Summary
본 논문은 언어모델의 Chain-of-Thought(CoT) 생성 과정에서 고(高)엔트로피 소수 토큰이 모델의 추론 능력에 핵심적인 역할을 함을 규명한다. 저자들은 이러한 토큰이 추론 경로의 분기점(fork)으로 작동함을 실증하고, 이들 토큰에 한정하여 정책 그래디언트를 적용하는 선택적 RLVR 학습 전략을 제안한다.
실험 결과, 전체 토큰의 약 20%에 해당하는 고엔트로피 토큰만으로도 동등하거나 더 높은 추론 성능을 달성하였으며, 학습 후에도 기존 모델의 엔트로피 패턴이 대부분 유지됨을 확인하였다. 이는 제안된 방법이 추론 능력을 강화하면서도 모델의 일반화 구조를 보존함을 시사한다.
Preliminary
DAPO

DAPO는 PPO의 clipping 전략을 기반으로 정책 업데이트의 안정성을 확보하면서, GRPO에서 도입된 다중 응답 보상 정규화 방식을 이용해 advantage를 계산한다. 이때 별도의 value 네트워크를 사용하지 않아 학습 효율을 높이며, KL divergence 제약은 명시적으로 사용하지 않고, 대신 비대칭적 $\epsilon$-clipping을 적용하여 정책 간 거리 제어를 완화한다.
Token Entropy

엔트로피는 확률분포에 대한 불확실성의 정도를 나타내는 지표 중 하나이다. 엔트로피가 최대가 되는 경우는 확률분포가 discrete uniform일 때, 최소가 되는 경우는 degenerate distribution일 때이다. 즉 uniform인 경우,
$$ H=\sum_{i=1}^{n}\frac{1}{N}\log{N} = \log{N} $$
이며, degenerate인 경우
$$ H=-\sum_{i=1}^{n}p_i\times\log{p_i} = -\log{1}=0 $$
이 되는 것을 확인할 수 있다.
같은 토큰으로 아웃풋으로 냈다고 하여 $\frac{z_t}{T}$가 같은 것은 아니기 때문에, 같은 토큰이더라도 이전의 문맥에 따라 엔트로피는 달라질 수 있다.
Experiments & Method
Introduction에 나온 내용을 보자.

이에 대한 번역이다:
- CoT(Chain-of-Thought)에서 대부분의 토큰은 낮은 엔트로피로 생성되며, 그중 일부의 토큰만이 높은 엔트로피를 가진다. 이러한 고(高)엔트로피 소수 토큰은 추론 과정에서 “분기점(fork)” 역할을 하여 모델이 다양한 추론 경로로 나아가도록 이끈다. 이러한 중요한 분기 토큰에서 높은 엔트로피를 유지하는 것은 추론 성능 향상에 도움이 된다.
- RLVR 학습 과정에서, 추론 모델은 기본(base) 모델의 엔트로피 패턴을 대부분 유지하며, 변화는 점진적이고 미세하다. RLVR은 주로 고엔트로피 토큰의 엔트로피를 조정하며, 저엔트로피 토큰의 엔트로피는 좁은 범위 내에서만 변동한다.
우선 첫 번째 항목에 대한 논문의 실험 결과와 두 번째 항목에서 본 논문이 어떤 방법을 적용했으며, 이것이 실제로 어떻게 효과적인지 알아보자.
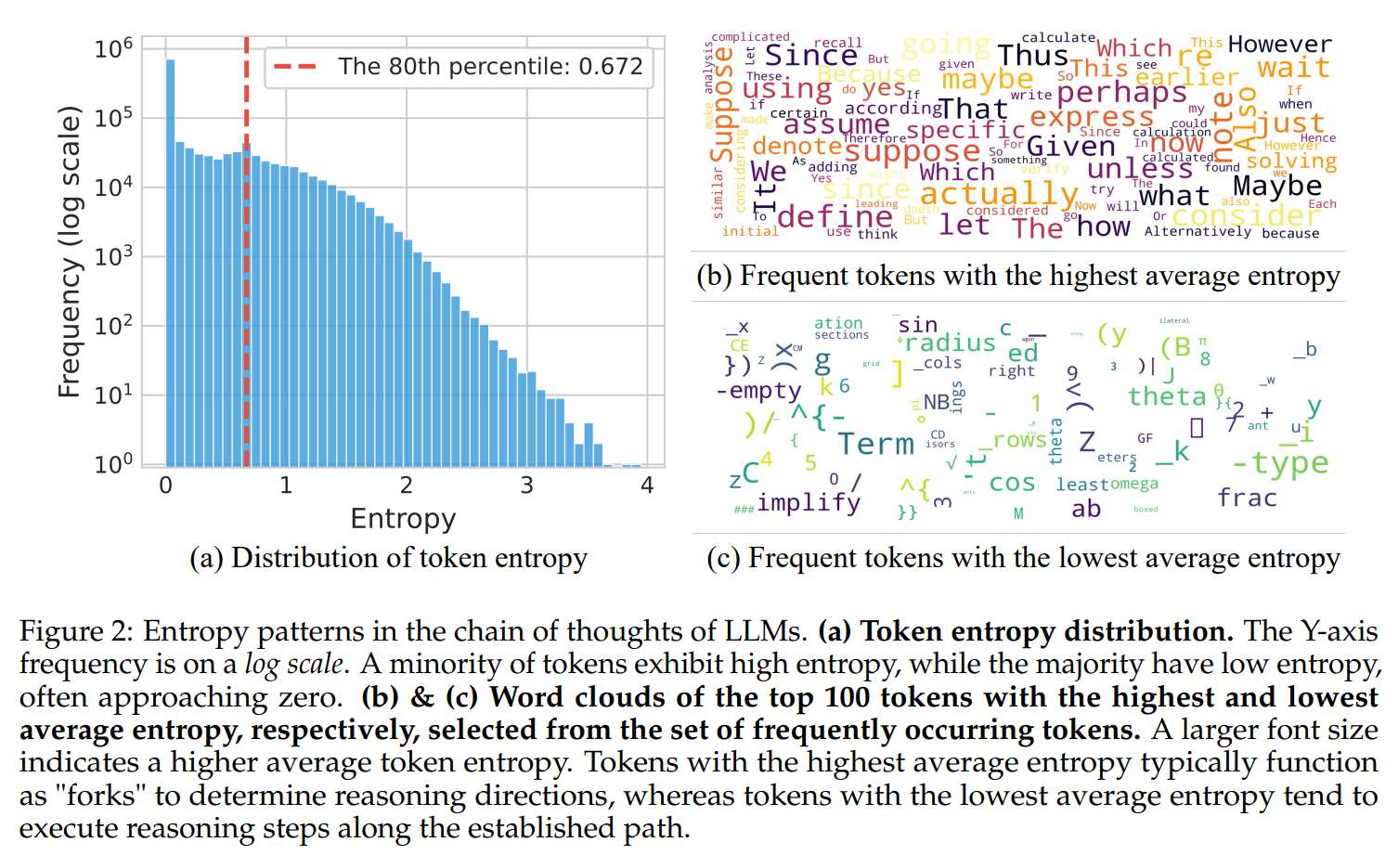
(a)에서 대부분의 토큰이 낮은 엔트로피를 가지고 있음을 확인할 수 있으며, (b)에서 높은 엔트로피를 가진 토큰들은 의미상 문맥 흐름에 대한 분기점을 가지고 있음을 알 수 있다. 반면 엔트로피가 낮은 토큰들의 경우 흔히 사용되는 수학적 기호 또는 문맥의 형식적 짜임새에 기여하는 경우가 대부분임을 알 수 있다.

우선 붉은 색 그래프에 집중해보자. 엔트로피가 낮은 토큰의 temperature을 1으로 두었을 때 엔트로피가 높은 토큰의 temperature을 높여주는 경우 일정한 구간 안에서 AIME score가 향상되는 것을 볼 수 있다. 즉 엔트로피가 낮은 토큰의 엔트로피를 적당한 정도로 향상시키는 것은 추론 성능 향상에 기여한다고 결론낼 수 있는 것이다.
한편 푸른 색 그래프를 보면, 엔트로피가 낮은 토큰의 엔트로피를 높여주는 경우 일정한 범위 이후 성능이 급격하게 낮아지는 것을 확인할 수 있다. 여기서 가능한 추론은, 엔트로피가 높은 토큰의 엔트로피를 일정한 정도로 늘려주면서 동시에 엔트로피가 낮은 토큰은 크게 변하지 않도록 제어하는 경우 추론 성능을 향상시킬 수 있음을 의미한다.
따라서 본 논문은 다음과 같은 Objective로 RLVR을 적용하고자 한다:
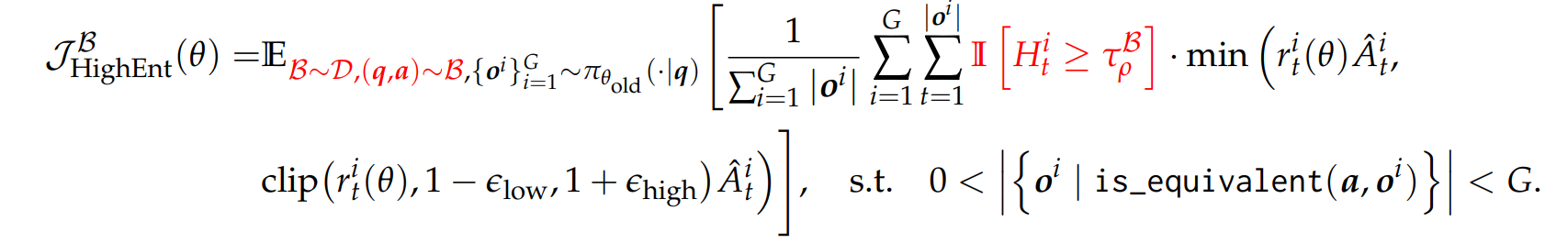
DAPO에서 indicator function이 추가된 것에 주목하자. 이전에 DAPO 방식은 모든 토큰 응답에 대하여 패러미터 업데이트를 적용하는 반면, 본 논문은 높은 엔트로피를 가지는 구간에 대해서만 패러미터 업데이트를 진행하는 것을 확인할 수 있다. 즉 언어모델 추론의 분기점에 해당하는 위치를 중점적으로 학습시킴으로써 언어모델의 추론 능력을 높이는 것이다.

이 방법이 실제로 유의미한 성능 향상을 가져오는 것을 확인할 수 있다. 추가적으로 확인해야 하는 것은, 본 논문이 제시한 방법이 실제로 기존 base 모델의 토큰 엔트로피에서 크게 벗어나지 않는지이다.

기존 모델의 토큰 엔트로피와 86% 이상 겹치는 것을 확인할 수 있으며, 이는 곧 본 논문의 방법론이 모델을 크게 바꾸지 않는다는 것을 확인할 수 있다. 구제척인 수치로 성능 향상을 더욱 자세히 확인해보자.

Introduction에는 다음과 같은 내용이 추가적으로 담겨져 있다.

엔트로피가 낮은, 즉 엔트로피 상위 20%~80%의 토큰에 대해서 훈련한 결과 기존 방법론에 비해서 성능을 크게 떨어뜨리는 것을 또한 확인할 수 있다. 나머지 실험 결과는 논문을 참조해주면 좋겠다.
Discussions
Introduction에 나온 insight의 마지막 부분을 확인해보자:

본 논문에서 SFT가 왜 단순히 암기(memorize)에 그치는지에 대한 이유를 설명하는데, 그것은 단순히 따라읽기에 그친다. 즉 정답 label은 one-hot distribution을 따르며, 언어모델은 그 방향대로 학습하여 엔트로피가 전체적으로 낮은 상태가 되기 때문이라고 말한다. 반면 RL은 보상이라는 다소 추상적인 개념을 통해서 언어모델이 다양한 응답을 낼 수 있도록 유도되기 때문에 엔트로피를 높이는 방향으로 학습된다고 말한다.
또한 LLM의 CoT에서 나타나는 비균질적인 엔트로피 패턴은, 대규모 사전학습으로 인해 사전 지식을 이미 방대하게 내재하고 있으며, 언어의 유창성을 유지해야 하는 특성으로 인해 대부분의 토큰은 낮은 엔트로피를 보이지만 본질적으로 불확실성 자체가 높은 일부 토큰들이 탐색을 허용하여, 결과적으로 높은 엔트로피를 보인다고 말한다.
Clip-higher 방식은 기존의 방식에 비해서 우수함도 확인할 수 있다. RLVR에서의 엔트로피 보너스는 낮은 엔트로피를 가진 토큰들마저도 엔트로피를 증가시켜 앞서 언급한 CoT에서의 중요한 토큰과 중요하지 않은 토큰 간의 신호를 교란시킬 수 있음을 논문에서는 언급하며, clip-higher 방식이 고엔트로피 토큰을 중점적으로 탐색할 수 있도록 유도한다고 설명한다.
배가 고파서 여기까지... 정말 좋은 논문이다!
'논문 리뷰 > NLP' 카테고리의 다른 글
| Qwen2.5-Math 논문 리뷰 (3) | 2026.01.21 |
|---|---|
| KTO 논문 리뷰 (0) | 2025.12.06 |
| EVOLUTION STRATEGIES AT SCALE: LLM FINETUNING BEYOND REINFORCEMENT LEARNING 논문 리뷰 (0) | 2025.10.07 |
| GTE 논문 리뷰 (1) | 2025.08.28 |
| Self-Rewarding Language Models 논문 리뷰 (0) | 2025.08.19 |