요즘은 flow/diffusion 기반 policy에 계속 관심이 쏠린다. RL에 쓸 수 있는 데이터가 빠르게 늘어나면서, 앞으로는 멀티모달한 행동을 “잘” 다루는 능력이 더 중요해질 가능성이 크다. 그런 흐름 속에서 flow/diffusion 기반 정책이 활발히 연구되고, 실제 로봇 조작(manipulation)에서도 효과가 점점 더 많이 확인되는 느낌이다. 관심 있는 독자라면 Physical Intelligence (PI)에서 올리는 글들도 종종 찾아보면 좋다. 예를 들어 Moravec’s Paradox and the Robot Olympics는 최신 모델을 파인튜닝해 난이도 높은 조작 과제들을 해결한 과정을 꽤 흥미롭게 정리해둔다.
Moravec's Paradox and the Robot Olympics
By fine-tuning our latest model, we were able to solve a series of very difficult manipulation challenge tasks.
www.pi.website
아무튼 그렇게 diffusion/flow policy가 BC(behavior cloning)로 잘 먹히기는 하는데, 늘 현실적인 문제는 존재한다.
우선 BC로 학습한 정책이 "대충"은 잘 따라 하는데, 실제 환경에서 적용하면 성공률이 높지 않기 때문에 개선이 필요할 때가 많다. 그럴 때 시연 데이터 더 달라고 하는 것도 무리고, 그렇다고 RL로 파인튜닝하는 것은 online에서 위험도도 크고 특히 diffusion/flow policy는 그 자체로 사용하는 경우 BPTT라는 악명 높은 불안정성과 마주해야 한다.
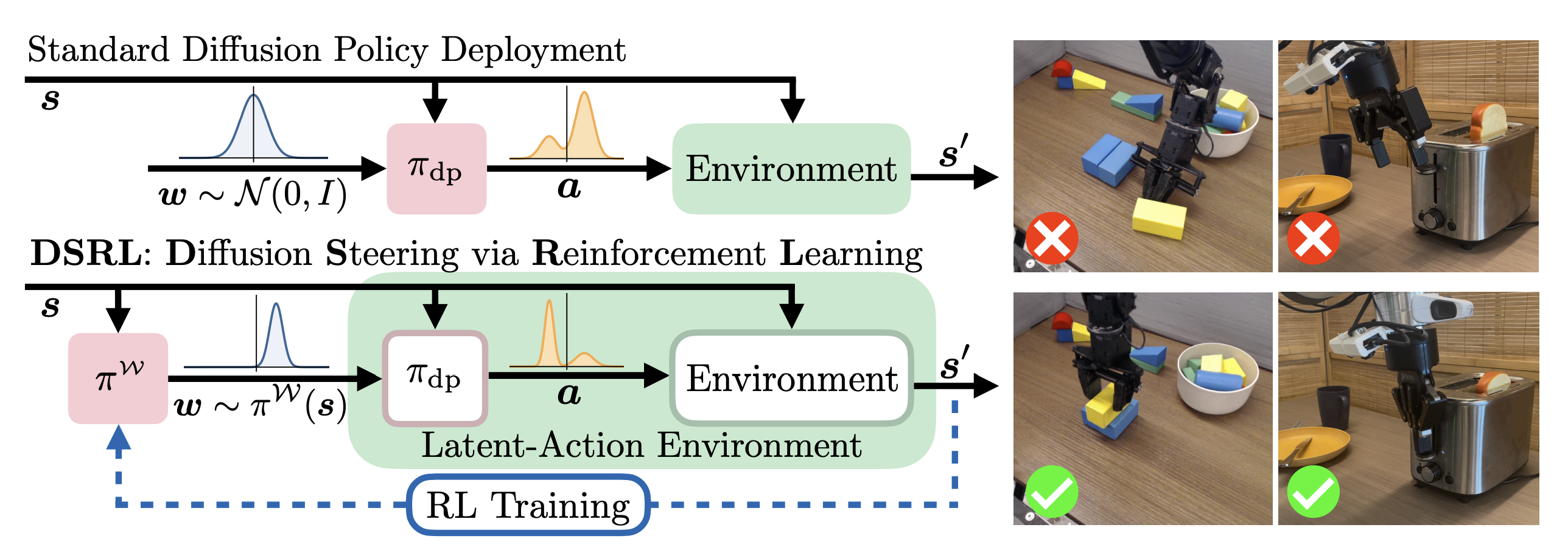
여기서 DSRL(Diffusion Policy with Latent Space)가 제공하는 아이디어가 인상적이다. 바로 정책 가중치(네트워크)를 건드리지 말고, 샘플링 입력(latent noise)만 최적화하자는 것이다. State와 latent만 받아서 action을 출력하는 policy에 대해서, 그 내부 네트워크를 직접 건드리지 말고 "제어 가능한 input"인 latent에 대한 튜닝을 적용하자는 것이 기본적인 아이디어이다.
Method
원래의 MDP가 $M=(S,A,P,r,\gamma)$라 하자. Diffusion/flow BC policy는 다음과 같은 형태이다:
$$ a = \pi_{\text{dp}}(s,w), w\sim\mathcal{N}(0,I) $$
여기서 재해석을 해보면, 우리가 실제로 환경에 던지는 것은 action $a$이지만 사실 내가 고른 것은 latent $w$라고 볼 수 있다. 왜냐하면 $w$만 정하면 $\pi_{\text{dp}}$가 그 action을 만들어 주기 때문이다. 따라서 원래의 MDP가 아닌 변환된 MDP를 만들어줄 수 있다:
$$M^W = (S,W,P^W, r^W, \gamma) $$
여기서 $P^W(\cdot | s,w)=P(\cdot |s,\pi_{\text{dp}}(s,w))$, $r^W(s,w)=r(s,\pi_{\text{dp}}(s,w))$이다. 즉 기존의 action space에서 action을 뽑아내고, 그에 따라서 변화하는 dynamics와 reward가, 그 action을 선택하는 latent에서 비롯된 dynamics와 reward가 새롭게 정의될 수 있는 것이다. (엄밀하지 않은 말이기는 한데 일단 의미상 통하면 될 것 같다)
따라서 위의 그림처럼, Environment의 범위가 diffusion/flow policy에게 인풋을 넣어주는 것까지 확장되는 것이다. 이렇게 하면 actor-critic에서 policy gradient가 아름답게 정의될 수 있을 것 같이 보인다. 논문에서 추가로 언급하는 이 방법의 장점은, BC policy를 API처럼 둘 수 있다는 것이다. 무엇이든 할 수 있는 foundation BC policy를 가정하고 우리가 원하는 행동만 하도록 latent만 조정해도 될 것이다.
하지만 이렇다고 문제가 없는 것은 아니다. 첫 번째 문제는 actor-critic 구조에서 나오고, 두 번째는 offline RL에서 나온다. 이 문제를 논문에서 어떻게 해결하고자 하는지 알아보자.
우선 표준적인 actor-critic이 보는 세계는 서로 다른 action은 서로 다른 것으로 취급한다는 것이다. 너무나도 당연한 말이다. 그러나 latent가 1차적 action이 된 이 새로운 MDP 세계에서는, state → latent → action의 chain을 거치게 된다. 그러다보니 사실 선택하는 두 1차 action $w_1$과 $w_2$가 다르더라도, 같은 action이 출력될 수 있고 특히 diffusion/flow policy는 그럴 일이 수도 없이 많다는 것이다.
이것이 논문이 말하는 문제 제기이다. 어떤 행동이 좋은지를 위해서 다른 $w$를 굳이 다 탐색할 필요 없음에도 표준 actor-critic을 적용하면 $w$를 불필요하게 탐색하는 결과가 일어나기 때문이다.

그래서 논문은 위와 같은 새로운 알고리즘, alias exploitation을 제안한다. 바로 $Q^W$를 따로 만들어 distillation을 적용하는 것이다. 어떤 상태 $s$에서 실제로 환경에서 실행한 행동은 $a$ 하나 뿐이지만 그러한 action을 유도한 $w$는 여러 개 이므로, 서로 구분할 필요도 없이 동일한 가치로 묶어버리면 된다는 것이 이 접근의 핵심이다.
이번에는 Offline RL에서의 문제로 넘어가보자. Online RL은 latent를 직접 뽑아서 실행하고, 그 데이터를 저장하기 때문에 문제가 없다. 반면 Offline RL에서는 action만 알고, 그 action을 선택하기 위한 latent는 모른다는 것이 문제이다.
“오프라인에서도 그냥 actor가 w를 뽑고 critic을 업데이트하면 되지 않나?” 싶지만, 오프라인 RL의 기본 전제는 새 action을 실행할 수 없다는 것이다. 즉, critic이 신뢰할 수 있는 영역은 데이터 분포 주변인데, latent-space에서 마음대로 샘플링하면 결국 “데이터 밖 행동 평가”로 넘어가기 쉽다.
여기서 DSRL-NA는 또 한 번 흥미로운 보수성(conservatism) 포인트를 만들어낸다. latent policy는 자신의 공간에서는 자유롭게 움직일 수 있지만, 그 latent가 생성한 action이 BC policy의 분포에 존재하지 않는다면, 해당 action은 자연스럽게 선택의 대상에서 배제된다. 결과적으로, latent-space에서는 제약 없이 최적화를 수행하면서도, action-space에서는 in-distribution 행동만 평가·선택하는 구조가 형성된다.
Experiments
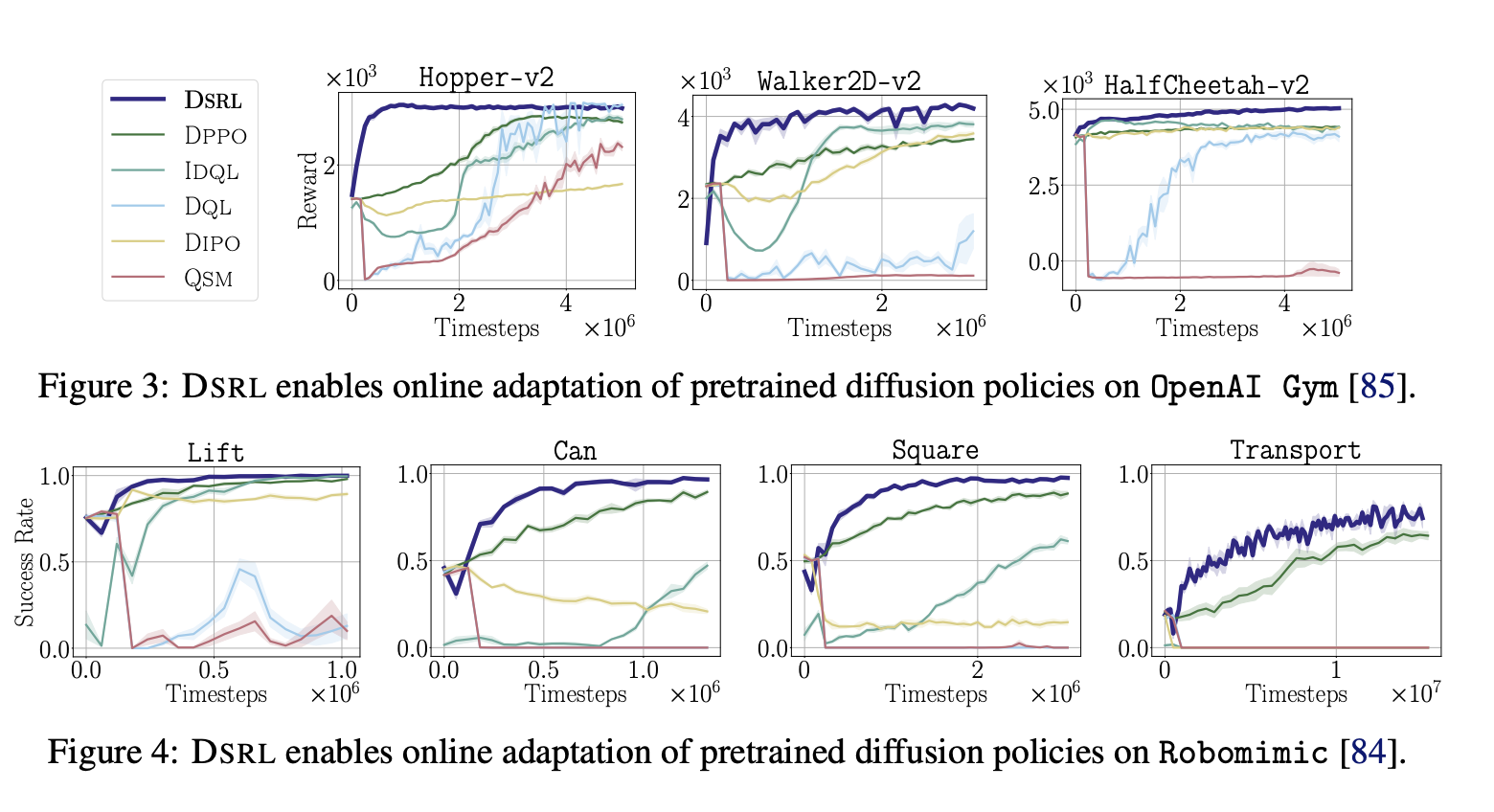
사실 성능이 잘 나오는 것에는 대충 그럴 것 같아서 적당히 그래프만 하나 확인하고 넘어가려고 한다. 아이디어가 확실히 좋았던 것이라...
Conclusion
사실 논문 보면서 느낀 것은 아이디어 정말 좋다! 이고, BPTT의 문제를 어떻게 해결할 것인지에 대한 생각의 지평을 넓혀주는 논문 같다.
사실 단점이라고 볼 수 있는 것은 최적의 성능은 도달하지 못하겠다는 것인데... 오프라인이든 온라인에서든 말이다. 그런데 애초에 논문의 목표가 최적의 정책을 찾는 것이 아니라 안전하게 동작하면서 빠르게 성능을 끌어올리고, 시스템을 망가뜨리지 않는 것이기 때문에 비판으로서도 적절하지 않은 것 같다.
다만 여전히 나는 diffusion/flow 기반 policy를 직접적으로 사용하는 것이 latency에 큰 한계가 있지 않을까 생각해서, 이러한 bottleneck 자체를 해결하는 것이 하나의 과제이고, 따라서 나는 돌고돌아서 one-step policy 자체를 근본적으로 개선하는 것이 좋을 것 같다고는 생각한다.
이만 논문 리뷰는 여기서 마치겠다.