A Minimalist Approach to Offline Reinforcement Learning
Summary
Offline RL은 환경과의 상호작용 없이 고정된 데이터셋만으로 학습해야 하기 때문에, 온라인 RL에서 사용되는 일반적인 off-policy 알고리즘을 그대로 적용할 경우 정책의 외삽 오류로 인해 성능이 크게 저하되는 문제가 있다. 기존의 Offline RL 알고리즘들은 이를 해결하기 위해 행동 정책 추정, 생성 모델 학습, 샘플링 기반 log-sum-exp와 같은 복잡한 메커니즘을 도입해 왔으나, 이러한 접근은 구현 복잡도와 튜닝 난이도를 높이고 재현성을 저해한다. 이에 본 논문은 TD3의 정책 업데이트 단계에 행동 모방(BC) 정규화 항을 추가하는 최소한의 변경만으로, 정책을 데이터 분포 근처에 유지하면서도 경쟁력 있는 성능을 달성하는 오프라인 RL 알고리즘 TD3-BC를 제안한다.
Challenges in Offline RL
우선 본 논문에서 특별히 언급하는, Offline RL에서 고려해야 하는 것들에 대해서 살펴보자.
1. 학습 중 정책을 환경에서 실행해 검증할 수 없다.
Offline RL에서는 정책이 얼마나 잘 작동하는지, 어떤 업데이트가 유의한지, 언제 학습을 멈춰야 하는지에 대해서 환경을 통한 검증이 사실상 불가능하다. 따라서 정책 업데이트가 본질적으로 보수적이어야 한다.
2. 정책 개선은 반드시 데이터 분포(support) 내부에서만 일어나야 한다.
Offline setting에서 actor가 데이터에 없는 행동을 선택하는 순간, Q-value는 근거없는 extrapolation이 되어버린다. 따라서 정책은 데이터셋 내부의 행동 근처에만 머물러야 한다.
3. Critic의 일반화 능력은 Offline RL에서 항상 좋은 것이 아니다.
Critic은 TD로 학습되지만, 실제로 신뢰 가능한 영역은 데이터 분포 근처 뿐이다. 즉 $Q(s,a) \approx r + \gamma Q(s',\pi(s')$로 학습되는 과정을 가지는데, 이 때 $a'=\pi(s)$가 데이터에 없는 행동인 경우 의미가 사라진다. Actor-critic 구조이기에, 그렇게 잘못 추정한 $Q(s,\pi(s))$를 actor가 믿게 되면 악순환의 문제가 생긴다.
4. Offline RL은 대규모 데이터셋을 전제하기 때문에 계산 효율을 중요시해야한다.
CQL같은 경우는 log-sum-exp 연산을 필요로 하며, Fisher-BRC는 별도의 생성 모델 학습을 학습한다. 이것은 대규모 고정 데이터를 활용해야 한다는 offline RL의 특성상 병목이 심해진다는 문제점이 존재한다.
5. 정책의 평균 성능보다는 정책의 분산, 성능 quantile, 민감도가 더 중요하다.
Offline RL은 일반적으로 risk에 대해서 민감하게 평가되어야 한다는 것을 의미한다.
아래 실험 결과에서 확인할 수 있듯이, 아무리 평균적인 결과가 좋다고 하더라도 risk에 대해서 방어하지 못하면 무의미해진다.
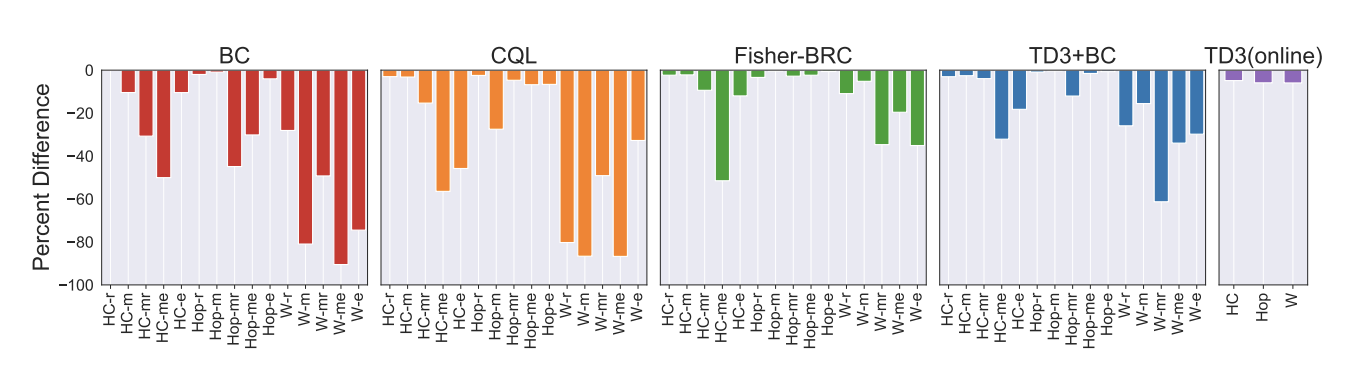
물론 이 논문이 모든 것을 전부 해결한 것은 아니지만, 우선은 어떤 방식으로 이러한 고려사항을 반영했는지 확인해보자.
TD3-BC
알고리즘이 단순하다. Policy에 대해서 제약을 걸어두는 방향인데, dataset 내부에 없는 action에 대해서 policy가 선택하지 않도록 penalty를 주는 방식이다.
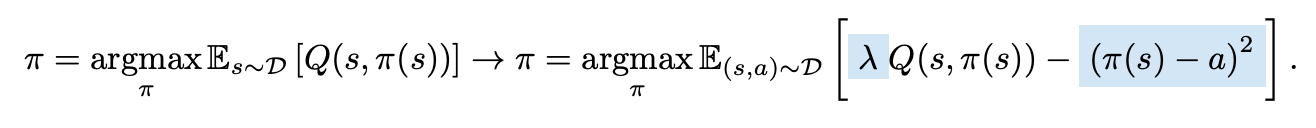
다음 내용도 확인해보자:

여기서 스케일링(scale)을 적용한 것이 합리적임을 알 수 있다. BC 항은 $\|\pi(s)-a\|^2$으로 action 범위에 대해 bound 되어 있으며, 일반적인 bound scale이 작은 편이다. 반면 Reward는 스케일이 다양할 수 있으며, 이에 따라 $Q$의 스케일이 달라지기 때문에 아무런 보정이 없는 경우 해당 constrained maximization이 BC 항을 무시한 채 일어날 가능성이 있다.
이에 대해 처음부터 새로운 하이퍼파라미터를 두는 것은 일반적으로 좋지 않은 선택지이기에, 본 논문에서는 $\lambda = \frac{\alpha}{ \mathbb{E}_{(s,a)\sim D}[|Q(s,a)|] }$으로 설정하였다. 결과적으로 $\lambda Q \approx \alpha \cdot \frac{Q}{\mathbb{E}|Q|}$로 보정되어, BC 항과 유사한 order에서 경쟁할 수 있게 된다.
Experiments
사실 실험에서 잘 나왔다고는 하는데... 솔직히 좀 과장된 감이 있다 ㅋㅋ 일단 성능은 다음과 같다:

전반적으로 높은 성능을 가져오면서, 동시에 하이퍼패러미터 튜닝 부담이 적은 것은 큰 강점이라고 볼 수 있다.

Minimal approach답게 computation cost가 낮은 것을 확인할 수 있다.
사실 그런데 앞서 본 실험 결과에서 다소 아쉬운 문제가 있다.
Worst 성능에 대해서 보여주는 것은, eval을 늘리는 경우 worst 성능이 더 나빠질 가능성이 높으며 real world에서 worst 케이스에 대한 진단이 중요하다며 mujoco의 stochastic init에서의 worst case를 보여주는 것은 사실 설득력이 많이 낮다. 정량적 지표로 판단하기에는 사실 무리가 많기 때문에, 75% quantile로 검증하는 것이 맞지 않았나 싶다.
이만 리뷰를 마치도록 하겠다!
'논문 리뷰 > RL' 카테고리의 다른 글
| Flow Q-Learning 논문 리뷰 (0) | 2026.01.28 |
|---|---|
| Prioritized Generative Replay 논문 리뷰 (1) | 2026.01.25 |
| FEDORA 논문 리뷰 (0) | 2026.01.13 |
| PlaNet 논문 리뷰 (0) | 2025.12.17 |
| HER 논문 리뷰 (1) | 2025.12.11 |