Summary
Transformer 기반 모델에서 위치 정보(position encoding)는 필수적이지만, 기존 방법들은 중요한 한계를 가진다. Absolute position embedding은 단순히 위치 벡터를 더하는 방식으로, 토큰 간 상대적 관계(relative position)를 충분히 반영하지 못한다. 반면, 기존 relative position 방법들은 attention 구조를 수정하거나 여러 항을 추가해야 하므로 구조가 복잡해지고 일반성이 떨어지는 문제가 있다.
본 논문은 이러한 한계를 해결하기 위해 Rotary Position Embedding (RoPE)을 제안한다. RoPE는 위치 정보를 벡터에 더하는 대신, 위치에 따라 embedding을 회전시키는 방식을 사용한다. 이를 통해 self-attention 계산에서 두 토큰의 상호작용이 자연스럽게 상대 위치 (n−m)에 의존하도록 만든다.
이 접근은 별도의 복잡한 설계 없이도 다음과 같은 장점을 제공한다:
- 상대 위치 정보를 구조적으로 반영
- 시퀀스 길이에 대한 일반화 가능성
- 토큰 간 거리가 멀어질수록 attention이 감소하는 특성
- linear attention과의 호환성
결과적으로 RoPE는 Transformer의 위치 인코딩을 additive 방식에서 multiplicative 변환으로 재해석하며, 더 단순하면서도 효과적인 대안을 제시한다.
Preliminaries
Positional Encoding에 대해 살펴보자. Transformer에서 Self-attention은 기본적으로 입력 토큰들의 순서를 고려하지 않기 때문에, 위치 정보를 별도로 주입해야 한다. 이를 위해 기존 접근 방식은 additive 방식의 positional encoding이다.

위와 같은 방식은 이렇게 만들어진 positional encoding을 바탕으로 각 토큰 embedding에 위치 정보를 더해준다. 아래 attention is all you need 논문의 figure을 참고하자:

그러나 이러한 additive 방식은 위치 정보가 단순히 추가되는 것에 그치지 않고, self-attention 과정에서 content 정보와 강하게 결합되어 버린다는 한계를 가진다. 구체적으로, attention score는 query, key가 positional encoding에 반영된 내적의 형태로 정의된다:

우선 여기서 첫 번째 항은 $x_m$과 $x_n$ 순수한 content 간의 상호작용이며, $p_m$과 $p_n$의 위치 간 상호작용이 존재해 경우에 따라 상대 위치 정보를 일부 반영할 수 있다. 그러나 문제는 다음 두 항이다:
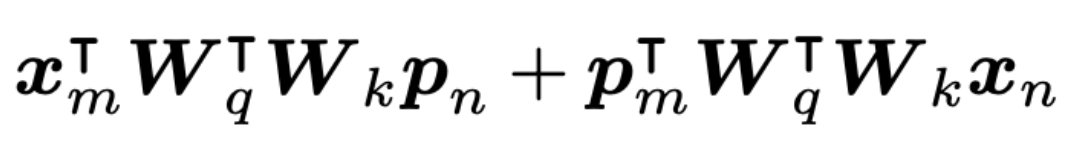
이 항들은 토큰의 내용과 위치가 서로 결합된 형태로 나타나며, attention score가 더이상 단순 상대 위치에만 의존하지 않게 된다. 즉, additive 방식에서는 위치 정보가 독립적인 구조로 반영되지 않고 content와 혼합된 형태로 attention에 영향을 미치게 된다.
이로 인해 다음과 같은 문제가 발생한다:
- 상대 위치 정보를 명확하게 해석하기 어려움
- 위치와 내용이 분리되지 않아 학습이 비효율적일 수 있음
- attention이 구조적으로 relative position을 따르지 않음
결과적으로, 모델은 상대 위치를 직접적으로 활용하는 것이 아니라 여러 혼합된 항들을 통해 이를 간접적으로 학습해야 하기 때문에 혼란이 발생하게 된다. 위치 정보를 학습하는 BERT의 방법도 존재는 하지만, 이는 context length 밖의 context에 대해서는 extrapolation error가 일어난다는 취약점이 존재한다. 이러한 한계를 극복하기 위해, 이후 연구들은 relative position encoding을 도입하여 attention이 직접적으로 m - n에 의존하도록 만들고자 하였다. 그러나 이러한 방법들 역시 attention 구조를 수정하거나 추가적인 항을 도입해야 하므로, 구조적인 복잡성이 증가하는 문제가 존재한다.
이러한 맥락에서, 본 논문은 위치 정보를 단순히 더하는 것이 아닌 token representation 자체를 변환하는(multiplicative) 방식으로 접근한다.
Rotationary Positional Embedding (RoPE)
본 논문에서 결국 도달하고자 하는 것은 다음과 같다:

이 말은 즉, 위치 정보가 포함된 query와 key가 내적으로 표현될 때 그 표현이 각 토큰의 내용 정보와 분리된 위치 간 상대 거리에만 의존하도록 만들고 싶은 것이다. 이를 위해 RoPE는 각 토큰 embedding에 대해 위치에 따른 회전 변환을 적용한다. 일단 2-dimensional로 살펴보자:
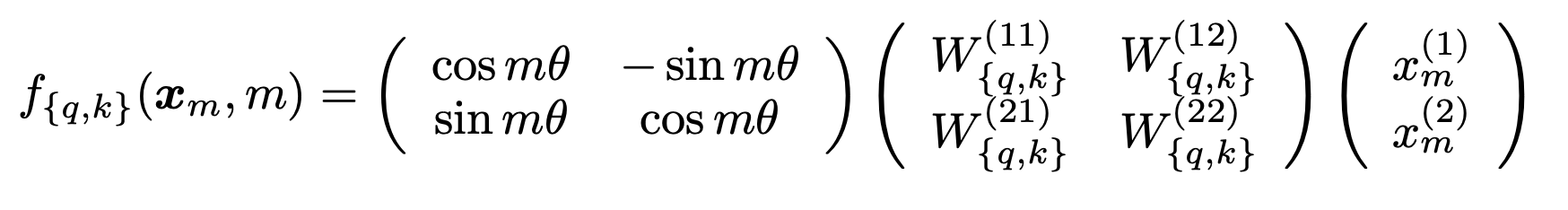
이 rotation matrix를 $R(m)$이라 할 때, attention score은 다음과 같이 계산된다:

3, 4번째 줄의 전개 결과는 Rotation matrix의 property에 의한 결과이다. 이를 좌표 형태로 풀어 쓰면,
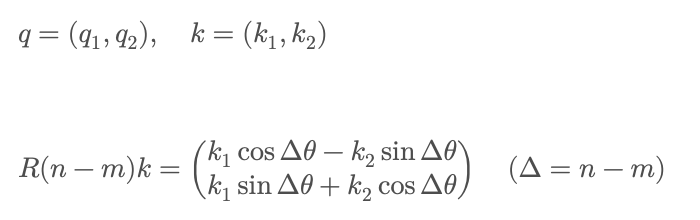
따라서

이제 이것은, key 벡터를 상대 위치 $\Delta$만큼 회전시킨 뒤, query와의 내적을 계산한다의 의미를 갖게 되는 것이다. 이 관점에서 보면, RoPE의 핵심은 다음과 같이 정리된다:
- 위치 정보는 더 이상 feature로 추가되지 않음
- 대신, vector space 상의 변환(회전)으로 작용
- 그 결과 attention이 자연스럽게 translation invariant한 구조를 갖게 됨
이제 General한 form을 보자.

여기서 혼란스러운 포인트가 발생한다. 앞서 2차원에서의 유도를 통해, RoPE는 key 벡터를 상대 위치 $\Delta$만큼 회전시킨 뒤 query와 내적을 계산하는 구조라는 것을 확인했다. 이 관점에서는 매우 직관적으로 이해되지만, 논문에서 제시하는 일반적 형태는 이상하게도 2차원 rotation matrix가 블록 단위로 연결된 구조가 된다. 자연스럽게 나올 의문은, 굳이 2차원씩 나눌 필요가 있으며, 3D나 d차원 전체에 대해 한 번에 변화를 정의할 수는 없는가에 관한 것이다.
이 질문에 대한 답은 RoPE의 핵심 제약에서 나온다. 우리가 만족시키고 싶은 조건은 다음과 같았다:

즉, 두 위치 m, n에 대한 변환이 결합될 때, 그 결과가 반드시 상대 위치 n-m에 대한 하나의 변환으로 표현되어야 한다. 이 조건은 단순한 성질처럼 보이지만, 사실상 변환이 덧셈 구조를 보존하는 group representation이어야 함을 의미한다. 이를 보장하는 것은 2차원 Rotation matrix가 block diagonal로 연결된 구조이고, 결국 위의 선택은 아주 자연스러운 결과가 되는 것이다.
RoPE는 단순히 절대 위치에 의존을 안하고, 상대 위치만 반영한다는 것에만 장점을 지니는 것은 아니다. RoPE가 기본적이로 sinusoidal 기반의 회전 구조이기 때문에 학습 시 보지 못한 긴 sequence에 대한 일반화를 잘 하는 것도 장점이다. 더 중요한 것은 long-term decay에 있다.
RoPE의 attention score는 다음과 같은 형태로 표현될 수 있다:

여기서

는 i번째 2차원 subspace에서의 query와 key 간의 유사도를 의미한다. 즉, RoPE는 전체 attention을 하나의 값으로 계산하는 것이 아니라, 각 2차원 차원쌍에서의 유사도 h_i들을 서로 다른 주파수의 회전과 결합하여 합산하는 구조를 가진다.
이제 핵심은 $e^{i(n-m)\theta}$항이다. 각 차원쌍마다 서로 다른 $\theta_i$가 사용되기 때문에, 상대 거리 n - m가 커질수록 각 항의 위상(phase)이 서로 다르게 변한다. 그 결과, 다음과 같은 현상이 발생한다:
$\Delta \approx 0$일 때:
- 모든 회전이 거의 동일한 방향을 가짐
- 각 h_i가 정렬된 상태로 더해짐
- → attention 값이 크게 유지됨
$|\Delta|$가 커질 때:
- 각 항의 회전 각도가 서로 크게 달라짐
- 서로 다른 방향으로 퍼지면서 상쇄(cancellation) 발생
- → attention 값이 작아지는 경향
즉, RoPE는 별도의 decay 함수를 명시적으로 설계하지 않더라도, 서로 다른 주파수의 회전 항들을 합산하는 구조만으로 상대 거리가 증가할수록 attention이 감소하는 효과를 자연스럽게 유도한다. 이러한 성질은 자연어 처리에서 가까운 token은 더 반영하고, 먼 token은 덜 반영하는 inductive bias와 잘 맞는다
실험은 건너뛰도록 하겠다...ㅎㅎ
'논문 리뷰 > NLP' 카테고리의 다른 글
| Why DPO is a Misspecified Estimator and How to Fix It 논문 리뷰 (0) | 2026.02.22 |
|---|---|
| Soft Adaptive Policy Optimization 논문 리뷰 (0) | 2026.01.29 |
| Large Language Diffusion Models 논문 리뷰 (0) | 2026.01.25 |
| Qwen2.5-Math 논문 리뷰 (3) | 2026.01.21 |
| KTO 논문 리뷰 (0) | 2025.12.06 |