시험공부하기가 너무 싫은 나머지 논문을 읽는(?) 이상한 선택지를 했다. 사실 수능공부할때도 공부는 하기 싫은데 또 양심은 있어야겠고 해서 책만 주구장창 읽었던 적이 있다. 책 많이 읽으면 국어를 잘하게 될 줄 알았는데 그렇지 못해서 갑자기 아쉽다는 생각이 들었다. 일단 논문의 method에 대해서 이야기하기 전에, DPO가 어떻게 혁신이었는지, 그러나 그 DPO의 문제가 무엇이었는지에 대해서 이야기해보도록 하자.
Direct Policy Optimization ++
언어모델의 응답 값에 대한 보상은 사실 언어모델이 생성하는 확률 그 자체, 즉 log-likelihood이었음을 보여준 것이 DPO라고 보면 되겠다. 이러한 보상을 바탕으로 선호되는 응답과 선호되지 않는 응답 사이의 차이를 bradley-terry 모델에 넣어버리면 loss function이 된다. 이를 통해서 모델을 학습하면 alignment가 잘 될 수 있음이 여러 응용들에 의해서 밝혀지면서 LLM의 민주화에 하나의 기여를 한 논문이 되기도 했다.
하지만 DPO에는 명확한 진입 장벽이 존재한다. 이번 포스트에서는 바로 이 '선호/비선호 데이터 쌍(Paired Preference Data)'의 문제점에 대해 이야기해보고자 한다.
앞서 언급했듯, DPO를 적용하려면 반드시 승/패가 나뉜 쌍(Pair) 데이터가 필요하다. 양질의 쌍 데이터가 충분하다면 이상적이겠지만, 현실의 데이터는 그렇지 못한 경우가 주를 이룬다. 설령 쌍 데이터를 확보했다 하더라도 문제인데, 라벨러마다 주관이 다르다 보니 데이터 전반에 걸쳐 일관된(Uniform) 선호 순위를 보장하기가 매우 어렵다.
결과적으로 alignment의 궁극적 목표 중 하나는 '쌍(Pair)'이라는 제약에서 벗어나는 것이다. 비교 데이터가 없더라도, 선호와 비선호 데이터가 독립적으로 존재할 때 학습이 가능한 형태가 되어야 한다는 것이 결론이다.
사실 이 문제를 DeepseekMath 논문에서 보여주는 GRPO에서 해결하는 모습을 보여준다. RLVR 기반으로, 같은 인풋에 대한 여러 응답의 reward의 평균을 baseline으로 잡아 critic처럼 사용하기 때문에, 각 응답에 대한 advantage로 policy gradient에 가중하게 되어 선호/비선호 응답 쌍과 baseline critic 모델의 제약에서 벗어난다.
그러나 여전히 응답에 대한 보상을 명확하게 줄 수 없는 상황이 있기 때문에 RLHF라는 것이 탄생한 만큼, RLVR을 적용하기 어려운 상황에서는 GRPO의 방법을 적용하기에는 다소 무리가 있다. 애초에 GRPO는 on policy 기반이기 때문에 비교에 있어서 공정하지 않기도 하고 ㅎㅎ. 아무튼 이렇게 선호/비선호 이진 분류에 대한 데이터만 있는 경우에, 별도의 critic 없이, pairwise 비교 필요 없이 alignment를 달성하는 방법론이 KTO인 것이다.
Kahneman-Tversky Optimization
우선 어떠한 inductive bias가 있는지 확인해보자. DPO/PPO는 pair 데이터에 대한 선호의 순서가 있다는 inductive bias를 두기 때문에 두 응답의 보상을 bradley-terry에 태운다. KTO는 Prospect Theory(전망 이론), 인간의 의사결정은 절대적인 효용보다는 기준점(Reference point) 대비 이득과 손실에 따라 비대칭적으로 결정된다"는 가정을 둔다.

같은 절대적 값 대비 그것이 이득일 때보다 손실일 때 더 민감하게 받아들이며, 절대적 값이 커질수록 그에 대한 반응은 둔감해진다는 이론이다. 우선 reward에 대한 형태는 DPO와 똑같이 log-likelihood이다.
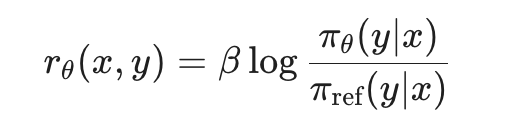
이렇게 만들어진 reward function에 다음과 같은 formulation을 적용한다:

함수 $v$는 Prospect theory에 기반한 0보다 클 때 concave, 0보다 작을 때 convex한 함수이다. $z_0:=E_Q$는 일단 베이스라인이라고 생각하자. Loss function은 다음과 같다:
- Good(+): 내 보상($r$)이 기준($z_0$)보다 커야 값이 커짐.
- Bad(-): 내 보상($r$)이 기준($z_0$)보다 작아야 값이 커짐. (순서 반전)
Case 1: 바람직한 데이터 ($y \in \text{Desirable}$)
Case 2: 바람직하지 않은 데이터 ($y \in \text{Undesirable}$)
보상에 대한 그래디언트는 다음과 같다:
결과적으로
선호되는 데이터라면 양수고, 선호되지 않는 데이터면 음수 방향이었기 때문에 모델이 선호되는 데이터로 정렬되기 위해 학습됨을 알 수 있다. 아직 빠진 내용이 baseline에 관한 것인데, 논문에서는 KL divergence로 한다고 하는데... 사실 그럴 필요 없이 그냥 로그 우도의 평균으로 하면 된다.
중요한 내용들을 다 봤으니, 실제로 이 방법이 유리한지 확인해보자:
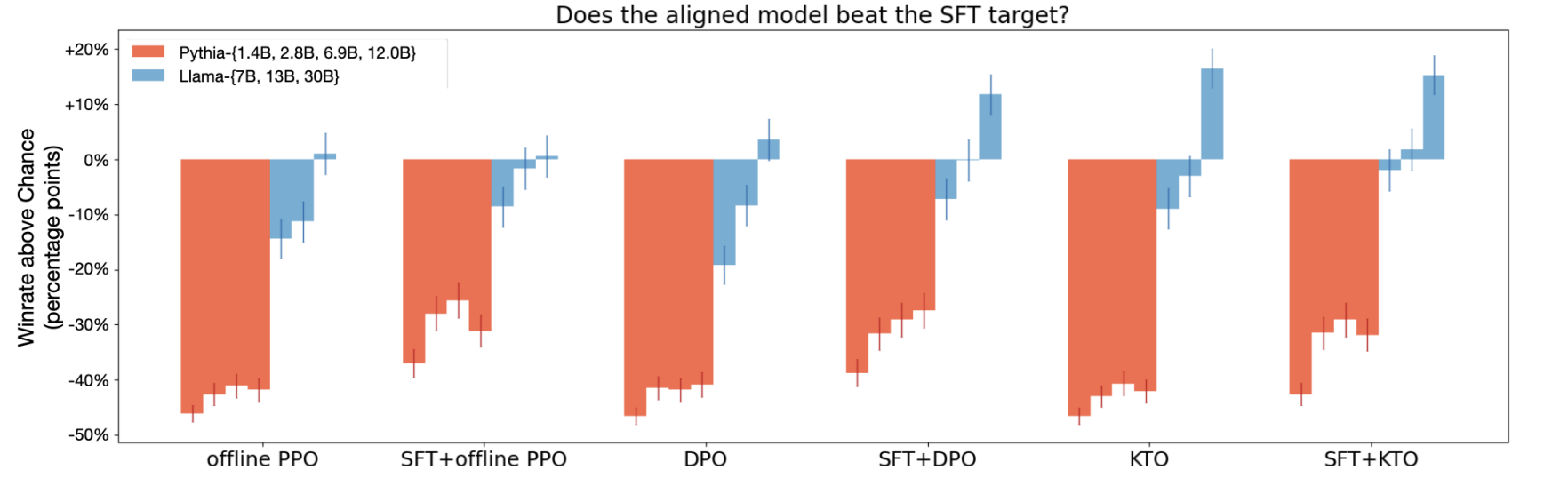
낮은 모델에 대해서 alignment 적용하면 모델이 망가진다는 것은 이미 다 아는 사실이지만... Llama 30B만 확인해보자. DPO를 능가하는 것을 확인할 수 있다. 사실 DPO만 이긴다를 저격하고 나온 논문같다는 느낌!!

Pair 데이터가 불균형한 경우 KTO가 더 좋은 선택지가 됨을 서술하는데, 이에 관한 실험도 존재한다:
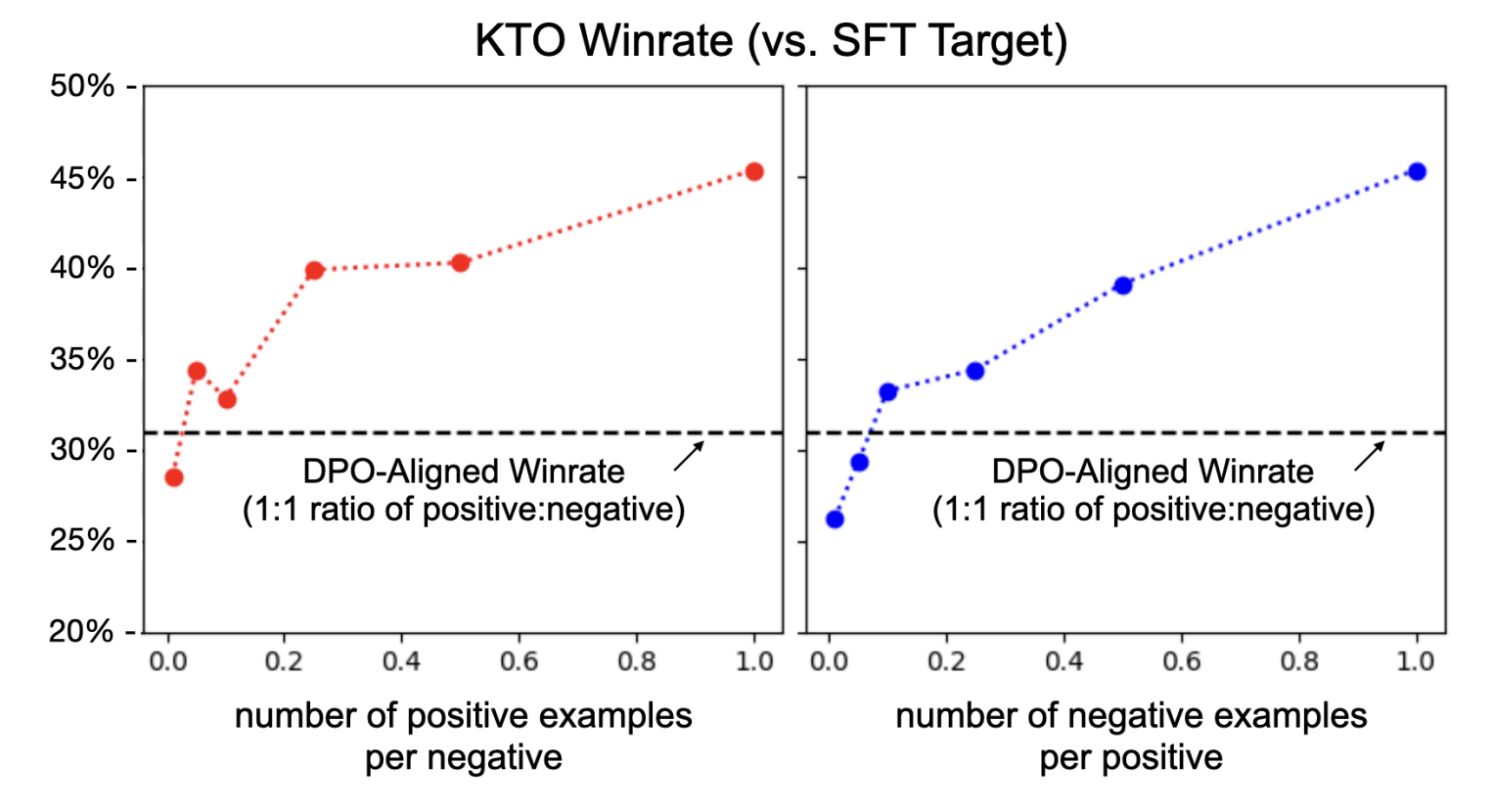
데이터가 균형에 있는 경우 DPO가 더 좋지만, 그렇지 않은 경우 KTO가 더 유리함을 확인할 수 있다. 이만 마치도록 하겠다...
'논문 리뷰 > NLP' 카테고리의 다른 글
| Large Language Diffusion Models 논문 리뷰 (0) | 2026.01.25 |
|---|---|
| Qwen2.5-Math 논문 리뷰 (3) | 2026.01.21 |
| Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning 논문 리뷰 (0) | 2025.10.09 |
| EVOLUTION STRATEGIES AT SCALE: LLM FINETUNING BEYOND REINFORCEMENT LEARNING 논문 리뷰 (0) | 2025.10.07 |
| GTE 논문 리뷰 (1) | 2025.08.28 |