Self-Rewarding Language Models
본 논문은 깊은 이론적 인사이트를 제공하기보다는, 간단하면서도 낮은 비용으로 높은 alignment 성능을 달성할 수 있는 참신한 방법론으로 이해하는 것이 적절하다고 판단한다. 따라서 필자는 본 리뷰에서는 세부적인 심층 분석은 생략하고, 방법론과 결과 해석 중심으로 간략히 다루고자 한다.
(무엇보다 오늘의 논문 리뷰를 시작하기에 가장 마음이 편하다)
Summary
본 논문은 RLHF/DPO에서 인간의 선호에 의한 데이터 생성이 주요 병목 원인임을 지적하며, 인간이 생성하는 것 없이 언어모델 스스로 데이터를 만들고 평가, 업데이트하면서도 충분히 좋은 성능을 낼 수 있다는 아이디어를 제시한다.
Method

방법은 간단하다.
- 현재 모델 $M_t$가 instruction을 생성하고, 생성된 instruction에 대해서 $N$개의 응답을 생성한다.
- $N$개의 응답에 대해서 모델이 스스로 응답에 대해 평가(LLM-as-a-Judge)한다.
- $N$개의 응답에 대해서 각각의 평가 점수를 바탕으로 선호/비선호 pair set을 만든 후 이를 바탕으로 DPO training을 진행한다.
- DPO training을 진행한 모델 $M_{t+1}$은 1번으로 돌아가서 그 절차를 반복한다.
여기서 들 수 있는 의문은, 과연 모델이 적절한 평가를 할 수 있는가이다. EFT(Evaluation Fine-Tuning)가 그 핵심을 담당한다.

LLM에게 instruction과 평가 대상인 reponse를 input으로 제공하고, chain-of-thought로 만들어진 해당 응답에 대한 평가 데이터를 SFT로 학습하는 구조이다.
Experiments
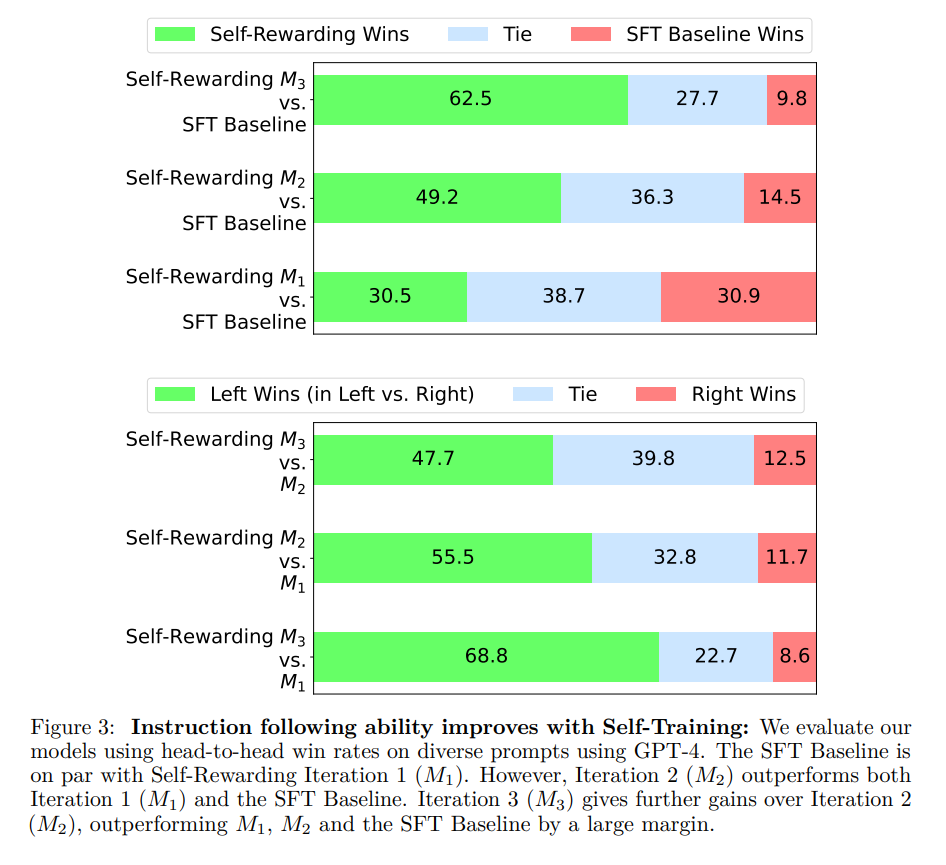
Self-Improvement 로직만으로도 지시를 따르는 빈도가 높아짐을 확인할 수 있다. 단순히 SFT 베이스라인 모델이나 과거의 자신과 비교하는 것이 아니라 기존의 우수한 모델에 대해서도 비교한 결과가 매우 인상적이다.
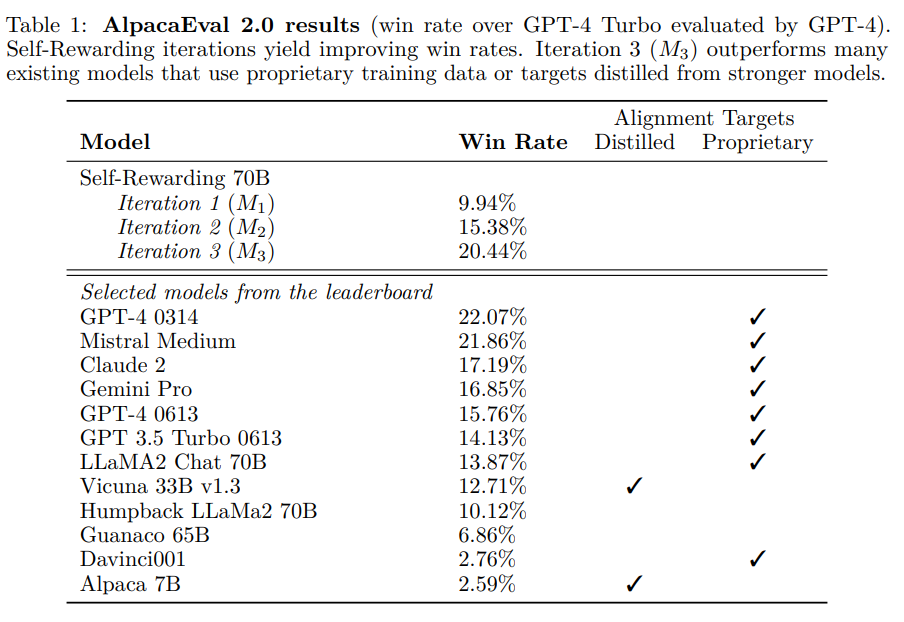
단순히 3번의 반복만 했을 뿐인데도 나와있는 우수한 모델들을 대부분 이겼으며, GPT-4와 비교하더라도 큰 차이가 없는 것이 핵심이다. 다만 이제 AlpacaEval의 각 항목에 대한 iteration별 평가가 조금 이상하기는 하다.
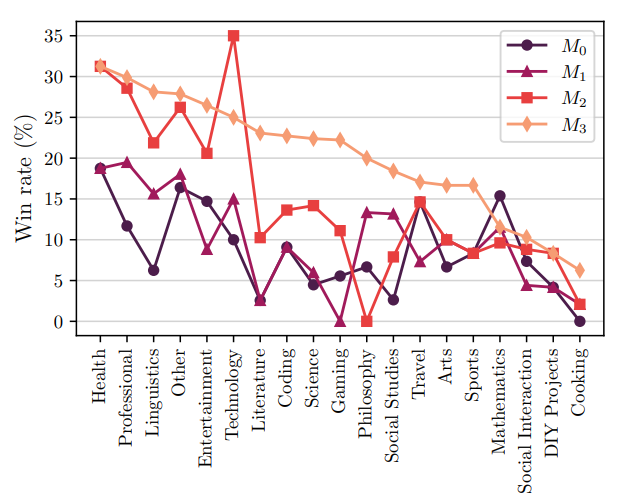
성능이 전체적으로 증가하는 것으로 보이기는 하는데, 막 일관적인 성능 향상이라기에는 조금 모호한 감이 있다. 여기서 개인적인 추측이 들어가면... 왜 모델 iteration을 3번까지밖에 하지 않았을까... 아마 그 이후에 대해서는 유의미한 성능 향상이 존재하지 않거나 오히려 논문의 설명력을 저해하는 결과가 나왔기 때문이지 않을까 싶다. 분명 iteration을 늘리고서 GPT-4를 이겼다고 한다면 이 논문이 매우 우수함을 광고할 수 있을 것 같기도 하고.
그 이유에 대해서는 모델 자체의 capa 한계 때문이지 않을까 추측하고 있다. 자기 자신으로도 비약적인 발전을 이룰 수 있는 것은 충분히 맞지만, 그 이후에 대해서는 self-improving이 자기 자신의 한계에 막히는 것 같다.
Conclusion
본 논문은 RLHF/DPO의 근본적 병목 요소인 인간의 피드백이 중간에 들어간다는 것을, 다른 모델을 두지 않고 자기 자신만 사용하여 self-improving 방법을 사용하여 alignment 성능을 늘리는 것을 보여주었다.
비용적 측면에서 비교가 되지 않을 정도로 우수하지만, 마냥 이 방법만을 사용하는 것은 그 자체의 한계에 갇힌다는 문제점이 존재한다. 다만 alignment 성능 증가를 달성하기 위해서 self-improving 방법을 초기에 적용하고, 잘 초기화된 지점에서 추가적인 task를 하는 것이 좋아보인다!
'논문 리뷰 > NLP' 카테고리의 다른 글
| EVOLUTION STRATEGIES AT SCALE: LLM FINETUNING BEYOND REINFORCEMENT LEARNING 논문 리뷰 (0) | 2025.10.07 |
|---|---|
| GTE 논문 리뷰 (1) | 2025.08.28 |
| APL 논문 리뷰 (1) | 2025.08.18 |
| Safety Alignment Should Be Made More Than Just a Few Tokens Deep 논문 리뷰 (0) | 2025.08.18 |
| Data Shapley in One Training Run 논문 리뷰 (3) | 2025.08.17 |