누적한 것의 alignment의 합을 구하는 것이다. 이론적으로 temporal distance를 global 제약으로 걸어두는 것이 더 정직하지만, 논문에서는 local constraint으로 단순한 설계를 두면서, 동시에 그 로컬 제약이 글로벌하게 효과를 주는 결과를 가져오게 한 것이다.

알고리즘도 확인해보도록 하자. 추가적인 좋은 내용들도 있는데 다는 다루지 못하지만... 직접 확인해보면 좋을 것 같다.
Experiments

METRA가 다른 방법들에 비해서 우수한 성능을 도달한 것을 확인할 수 있다. 본 논문의 방법론이 state coverage도 높으며, downstream task에서도 좋은 성능을 가져오는 것을 확인할 수 있다.

Limitations
논문에서 언급한 한계에 대해서 살펴보고 가자.


사실 아까 method 설명할 때 똑똑하신 분들은 그래도 왜 L2 distance지? 했을 것이다. 실제로도 본 논문에서 정직하게 그 문제를 인정하며, 그러나 대부분의 벤치마크에서는 전이가 대칭적이어서 큰 문제가 아니라고 명시한다. 그럼에도 대안으로 asymmetric quasimetric을 사용해볼 수 있음을 언급한다.
$\psi(z)=z$로 latent space에서 선형 이동만 고려하는 것도 구현상의 편의에 의한 것이지만, 이 또한 문제라고는 언급한다. 그러나 논문을 보는 내 입장에서는 다른 대안이 없지 않을까...싶다.
아무튼 논문 리뷰는 여기서 마무리하도록 하겠다. Wasserstein metric을 어떻게 practical하게 다루는지에 대한 균형 잡힌 논문인 것 같다.
'논문 리뷰 > RL' 카테고리의 다른 글
| Rethinking Optimal Transport in Offline Reinforcement Learning 논문 리뷰 (0) | 2026.02.07 |
|---|---|
| Steering Your Diffusion Policy with Latent Space Reinforcement Learning 논문 리뷰 (0) | 2026.02.05 |
| Diffusion Policies Creating a Trust Region for Offline Reinforcement Learning 논문 리뷰 (0) | 2026.01.31 |
| Flow Q-Learning 논문 리뷰 (0) | 2026.01.28 |
| Prioritized Generative Replay 논문 리뷰 (1) | 2026.01.25 |