Large Language Diffusion Models
이 논문은 기존의 자기회귀(autoregressive, AR) 언어모델과 전혀 다른 생성 관점을 제안한다. LLaDA는 토큰을 왼쪽에서 오른쪽으로 하나씩 생성하는 대신, 마스킹된 토큰을 복원하는 확산(diffusion) 방식으로 텍스트를 생성한다.
AR 언어모델이 고질적으로 가지는 문제점에 대해서 이야기해보도록 하자. Autoregressive라는 것에 그 문제를 바로 알 수 있다. 순차적인 토큰 생성은 그 성격 때문에 높은 latency를 초래하며, 오류가 누적될 수 밖에 없는 구조로 long sequence에 대해서 scalable하지 않다. 우선 아키텍처를 다루면서 이러한 근본적인 문제 자체를 LLaDA에서 어떻게 해결하는지 보고, 실제로 해결한 것인지 또는 다른 문제점은 없는지, 혹은 해결한 것이 그렇게 유의미한 것인지 탐구해보자.
Method
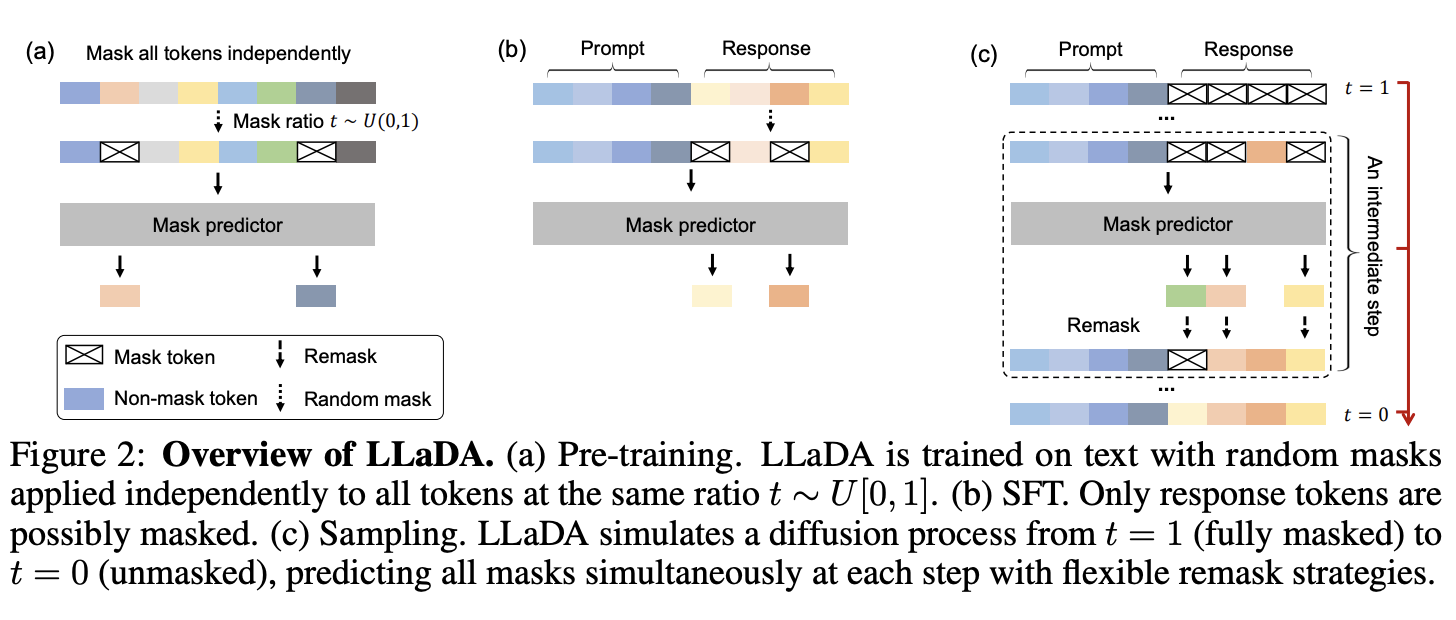
훈련 단계에서는 매우 단순하다. 완전한 문장에서 랜덤한 비율로 토큰을 마스킹하고, 마스킹된 토큰 전체를 한 번에 복원하도록 학습한다. 이 과정은 항상 단일 스텝(single-step denoising)이며, 단계적으로 복원하는 구조는 전혀 없다. 중요한 점은 마스킹 비율이 고정된 BERT와 달리, 0부터 1까지 모든 마스킹 비율을 학습한다는 것이다. 이로 인해 모델은 거의 모든 토큰이 가려진 극단적인 상태도 경험하게 된다.
Pretrain과 SFT 모두 같은 방식으로 훈련되며, 유일하게 다른 점은 SFT에서는 초기 instruction prompt가 들어간다는 점이다.

Loss function은 다음과 같이 구성된다. 마스킹된 토큰에 대한 Negative log likelihood를 최대화하는 방식으로 일어난다. $1/t$가 반영된 것에 대해서 생각해보자. $t$ 자체가 변동되는데, 이는 학습마다 마스킹된 비율이 달라지는 것을 의미하는 것을 알 것이다. 직관적으로, 만약 10 단어 중에서 한 개의 단어만 마스킹하고 복원하는 경우, 이에 대해서 틀리는 경우 그 패널티를 더 많이 주어야 한다. 반면 10 단어 중에서 9개의 단어를 마스킹한 경우, 틀리더라도 그 패널티가 크지 않아진다. 따라서 모델이 안정적으로 학습하면서 점진적으로 더 많은 마스킹에 대해서 잘 복원할 가능성이 높아질 것이다.
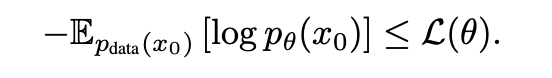
Loss function은 실제 데이터에 대한 KL divergence의 upper bound를 형성한다. Bound니까 tightness가 중요하기는 한데, 일반적으로 batch size가 큰 경우 이에 대한 문제점이 크게 부각되지 않으니 신경을 막 쓸 것은 없다고 본다.
흥미로운 부분은 추론(inference) 이다. 추론 시에는 완전히 마스킹된 상태에서 시작해, 한 번에 전부 생성하지 않고 여러 스텝에 걸쳐 일부 토큰만 확정하고 나머지는 다시 수정하는 방식을 사용한다. Diffiusion의 기본적인 원리와 같이, 한 번 생성된 토큰이라고 해서 그 다음 스텝에서 확정된 채로 존재하는 것이 아니다. Reverse process가 forward process와 정합적이려면 한 번 생성된 토큰도 다시 masking될 수도 있다.
이때 확신이 낮은 토큰을 다시 마스킹하는 low-confidence remasking 전략을 사용한다. 불확실한 결정은 뒤로 미루고 문맥이 충분히 형성된 뒤에 해결한다. 즉, “처음부터 정답을 맞히는 모델”이 아니라 “대충 맞춘 뒤 점점 고쳐가는 모델”이다. 이 점이 autoregressive 모델과는 다르게 강점을 지니는 지점이다.
또한 논문에서는 foward처럼 생성하는 법, 그리고 완전히 랜덤으로 생성하는 법 등을 실험에서 보여주는데, 우리가 Diffusion자체에서 생각하는 것과 마찬가지로 랜덤 생성이 더 효과적임을 보여준다.
Experiments
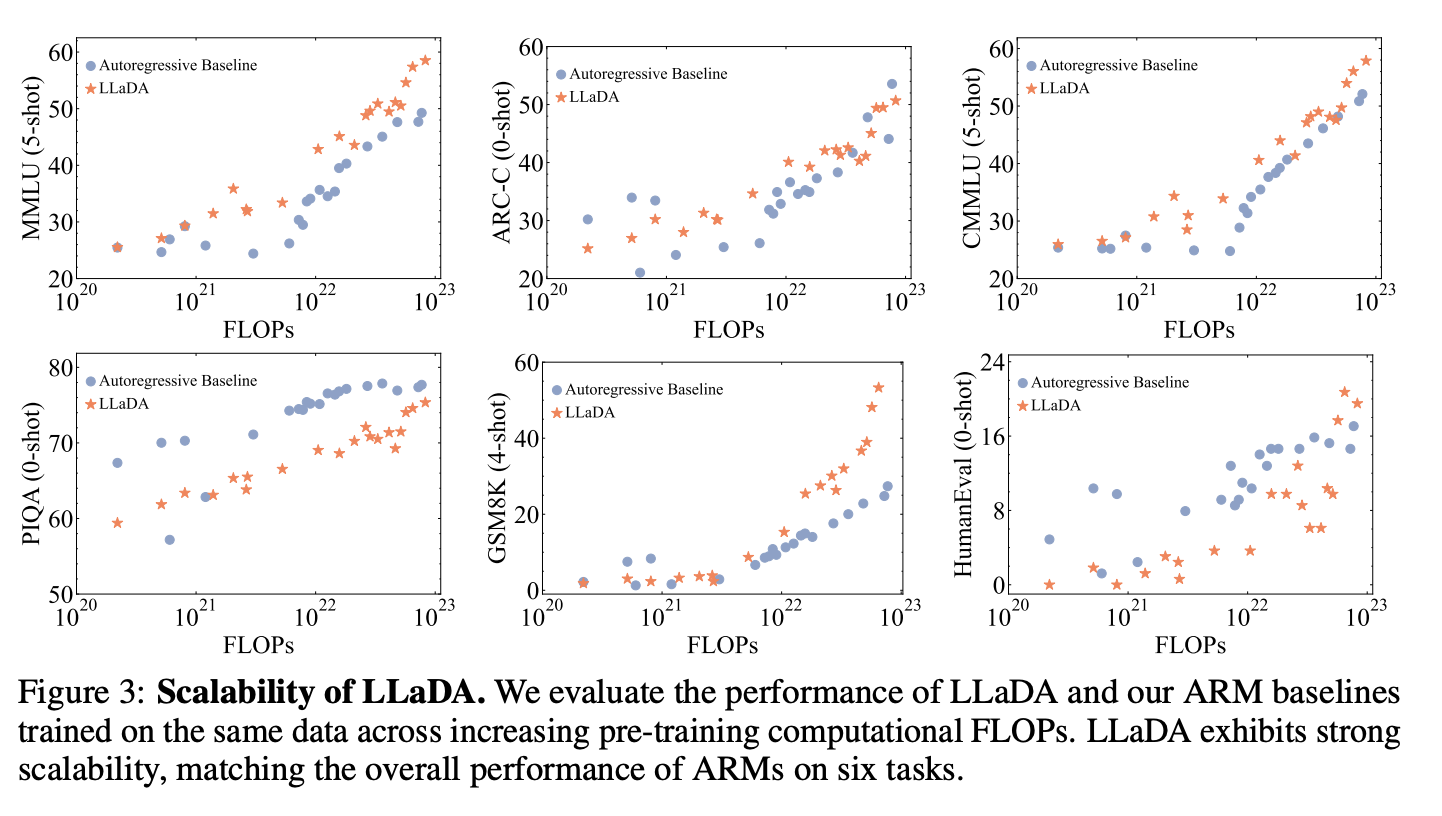
사전학습 때 쓴 computation cost(FLOPs) 대비 성능 차이에 대한 그래프다. 이 실험 결과로 diffusion 언어 모델도 Scalable한 것을 확인할 수 있다.
성능 비교를 확인해보자.
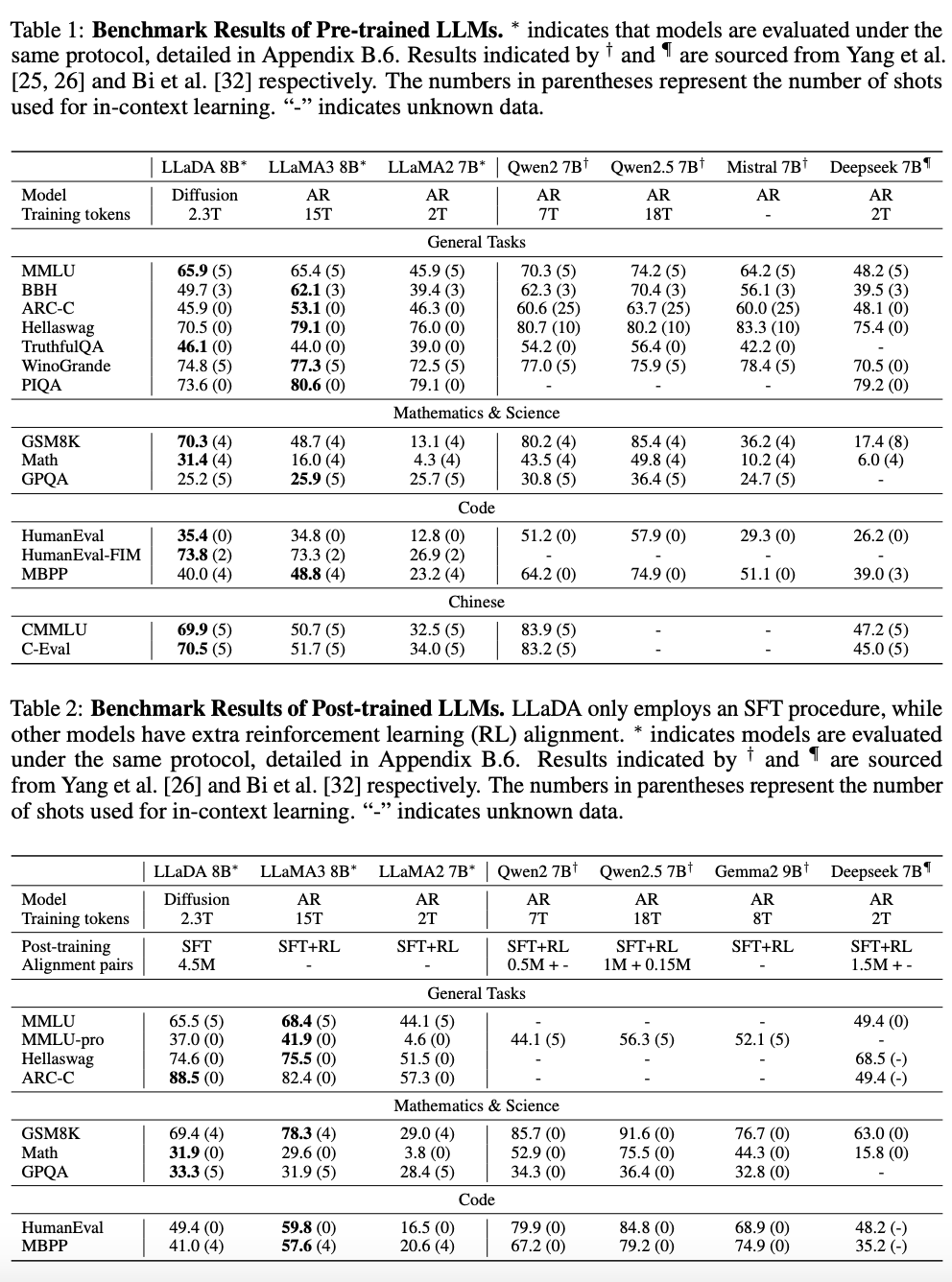
견줄 만한 성능이다. AR보다 특히 더 잘하는 구간은 reverse generation이다.(사실 당연한거 ㅋㅋ)
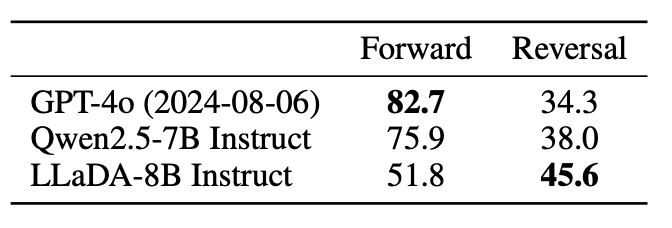
아... 근데 당연한 것에 비해서 그렇게 잘하는 것이 맞나 싶기도 하고... 그리고 GPT는 영어가 메인이고, LLaDA는 중국어 많이 섞어서 했는데 과연 공정한 비교인가 싶기는 하다. 무엇보다 reverse generation을 할만한 일이 그렇게까지 많나? 하면 난 아닌 것 같다. 다만 LLaDA만 할 수 있는 특별한 장점은, instruction을 앞에서 넣는 것이 아니라 중간에, 혹은 뒤에 넣어도 된다는 것이다!

Table 9를 보면, 사실 diffusion 자체가 마법은 아님을 알 수 있다. Low-confidence masking을 바탕으로 재생성을 하여 추론 성능을 끌어올릴 수 있다는 것이 핵심이다. 즉 autoregressive model은 모델의 self-correction 없이는 그 오차가 누적되는 것에 반해, LLaDA는 근본적으로 모델이 저신뢰도 수정이라는 아이디어를 가지고 있는 것이다.
생각하다보면 또다른 문제가 생길 것 같다. AR모델은 원하는 대로 생성하다가 여기서 멈춰야 하겠다 판단이 들면 멈추면 된다. 그러나 Diffusion 방식은 근본적으로 Length 자체가 하이퍼패러미터다. 이러한 문제에 대해서 논문에서는 length hyperparameter에 대해서 성능 gap이 별로 달라지지 않는다를 보여주기는 한다.

그러나 어디까지나 일부 benchmark task에 대해서만 해당되는 것이기 때문에, 이 결과에 대해서 100프로 신뢰해서는 안 된다. 다만 이것을 "해결 가능한 문제"로 연구의 과제로 삼는 것은 좋은 자세일 것 같다.
마지막 잘 안알려져있는 한계에 대해서 이야기해보고자 한다.
보통 diffusion 기반 언어 모델이 생성에 빠르다고 한다. 빠른 것은 맞는데, 과연 무엇 때문에 빠른 것일까? 병렬 생성이 가능해서 빠른 것이다. Autoregressive model은 순차 생성을 해야하니, 애초에 병렬을 하기가 불가능하기 때문에 빠르지 않다.
그러면 1회 토큰 생성에서 연산량은? AR이 압도적으로 유리하다. 즉 까놓고 보면 GPU idle 자체를 막기 때문에 유리한 것이지, 그것이 특별히 계산에서 유리해서 그런 것이 아닌 것이다.
마지막으로 KV cache를 사용하지 못하는 것이 큰 단점인데, 아마 이 논문이 NeurIPS 2025 accepted이니... 이미 멋진 석학들께서 해결하지 않았을까 싶기도 하다 ㅋㅋ
분야가 그래도 정말 재밌는 것 같아서 열심히 파봐야겠다~~
'논문 리뷰 > NLP' 카테고리의 다른 글
| Why DPO is a Misspecified Estimator and How to Fix It 논문 리뷰 (0) | 2026.02.22 |
|---|---|
| Soft Adaptive Policy Optimization 논문 리뷰 (0) | 2026.01.29 |
| Qwen2.5-Math 논문 리뷰 (3) | 2026.01.21 |
| KTO 논문 리뷰 (0) | 2025.12.06 |
| Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning 논문 리뷰 (0) | 2025.10.09 |