PRIORITIZED GENERATIVE REPLAY
이번에는 Summary 없이 내가 서술하고 싶은대로 가보도록 하겠다. 아키텍처로 어떤 것을 했는지보다, 조금 철학적(?)인 내용일 것이다. 우선 이 논문을 이해하기 위한 기본적인 개념들에 대해 숙지해보자.
Preliminary
Replay Buffer
Replay Buffer는 Deep RL의 출발점이라 할 수 있는 DQN에서 등장한 대표적인 개념 중 하나이다. 단순히 경험을 저장하는 장치를 넘어, 강화학습이 안정적으로 동작하기 위해 거의 필수적인 구성요소라고 볼 수 있다. Replay Buffer는 크게 두 가지 문제를 해결하기 위해 도입되었다.
첫 번째는 trajectory correlation 문제이다.
MDP 가정에 따르면 현재 state와 action은 오직 직전 시점의 state에만 의존해야 하며, 환경은 stationary하다고 가정된다. 그러나 실제 강화학습 환경에서는 모든 상태를 완전히 관측할 수 없는 경우가 많고, 정책 또한 학습 과정에서 지속적으로 변화한다. 이러한 상황에서 trajectory를 시간 순서 그대로 사용해 학습하면, 에이전트가 인식하는 데이터 분포는 사실상 non-stationary가 되며, 그 결과 학습이 매우 불안정해진다.
Replay Buffer는 이 문제를 단순하지만 효과적인 방식으로 완화한다. 하나의 trajectory를 그대로 사용하지 않고, 이를 (s, a, r, s') 형태의 전이 단위로 쪼개어 저장한 뒤, 이 전이들을 무작위로 샘플링하여 학습에 사용한다. 이 과정에서 의도적으로 시간적 상관관계(trajectory correlation)를 끊어주게 되며, 결과적으로 학습 안정성이 크게 향상된다. 즉, Replay Buffer는 강화학습 문제를 보다 MDP 가정에 가깝게 만들어주는 역할을 한다.
두 번째는 sample efficiency 문제이다.
직관적으로 보면 정책 업데이트는 현재 상태에서 행동의 확률분포만 바꾸는 것처럼 보이지만, 실제로는 그렇지 않다. 정책이 바뀌면 에이전트가 앞으로 방문하게 될 경로 자체가 달라지며, 이는 데이터 분포의 변화로 이어진다. 이 관점에서 보면 원칙적으로는 과거 정책으로 수집한 데이터를 현재 정책 학습에 사용하는 것이 이론적으로 맞지 않는다.
하지만 매 환경 상호작용에서 얻은 샘플을 한 번만 사용하고 버린다면, 샘플 효율성은 극도로 낮아진다. 이는 현실적인 강화학습 설정에서 감당하기 어렵다. Replay Buffer는 이 딜레마에 대한 실용적인 타협안이다. 오래된 데이터를 점진적으로 제거하면서도, 저장된 데이터를 여러 번 재사용할 수 있도록 함으로써 학습 효율을 크게 높인다. 이 과정에서 앞서 언급한 trajectory correlation 완화 효과까지 함께 얻을 수 있다.
Problems
그러나 이 개념 자체가 완벽한 것은 아니다. Sampling distribution은 uniform한 것은, 물론 이미 이전 데이터를 replay buffer에 꺼내서 학습하는 것 자체가 이론적으로 올바르지는 않지만, 문제가 될만한 예시를 쉽게 생각해낼 수 있다. 과연 많이 관측되고, 행동이 잘 정립된 state를 학습하는 것이 그렇지 않은 state와 똑같이 취급받는 것이 상식적으로 올바르지는 않다. 직관적으로 보면, 우리는 이미 쉽게 푼 문제들은 더 많이 보지 않고 어려웠던 문제들 위주로 풀면서 지식을 늘린다.
그래서 이렇게 잘 하지 못한 것들에 대한 샘플링 가중치를 높이는 것이 하나의 방법이 될 수 있다. 그것이 유명한 PER(Prioritized Experience Replay)이다. PER은 TD error을 기반으로, TD error가 높은 state-action pair에 대한 sampling 확률을 높여주어 모델이 더 자주 학습될 수 있도록 유도한다.
하지만 이 방법도 문제가 있다. 애초에 replay buffer의 trajectory distribution은 현재 정책 policy가 생성할 수 있는 trajectory와 다르다. 여기서 확률을 더 꺾어준다면, policy가 잘못된 방향으로 학습할 가능성이 높다. TD error가 큰 희귀 전이들이 반복적으로 재사용되면서 모델이 해당 전이들을 사실상 암기(overfitting)하게 된다는 점이다. 이 경우 학습은 전이 공간의 넓은 영역을 고르게 탐색하지 못하고, 소수의 고우선순위 전이에 과도하게 집중하게 된다.
물론 importance weighting을 통해 샘플링 편향에 대한 일정 수준의 보정을 시도할 수는 있다. 그러나 이러한 보정은 기대값 수준의 편향을 완화할 뿐, 희귀 전이가 과도하게 반복 노출되면서 발생하는 분포 다양성 감소와 표현 과적합 문제 자체를 근본적으로 막지는 못한다.
즉, PER은 ‘어떤 전이를 더 자주 볼 것인가’에 대한 해법은 제시하지만, 그 과정에서 발생하는 분포 붕괴와 일반화 저하의 위험까지 완전히 해결하지는 못한다.
Prioritized Generative Replay

두 핵심 단어만 우선 숙지해보자.
- Relevance: 어떤 데이터 (s, a, r, s')이 현재 정책을 더 빠르고 의미 있게 바꾸는 데 얼마나 도움이 되는가를 나타내는 정도다.
- Frontier:현재 정책의 숙련도 관점에서 아직 완전히 정복되지 않은 경계 영역이다. 즉 안 가본 곳이나, 희귀한 곳의 개념이 아닌 잘 정립되지 않은 영역이라고 보는 것이 정확하다.
본 논문의 진짜 목표는 다음과 같다: Frontier에서 policy를 잘 정립시키기 위해서, 그것이 frontier인지에 대해서 판단하는 것으로 relevance 지표를 사용하는 것이다. 그러나 Relevance 지표는 사실 사전적으로 알 수 없다. 따라서 그것을 "미리" 판단할 수 있는 proxy 지표를 두어야 할 필요가 있다. 논문에서는 proxy로 Q function(엄밀하게는 $Q(s,\pi(s))$), TD error, Curosity를 사용한다.
여기까지는 PER과 다를 것이 솔직하게 없다. 이제 PGR에서 어떻게 접근했는지 알아보자.

알고리즘만 가져왔다. 우리가 아는 일반적인 replay buffer만 있는 것이 아니라 합성 데이터 replay buffer도 존재한다. 처음에는 policy가 rollout을 하면서 replay buffer을 채운다. 그 다음에는 그 replay buffer에서 나오는 sample들에 대한 relevance를 체크해서, relevance가 큰 데이터에 대해서 합성 데이터를 생성하고, 그것을 합성 replay buffer에 넣어준다. 이후 모델이 학습할 떄에는 일정 비율로 실제 데이터와 합성 데이터가 섞인 replay buffer에서 샘플링을 진행하기 때문에 relevance가 큰 데이터에 대해서 더 많은 샘플링이 자연스럽게 되는 것이다.
생성 모델에 관한 것은 다음을 참고하자.

좋은 선택지이다. Relevance가 높은 것에 대해서 샘플링을 할 수 있어야 하기 때문에, 그 정도를 조절해서 생성할 수 있도록 CFG를 두는 것이 합리적이라고 볼 수 있다.
Experiments
이 논문이 ICLR 2025 Oral에 들어간 이유인 실험 같다. 우선 기존 baseline에 비해서 성능이 향상된 것을 확인할 수 있으며, 방법론이 데이터의 type에 무관한 것을 볼 수 있다.
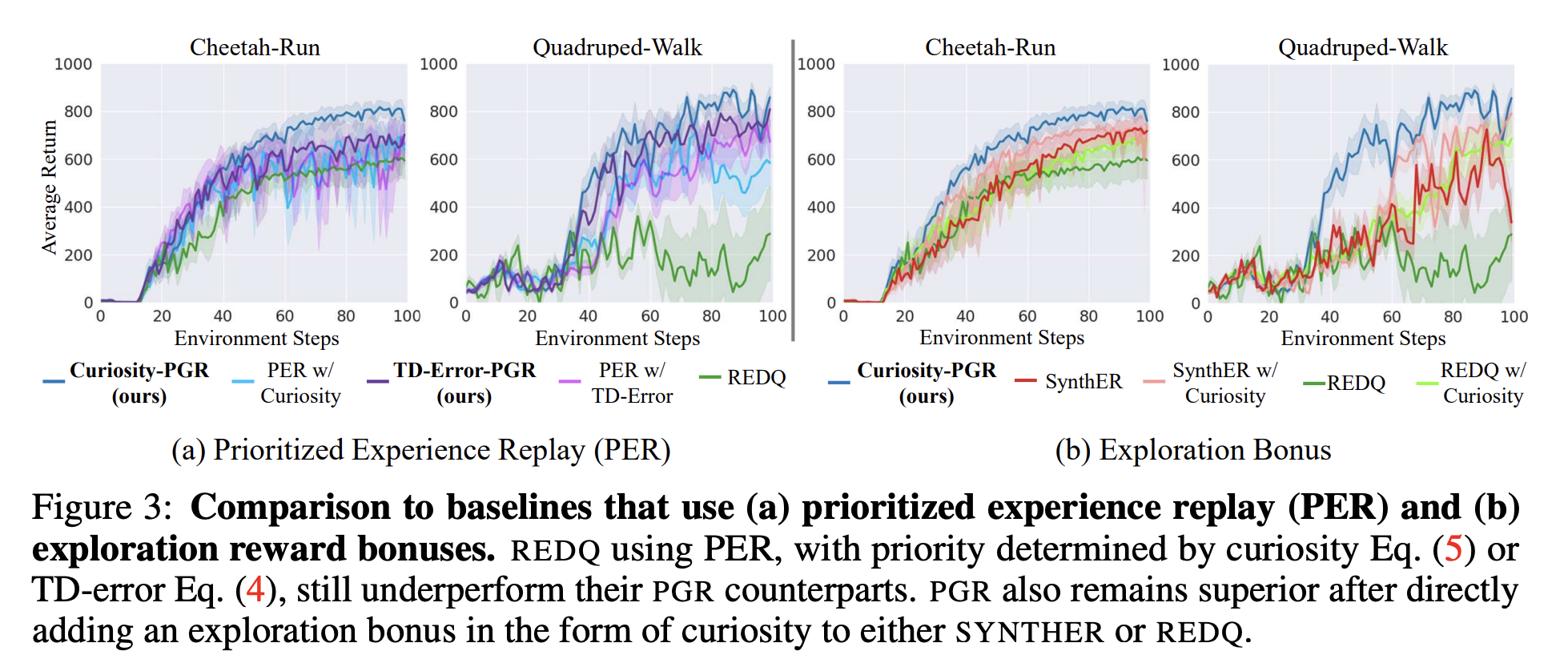

나머지는 논문을 참고하시면 된다...ㅎㅎ
PER보다 더 나을 수 있는 이유는, 그러한 relevance에 대해서 몇 개의 동일한 데이터를 여러 번 보여주는 것보다, 생성까지 해서 유사하지만 smooth한 데이터를 여러 번 보여주는 것이 조금 더 overfitting에도 안전하며, 또한 interpolation, extrapolation에 강해지기 때문이다.
Limitations
그러면 PER의 문제점을 다 해결했는가? 아니다. 근본적으로 Frontier == Relevance 자체가 문제다. Frontier != Relevance인 것의 예시로, 행동이 정립되지 않았지만 애초에 그 영역은 처음부터 구린 영역이라 가면 안되는 경우를 볼 수 있다. 따라서 처음부터 이러한 설정 자체가 문제라고 볼 수 있다.
Relevance의 proxy도 문제다. Relevance == Proxy가 되지 않는다. 만약에 TD error가 정말 학습을 덜 해서 추정을 잘 못한 것이 아니라, 그냥 noise 때문이라면? PER도 사실 같은 문제를 가지고 있는데 이것을 해결하지는 않는다.
칭찬은 그 전에 다 한거같으니... 이만 논문 리뷰를 마무리하도록 하겠다.
'논문 리뷰 > RL' 카테고리의 다른 글
| Diffusion Policies Creating a Trust Region for Offline Reinforcement Learning 논문 리뷰 (0) | 2026.01.31 |
|---|---|
| Flow Q-Learning 논문 리뷰 (0) | 2026.01.28 |
| TD3-BC 논문 리뷰 (1) | 2026.01.21 |
| FEDORA 논문 리뷰 (0) | 2026.01.13 |
| PlaNet 논문 리뷰 (0) | 2025.12.17 |