SimCSE: Simple Contrastive Learning of Sentence Embeddings
Summary & key Contribution
이 논문은 간단한 대조 학습 프레임워크로, 문장 임베딩의 성능을 SOTA 수준으로 크게 향상시킬 수 있음을 보여준다.
또한 constrastive learning objective가 사전 학습된 임베딩의 anisotropic space을 보다 균일하게 정규화하며, supervisment가 있는 경우 positive pair 간의 정렬을 개선한다는 사실을 입증한다.
- anisotropic space: not uniformly distributed with respect to direction, 특정 공간에 분포해 있음
해당 논문의 훈련 방법과, constrastive learning objective을 소개한 후 이 논문의 발견 사항 중 하나인 dropout가 주는 representation에 관한 이점과, minimal data augmentation을 가져다주는 것에 관해 다루고자 한다.
2. Preliminary
Constrastive Learning
Constrastive learning은 표현 학습 중 하나로, 의미상 유사한 표현은 임베딩 공간에서 가까이 두고, 그렇지 않은 표현의 경우 임베딩 공간에서 멀리 두도록 학습한다.

| 기호 | 의미 |
|---|---|
| $h_i$ | anchor 문장의 임베딩 벡터 |
| $h_i^+$ | anchor 문장과 의미적으로 유사한 positive pair 문장 임베딩 |
| $h_j$ | anchor 문장과의 비교 대상 전체 (positive + negatives) |
| $\text{sim}(a,b)$ | 보통 cosine similarity 사용 → $\frac{a \cdot b}{|a||b|}$ |
| $\tau$ | temperature hyperparameter (분모 분자의 분포를 조절) |
| $N$ | mini-batch 내 문장 개수 |
해당 Loss를 관찰하면, $h_i$와 $h_i^+$ 간의 유사도가 크게, 나머지와는 유사도가 작게 만들어, 최대한 분자/분모를 1에 가깝게 만들어 Loss를 작게 만들도록 유도됨을 확인할 수 있다.
Question in Constrastive Learning
- How to construct positive pairs?: CV의 경우, 동일한 사진을 두고 crop, flip, distortion 등의 변환을 가함으로써 positive pair을 만들 수 있다.
- 그러나 NLP task의 경우 이러한 data augmentation을 적용하는 것이 어려운데, 애초에 NLP는 discrete하기 때문이다.
- Dual-Encoder approach: 두 유사한 passage 데이터셋을 바탕으로 인코딩을 적용할 수 있다. 예를 들어 Question-Answer 데이터셋을 바탕으로 positive pair을 두어 두 passage에 대해서 encoding을 적용할 수 있다. 그러나 쉽게 알 수 있듯이, 이러한 쌍 자체는 만들기에 비용 문제를 피할 수 없다.
Alignment and Uniformity
Contrastive learning의 품질을 평가하는 중요한 기준 중 두 가지는 바로 alignment와 uniformity이다.
Alignment
Alignment는 의미적으로 유사한 문장 쌍 (positive pair)이 임베딩 공간 상에서 얼마나 가깝게 정렬되어 있는가를 측정한다.
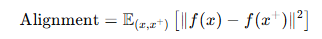
Positive pair 사이의 L2 거리 평균이 작을 수록 alignment가 잘 되어 있다고 본다.
Uniformity
Uniformity는 전체 임베딩 공간에서 벡터들이 얼마나 균일하게 퍼져 있는가를 측정한다.
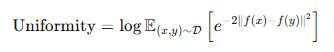
3. Architecture
Unsupervised SimCSE
앞서 constrastive learning에서 positive pair을 가져오는 방법은 간단하다. $x_i = x_i^+$로 두되, dropout mask을 두 번 두는 것이다. 예를 들어, $p=0.4$로 가정하고 $x_i = (0.1, 0.3, 0.4, 0.2, -1.2)$에 대해서 dropout mask를 적용해보면,
한 번은 $(1, 0, 1, 0, 1)$, 다른 번은 $(0, 1, 1, 1, 1)$이 생기게 되어 이를 $x_i$에 적용하면 element-wise product를 적용하고 이후 inverted-dropout을 적용하면 된다. Inverted dropout을 적용하는 이유는 train과 test 시의 출력 기댓값을 동일하게 맞추기 위함이다.
이렇게 적용한 dropout는 애초에 같은 $x_i$에서 비롯했기 때문에, 자연스러운 positive pair이 되는 것이다.
Dropout noise as data augmentation

Dropout을 하는 것이 STS-B 벤치마크 테스트에서 더 좋은 성능을 보여준다. 왜 그런 것인지 알아보자.
- Dropout는 작은 purturbation을 유도한다. 즉 의미는 같되 표현은 살짝 다른 벡터를 만들어준다. Minimal 변화만 가져와주기 때문에 alognment가 유지되며, 표현에 noise가 추가됨으로써 representation이 무너지지 않고 공간에 균일하게 퍼질 수 있는 것이다.
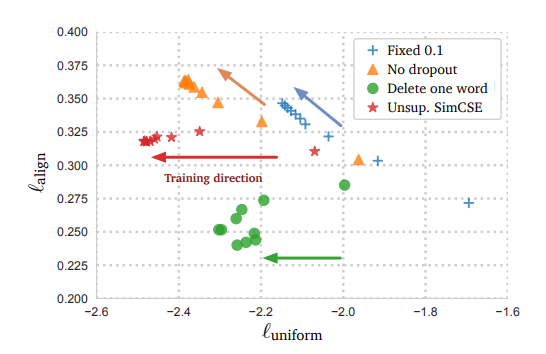
(단어를 하나 삭제하는 경우 alignment와 uniformity에서 효과가 떨어지는 것을 확인해보자)
Supervised SimCSE
비지도학습으로 SimCSE를 학습한 다음, 지도 학습 데이터를 활용하여 성능을 더욱 향상시킬 수 있다.

Hard negative 쌍을 추가하는 것이 성능을 더욱 올릴 수 있음을 확인하자.
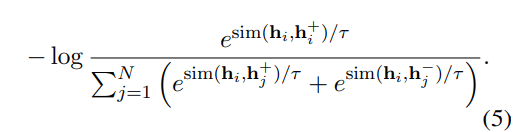
4. Anisotropy
필자는 해당 논문이 제공하는 수학적 서술에 상당한 논리 비약이 있다고 판단하여, 간단히 그림만 보여주고자 한다.

다른 방법들에 비해서 정렬과 등방성에서 우수함을 확인할 수 있다.
5. Conclusion
SimCSE는 별도의 복잡한 구조나 대규모 supervision 없이도, 간단한 contrastive learning 프레임워크와 dropout 기반의 positive pair 생성만으로도 문장 임베딩의 정렬(alignment)과 균일도(uniformity)를 동시에 개선할 수 있음을 실증적으로 보였다.
또한, dropout 자체가 일종의 minimal data augmentation 역할을 하며, representation space의 anisotropy 문제를 완화하는 데 기여한다는 점은 주목할 만하다.
하지만 논문 내의 수학적 정당화, 특히 anisotropy와 고유값 분포(flattening) 관련 논리는 경험적 관찰에 크게 의존하며, 엄밀한 수학적 추론이 부족한 한계가 있다.
향후 연구에서는
- dropout 외의 다양한 noise 기법과 augmentation 방식 실험,
- 더 정교한 이론적 분석,
- multilingual setting이나 domain adaptation 상황에서의 성능 검증
등이 유의미한 확장 방향이 될 수 있다.
'논문 리뷰 > NLP' 카테고리의 다른 글
| DPO 논문 리뷰 (3) | 2025.08.12 |
|---|---|
| AlphaEdit 논문 리뷰 (3) | 2025.08.09 |
| Orca 2 논문 리뷰 (3) | 2025.08.08 |
| Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo 논문 리뷰 (2) | 2025.08.07 |
| InstructGPT 논문 리뷰 (1) | 2025.08.05 |