Momentum Contrast for Unsupervised Visual Representation Learning
Summary
본 논문은 비지도 표현 학습의 효율성을 높이기 위해 Momentum Contrast(MoCo) 를 제안한다. MoCo는 큐(queue) 기반의 사전(dictionary) 메커니즘을 도입하여, mini-batch 크기에 구애받지 않고 대규모 negative sample을 활용할 수 있도록 설계되었으며, 이를 통해 표현 학습의 일관성과 성능을 동시에 확보한다.
Method
Contrastive Learning as Dictionary Look-up
본 논문에서는 대표적인 대조학습(contrastive learning) 손실 함수 중 하나인 InfoNCE loss를 사용하며, similarity 측정에는 내적(dot product)을 적용한다.

여기서 $q$는 쿼리 인코더 $f_q$가 입력 샘플 $x^q$를 통해 얻은 표현 벡터이고, $k_+$는 동일한 원본 이미지로부터 다른 증강 기법을 적용한 후 키 인코더 $f_k$를 통해 얻은 positive key에 해당한다. 나머지 $\{ k_1, k_2, ... k_N \} $는 큐(queue)에 저장된 negative key들로, 다른 이미지에서 추출된 표현들이다.
InfoNCE loss는 직관적으로 (K+1)-way softmax 분류 문제로 해석할 수 있다. 즉, 쿼리 $q$가 올바른 positive key $k_+$를 “정답”으로 맞추도록 학습하는 과정이다. Loss는 query–positive pair의 similarity를 높이고, 동시에 query–negative pair의 similarity를 낮추는 방식으로 작동한다.
이러한 학습 목표를 통해 인코더는 데이터의 레이블 없이도, 같은 이미지의 서로 다른 뷰(view)는 가깝게, 서로 다른 이미지들은 멀리 떨어뜨리는 표현 공간(embedding space) 을 학습할 수 있다. 결과적으로 학습된 표현은 다양한 다운스트림 작업(예: 분류, 탐색, 전이학습)에서 일반화 성능을 보이는 강력한 feature representation이 된다.
Momentum Contrast
실제로 얻고자 하는 query encoder $f_q$는 앞서 설명된 InfoNCE loss로 학습되지만, key encoder은 momentum 기반으로 학습된다. 이때 momentum은 기존 key encoder의 패러미터와 query encoder 패러미터의 가중평균이다.

여기에서 $m$을 0.99 또는 0.999와 같이 큰 수로 잡으면, key encoder의 패러미터는 천천히 움직이기 때문에 query encoder가 결국 비교하게 되는 key들에 대한 안정적인 학습 래퍼런스가 되는 것이다.
여기에서 왜 queue 기반 학습 방법이 나오는지에 대한 이유가 나오는데, 우선 reference key를 제공하는 방법에 관한 다른 방법들을 소개해보도록 하겠다.
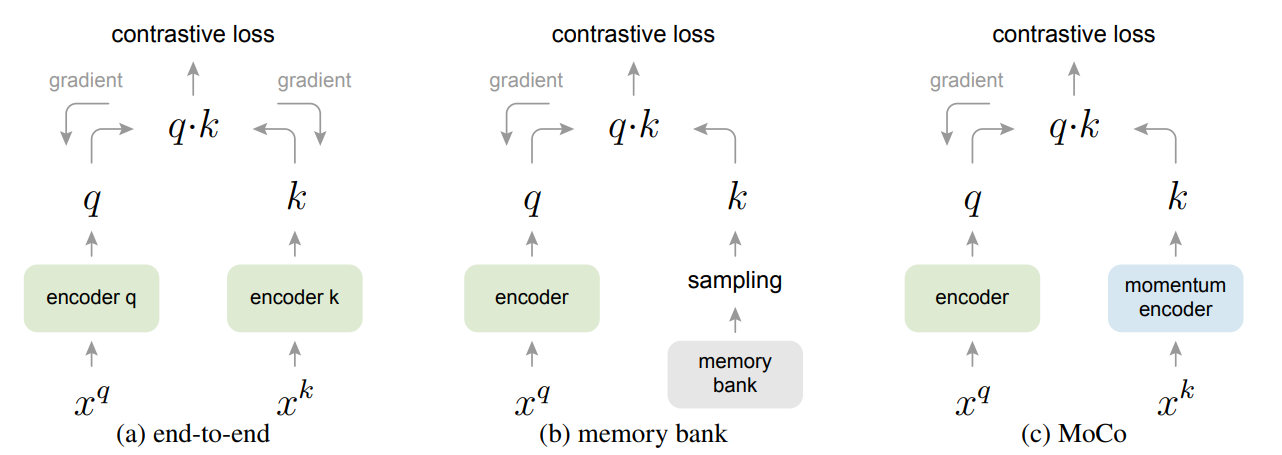
- End-to-end 방식의 경우 key encoder 모델 또한 constrastive loss로 학습하는 경우를 의미한다. SimCLR가 대표적인 방법론인데, 이 방법은 mini-batch 학습 시마다 매번 key representation vector들을 생성하고 저장해야 하기 때문에 GPU의 연산 및 메모리 비효율성이 나타난다.
- Memory bank 방식은 정적인 key representation vector을 미리 저장해두고 샘플링한 후 꺼내 쓰는 방식이라 메모리나 연산에 있어서 자유롭지만 몇 번의 iteration 이후에는 query encoder가 변하기 때문에, 샘플들이 레퍼런스로서 적절하지 않게 된다는 문제점이 있다.
이 문제는 queue 기반 구조와 momentum encoder를 결합한 방식으로 해결된다. 학습 과정에서 생성된 mini-batch의 key representation은 queue에 저장되며, 이후 각 학습 단계에서 negative sample로 활용된다. Queue는 FIFO 정책에 따라 오래된 표현을 제거하고, 제거된 만큼의 공간은 업데이트된 momentum encoder가 생성한 새로운 표현으로 채워진다. 이를 통해 사전(dictionary)은 지속적으로 최신 정보를 반영하면서도 일관성을 유지한다.
이런 방식을 사용하는 경우 query encoder은 momentum encoder의 표현을 바탕으로 안정적인 학습이 가능하며 GPU 메모리 및 연산 부담에서 자유로워질 수 있다.
Shuffling BN
본 논문에서는 추가적으로 "The model appears to “cheat” the pretext task and easily finds a low-loss solution. This is possibly because the intra-batch communication among samples (caused by BN) leaks information." 라는 문제 상황을 제시하는데, 이것이 무엇인지 알아보자.
Batch Normalization은 mini-batch 내 샘플들의 평균과 분산을 계산하여 각 샘플을 정규화한 뒤, 학습 가능한 파라미터 $\gamma$, $\beta$ 를 적용해 표현력을 보완하는 방식이다. 그러나 MoCo에서 제시된 query encoder와 momentum encoder가 동일한 batch statistics를 공유하게 되면, 모델이 올바른 표현을 학습하지 않고도 BN 통계에 의존하여 query와 key를 인위적으로 비슷하게 만드는 cheating 현상이 발생할 수 있다.
이를 방지하기 위해 본 논문은 Shuffling BN을 도입하였다. 구체적으로, key encoder에 입력되는 mini-batch 샘플들의 순서를 GPU 간 분배 전에 무작위로 섞은 뒤 인코딩하고, 이후 원래 순서로 되돌린다. 반면 query encoder에는 원래 순서를 그대로 사용한다. 이렇게 하면 query와 key가 서로 다른 batch statistics에 의해 정규화되므로, BN을 통한 정보 누출 경로가 차단되고 모델이 실질적인 표현 학습에 집중할 수 있게 된다.
Experiments

End-to-End의 경우 학습은 MoCo와 비슷하게 잘 진행되지만, 애초에 배치 수를 많이 늘릴 수 없다는 문제점이 있어 스케일을 당초에 늘릴 수 없다. 반면 memory bank 방식을 사용하는 경우 이전의 representation을 바탕으로 학습하기 때문에 성능 향상에 한계를 보이는 모습을 볼 수 있다.
MoCo의 경우 모멘텀 계수를 0.99나 0.999같이 사실상 memory bank와 유사한 것처럼 보이게 만드는 업데이트를 사용함에도 불구하고 성능 향상이 나타나는 것을 볼 수 있다. 오히려 상대적으로 직관적이게 보이는 0.9 계수는 성능이 떨어지는 것을 확인할 수 있다.

이렇게 좋은 표현을 학습한 모델은 downstream task에서도 보통 더 좋은 성과를 보이기 마련이다. 한 번 확인해보자.

단순 linear classification task에서만 우수한 성능을 보인 것이 아니라, object detection에도 우수한 성능을 보인 것을 확인할 수 있다.

Object detection 성능은 representation 품질과 직결된다. Detection은 단순 분류보다 훨씬 많은 세밀한 공간적/시각적 정보를 요구하기 때문이다. MoCo가 이러한 성능 향상을 가져올 수 있는 이유는 단순히 contrastive loss를 기반으로 서로 다른 객체를 구분할 뿐만 아니라 queue 기반 큰 딕셔너리 데이터셋 구조로 더 많은 negative pair을 확보하여 학습을 더욱 풍부하게 할 수 있고 momentum encoder로 안정적인 학습을 오랫동안 할 수 있기 때문이다.
Conclusion
이번 논문은 컴퓨터 비전에서 좋은 표현 학습(representation learning) 이 무엇을 의미하는지에 대해 많은 시사점을 준다.
- 첫째, 한 번의 학습 단위에서 가능한 한 풍부한 데이터 샘플을 활용하는 것이 중요하다. 이를 위해 MoCo는 큐(queue) 기반의 사전(dictionary)을 사용하여 GPU 메모리 제약에 구애받지 않고도 대규모 negative sample을 효과적으로 확보하였다.
- 둘째, Self-supervised 학습에서는 모델이 안정적으로 무너지지 않고(avoid collapse) 표현을 학습하도록 하는 메커니즘이 필수적이다. MoCo는 momentum encoder를 도입하여 시점 간 표현의 일관성을 유지하고, Shuffling BN으로 batch normalization의 정보 누출 문제를 해결함으로써 안정적인 학습을 가능하게 했다.
이처럼 MoCo는 대규모·일관적·안정적 표현 학습을 동시에 달성할 수 있는 단순하면서도 강력한 방법론임을 보여주며, 이후 다양한 self-supervised representation learning 연구의 중요한 기반이 되었다.
'논문 리뷰 > CV' 카테고리의 다른 글
| Noisy Student 논문 리뷰 (1) | 2025.08.29 |
|---|---|
| I-JEPA 논문 리뷰 (0) | 2025.08.28 |
| U-Net 논문 리뷰 (0) | 2025.08.24 |
| ControlNet 논문 리뷰 (0) | 2025.08.23 |
| DINO 논문 리뷰 (2) | 2025.08.17 |