ALPHAEDIT: NULL-SPACE CONSTRAINED KNOWLEDGE EDITING FOR LANGUAGE MODELS
엄청 좋아하는 논문이라 리뷰하고 싶었는데... 이상한 고집이 있어 이전 model editing 기법들을 리뷰하려고 수식을 막 쓰다가 열받아서 포기했었다. 그래서 이 논문을 스타트로 model editing에 대한 방법론을 리뷰하고자 한다.
Summary
본 논문은 모델의 잘못된 응답에 대한 해결책으로 모델의 패러미터를 일부 수정하는 방법론에서 패러미터 $W$의 null space를 활용하는 방법을 제시한다.
이러한 Model Editing의 이전 방법론들은 모델의 수정하고자 하는 지식 $e_1$과 수정으로 인해 에러가 발생할 수도 있는 기존의 지식 $e_0$간의 밸런스를 지키지 못하였는데, 본 논문은 이러한 문제를 해결할 수 있음을 보여준다.
이 접근법은 대규모 LLM처럼 전체 재학습이 불가능하거나 비효율적인 경우, 정확하고 국소적인 지식 편집을 위한 강력한 대안을 제시한다.
Preliminary
본 논문은 특히 언어모델의 잘못된 응답에 맞추어서 이를 수정하는 방법을 다루기에, 다른 아키텍처는 다루지 않겠다.
Auto-Regressive LM

$l$번째 hidden representation은 이전 단계의 hidden representation과 attention block $a^l$, 그리고 언어모델이 참고하는 지식 $m^l$의 합으로 이루어져 있다. $l$번째 단계의 $m$은 다음과 같은 식으로 구성된다:
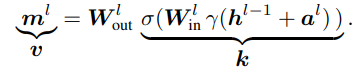
여기에서 $W_{in}$으로 연결된 $k$ 부분과 $W_{out}$은 linear associative memory라 불리는데, 이는 모델 내부의 information(knowledge라 보는 것이 낫겠다) retrieval을 위한 key-value storage로서 기능한다는 것을 확인할 수 있다. 즉 $k$ 부분에서 어떤 지식을 참고해야 할지 정하고, $W_{out}$를 통해 key와 실제 지식인 value를 mapping시켜준다고 생각하면 된다.
Model Editing in LLMs

$K_1$과 $V_1$은 수정하고자 하는 지식이고, $K_0$와 $V_0$는 보존하고자 하는 지식이다. 왜 이렇게 식을 구성하냐면, 잘못된 지식을 수정하는 과정에서 반드시 기존 지식도 영향을 받을 수밖에 없으며, 극단적으로는 catastrophic forgetting까지 일어날 수 있는 일이기 때문이다.
최적의 $\Delta$를 찾았다고 가정하자. 그렇게 되는 경우
- $(W+\Delta)K_1 \approx V_1$ (원하는 대로 수정이 잘 되었음)
- $(W+\Delta)K_0 \approx V_0$ (기존 지식은 거의 바뀌지 않았음)
을 달성하게 된다. 다시 말해서 최적의 $\Delta$는 cherry picking마냥 딱 원하는 부분만 수정하고 나머지 부분은 건드리지 않는다는 것이다. 이에 대한 실제 closed form solution도 존재한다:

그러나 보존할 지식 자체가 LLM의 범위에서 너무 크기 때문에, 실제로는 100,000개 정도의 지식만 랜덤하게 추출한 후 모델 수정을 시도한다고 한다.
그럼에도 불구하고 이것 자체가 말도 안되는 일인 이유는:
- 역행렬을 구하는 과정의 계산량은 $O(d^3)$이며, LLM의 $d$는 압도적으로 크기 때문에 연산과 메모리 비용이 지나치게 증가하고
- 원하는 Key $K_0, K_1$을 뽑아낸다는 것 또한 불가능에 가깝기 때문이다.
Null Space
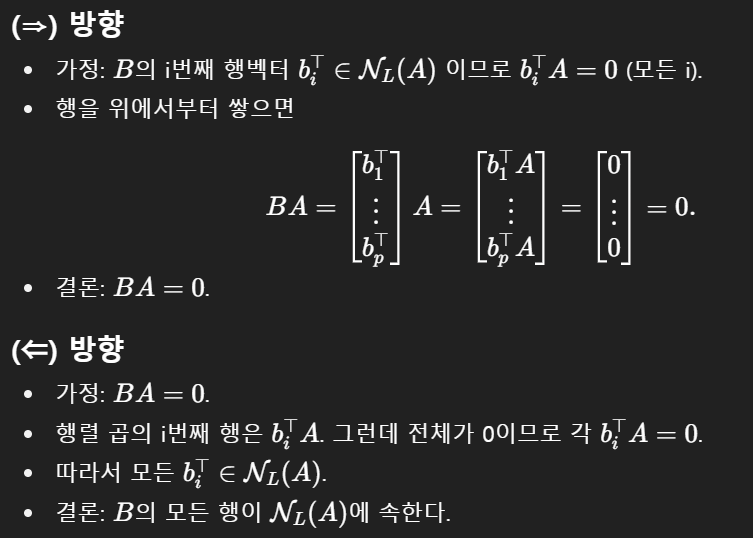
$$ B \text{ is in the left null space of } A \text{ if and only if } BA = 0 $$
GPT 5 형님이 증명을 잘 하신다:
Method
$(W+\Delta)K_0 \approx V_0$을 기억해보자. 지금은 $(W+\Delta)K_0 = V_0$으로 바꾸겠다.
만약 위의 식이 성립한다면 $\Delta$는 $K_0$의 left null space에 존재하는 것이고, 여기서 아이디어는 perturbation이 $K_0$의 left null space에서 이루어진다면 기존 지식을 수정하지 않고도 model editing을 할 수 있다는 뜻이다.
그러나 $K_0$는 보통 $d_0 × 100,000$차원(위에서 말한 방법대로)이기에 직접적으로 null space를 구하는 것은 불가능하다. $K_0$의 left null space의 basis는 $d_0$ 차원 벡터로 이루어져 있으므로, 이를 대신하여 non-central covariance matrix인 $K_0K_0^T$를 통해 계산 문제를 우회할 수 있다.
즉 $K_0$의 left null space는 $K_0K_0^T$의 null space와 동일하며, 이렇게 차원을 낮추는 방식(보통 $d_0$가 100,000보다 압도적으로 작다)이 null space를 찾는 것의 해결책인 것이다.
이제는 null space를 찾기 위해서, SVD를 적용할 수 있다. 하지만 대칭행렬이므로 diagonalization이라고 보면 되겠다. 여기에서 만약 eigenvalue로 이루어진 matrix $\Lambda$에 $0$이 존재하는 component가 있다면, 그 위치에 해당하는 eigenvector은 $K_0$의 left null space의 basis를 이룰 수 있는 것이다.
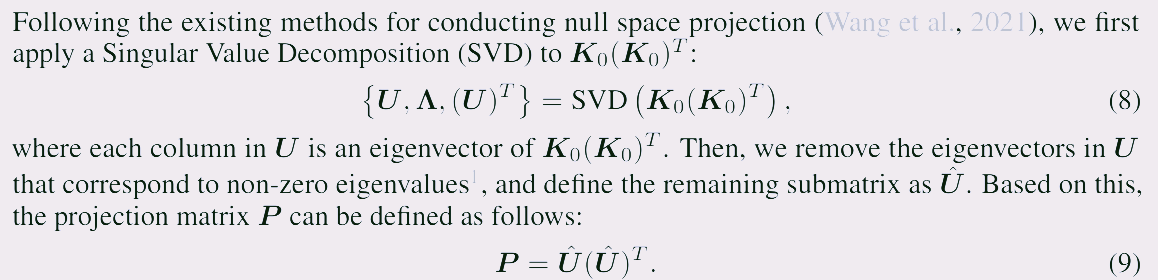
논문에서 설명하듯이, 여기서 non-zero eigenvalue를 가지고 있는 eigenvector을 제거함으로써 $P \cdot K_0K_0^T=0$, $PK_0=0$을 달성할 수 있으며 우리는 $\Delta$를 $P$와 곱해주면서 안전하게 모델을 수정하게 할 수 있는 것이다.

결국 optimal solution을 찾아가는 식은 다음과 같이 되는데,
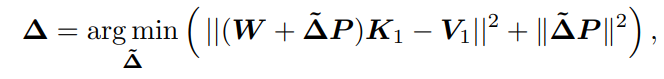
여기에서 붙은 regularization term $||\Delta P ||^2$는 stable convergence를 위한 것이라고 한다.
더 나아가서, 순차적인 edit task를 한다고 가정하자. 그렇게 한다면 업데이트 된 이전의 지식을 갑자기 없애버리면 또 문제가 생기니, 본 논문은 다음과 같은 regularization term을 두는 것을 제안한다.
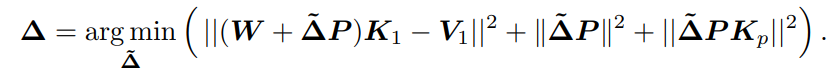
또한 이 논문은 이전 Model Editing 기법 중 하나인 MEMIT와의 차이점을 보여주는데, 우선 귀여운 그림부터 보고 가자:

MEMIT는 여전히 $K_0$ 자체를 분리하여 문제 해결을 할 수 없는 것을 확인할 수 있다. 반면 AlphaEdit은 애초에 $K_0$자체를 너무 잘 분리를 했기에 기존 지식의 망각 자체를 걱정할 필요가 없게 되는 것이다.

Experiment
본 논문은 다음과 같은 연구 질문을 바탕으로 실험을 진행하였다:
- RQ1: AlphaEdit가 순차적인 editing process에서 얼마나 성능을 보이는가? 이전 방법론들의 한계인 기존 지식의 붕괴 또는 망각을 완화할 수 있는가?
- RQ2: 실제로 edit된 LLM이 일반적 능력, 고유한 능력을 잘 유지할 수 있는가?
- RQ3: 갱신된 지식에 대한 과적합을 방지할 수 있는가? 특히, post-edited LLM의 hidden representation의 shift를 피할 수 있는가?
- RQ4: 기존의 model editing 방법론들도 null space projection 코드를 추가하는 것만으로도 성능이 증가하는가?
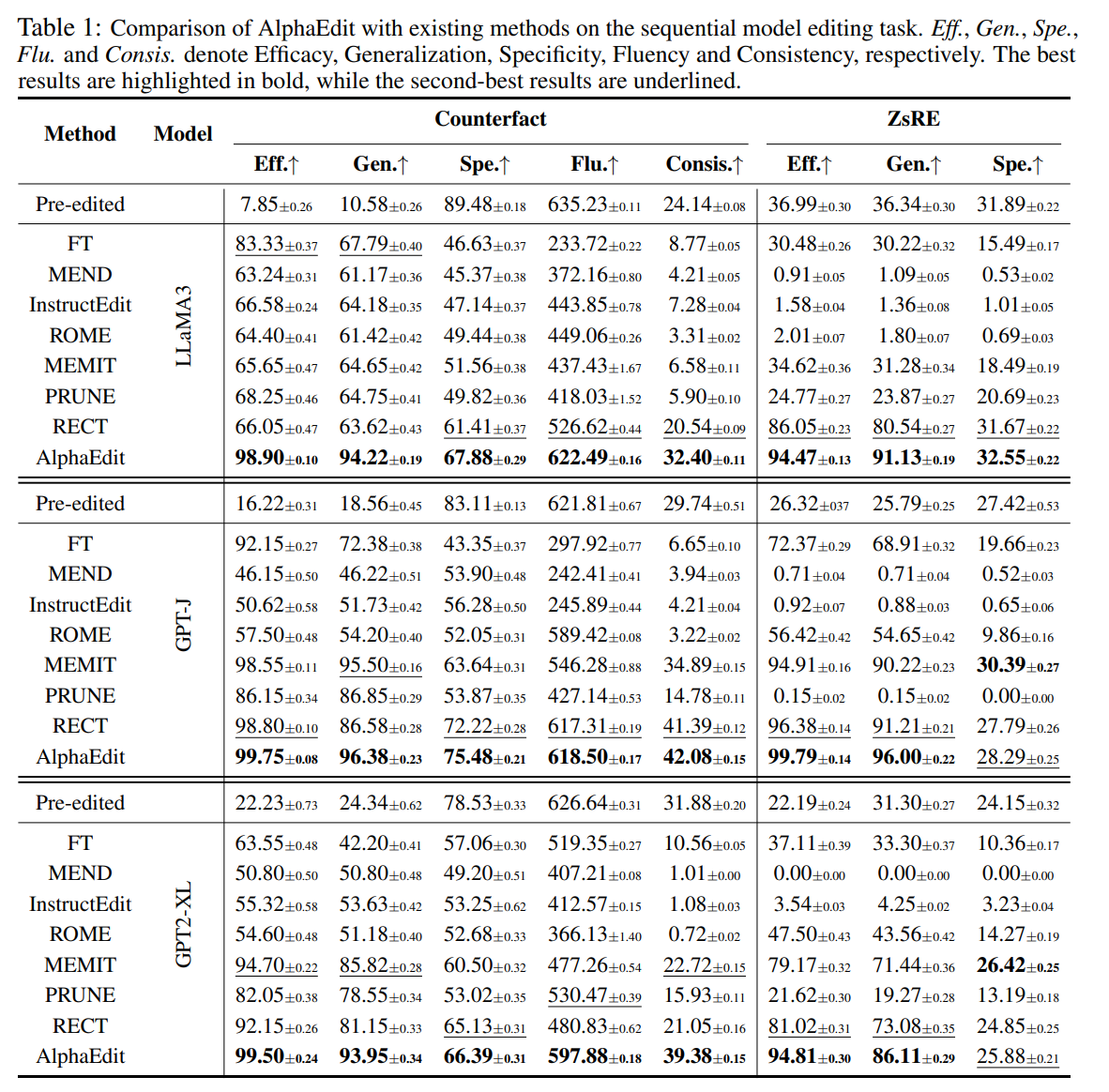
Edit 당 100개의 샘플, 총 2000개의 샘플에 대해서 edit을 한 후의 결과이다. 성능 보존이 잘 되며, 특히 성능이 더욱 올라간 것은 굉장히 인상적이다. (RQ1)

우선 6개의 benchmark test에서 다른 방법론들에 비해서 매우 우수한 것을 볼 수 있다. 특히 순차적인 editing 과정에서 일정 수의 editing이 지나면 모델 붕괴가 오는 다른 방법론들에 비해서 안정적으로 잘 살아남는 것을 확인할 수 있다. 즉 고유한 능력을 잘 보존한다고 볼 수 있다. (RQ1, RQ2)

Pre-edited LLM과 Post-edited LLM의 representation을 비교해본 결과이다. 다른 방법론은 전부 다 분포가 뒤바뀌는 것을 볼 수 있는데, AlphaEdit은 최소한의 shift를 보여주는 것을 확인할 수 있다. (RQ3)
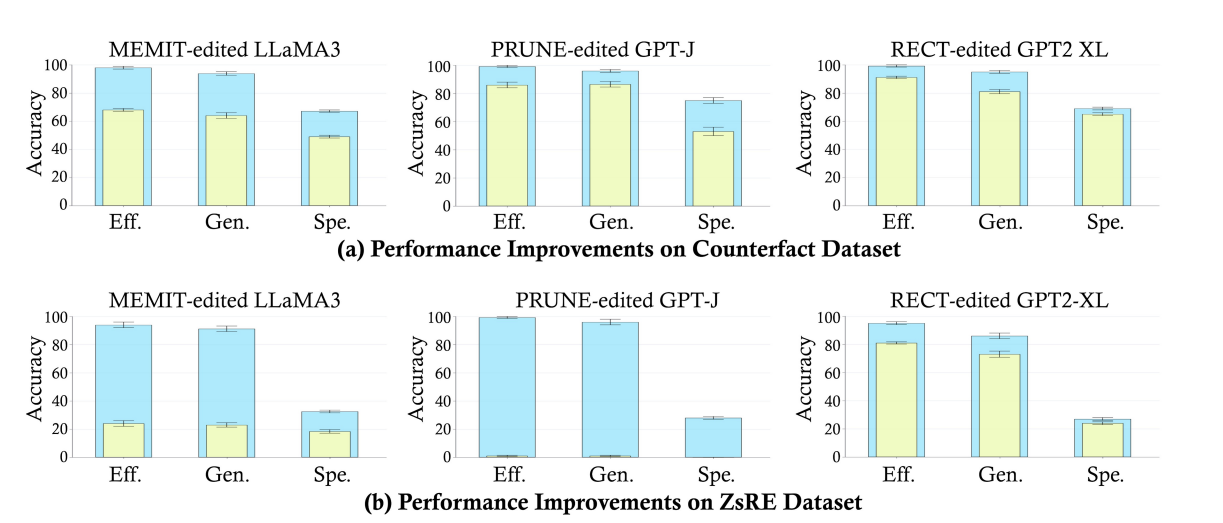
노란색은 기존 방법론이고, 파란색은 단순히 AlphaEdit의 null space projection 관련 코드를 추가한 후의 결과물이다. 더 말할 필요가 없을 것 같다! (RQ4)
Conclusion
Significance
Null space projection을 통해서 기존 지식 자체를 건드리지 않으면서 필요한 부분만 수정할 수 있다는 것이 이 논문의 의의다. 무엇보다 기존 기법에도 충분히 범용적으로 적용이 가능하며 모델 또한 여러 모델로 실험함으로써 실험 설계 자체도 아름답다고 할 수 있다.
Limitations
더 큰 LLM을 다룸에 있어서 얼마나 효과적일지에 대한 검증은 추가적으로 필요하다고 본다. 왜냐하면 null space 계산 자체를 우회하기는 했지만, 모델 크기가 압도적으로 증가하는 경우 이 방법론이 100% 효과적일 것이라고는 생각하지 않는다.
또한 null space projection은 기존 key-value mapping 자체를 건드리지는 못한다. 즉 구조적으로 key와 value 간 관계를 재구성해야 하는 경우 편집에 다소 부적합할 수 있겠다는 생각이 든다.
하지만 나는 이 논문을 매우 칭송하며 GOAT 논문이라고 말하지 않을 수가 없을 것 같다!!!!
'논문 리뷰 > NLP' 카테고리의 다른 글
| Lifelong Knowledge Editing requires Better Regularization 논문 리뷰 (6) | 2025.08.12 |
|---|---|
| DPO 논문 리뷰 (3) | 2025.08.12 |
| Orca 2 논문 리뷰 (3) | 2025.08.08 |
| Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo 논문 리뷰 (2) | 2025.08.07 |
| InstructGPT 논문 리뷰 (1) | 2025.08.05 |