[Binance WebSocket]
↓
[Kafka Producer (Python)]
↓
[Kafka Broker on EC2]
↓
[Kafka Consumer (Python)]
위와 같은 플로우를 바탕으로 실시간 비트코인 데이터를 받아보자.
1. AWS EC2 실행 & Kafka 설치
우선 EC2를 실행해보자. 아래의 사진과 같이 인스턴스를 시작하자.

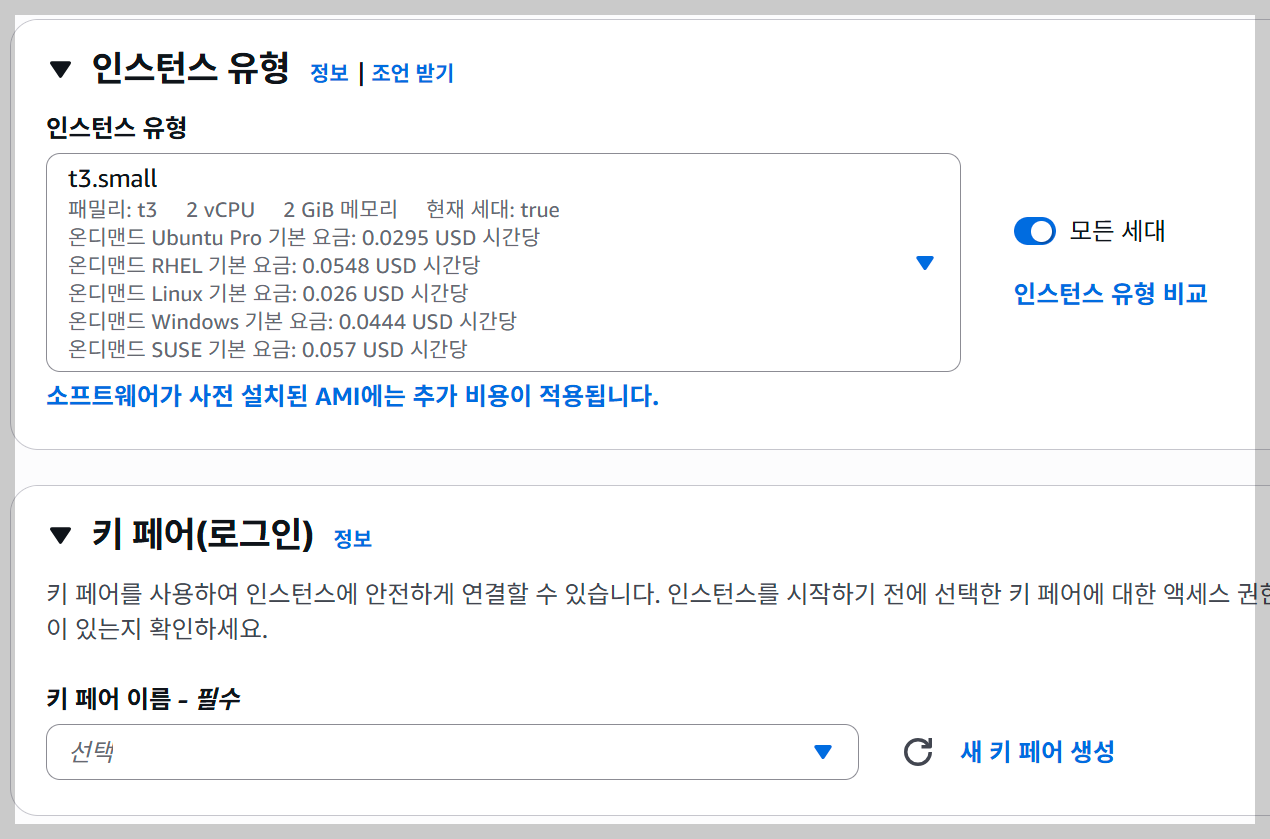
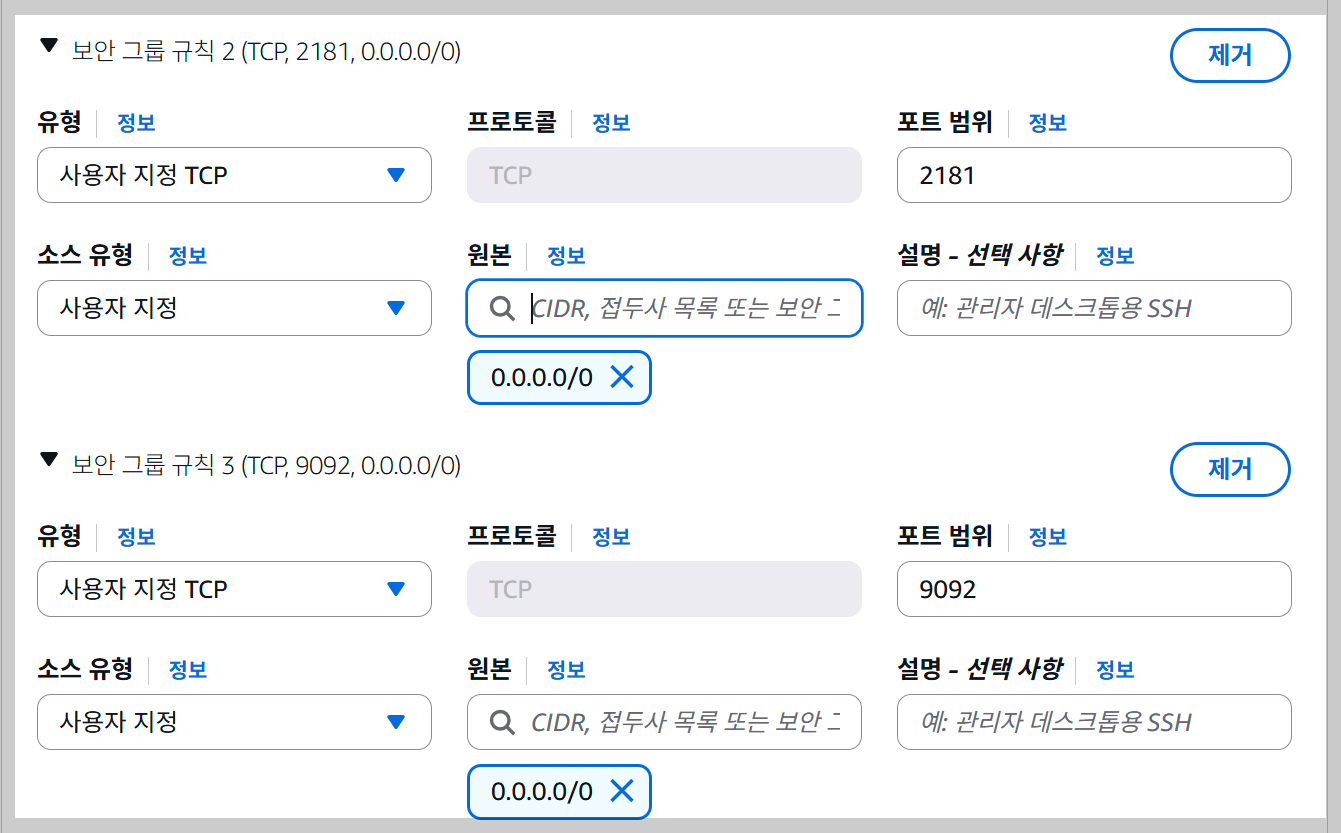

이제 터미널을 열고 EC2에 접속해주자.
ssh -i "PEM KEY DIRECTORY" ec2-user@<PUBLIC IP>
이제는 Kafka를 설치할 차례다. 아래의 코드를 실행해주자.
# Java JDK 설치
wget https://download.oracle.com/java/21/latest/jdk-21_linux-x64_bin.tar.gz
tar -xvf jdk-21_linux-x64_bin.tar.gz
`ls` 명령어를 통해서 jdk 버전을 확인해주고, `vim ~/.bashrc`를 실행하자. 실행하고 나서 아래의 수정사항을 반영하자.
# INSERT 눌러서 편집 모드, export PATH= 찾기
export PATH=/home/ec2-user/jdk-21.0.7/bin:$PATH
# ESC + :wq 입력하면 파일 저장 및 나가기
source ~/.bashrc # 변경사항 반영
java -version
# 아래는 명령어의 결과. 다음과 같이 뜨면 성공!
java version "21.0.7" 2025-04-15 LTS
Java(TM) SE Runtime Environment (build 21.0.7+8-LTS-245)
Java HotSpot(TM) 64-Bit Server VM (build 21.0.7+8-LTS-245, mixed mode, sharing)
이제 Kafka를 설치하도록 하자.
# 설치 후 압축 풀기
wget https://downloads.apache.org/kafka/3.8.0/kafka_2.12-3.8.0.tgz
tar -xzf kafka_2.12-3.8.0.tgz
# kafka 설치 폴더로 이동
cd kafka_2.12-3.8.0
# 1번째 터미널에 zookeeper 실행
bin/zookeeper-server-start.sh config/zookeeper.properties
# 2번째 터미널에 broker 실행
# 그치만 해야 할 것이 있다~
cd kafka_2.12-3.8.0
vim config/server.properties
advertised.listeners=PLAINTEXT://EC2-PUBLIC-IP:9092
:wq
# broker 실행
bin/kafka-server-start.sh config/server.properties
이렇게 broker, zookeeper을 실행하면 일단은 끝이다!
2. Binance Websocket을 이용한 pub sub 코드
# producer.py
import asyncio
import json
from kafka import KafkaProducer
import websockets
BINANCE_WS = "wss://stream.binance.com:9443/ws/btcusdt@trade"
producer = KafkaProducer(
bootstrap_servers=["<EC2_PUBLIC_IP>:9092"], # EC2 퍼블릭 IP
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
async def binance_to_kafka():
async with websockets.connect(BINANCE_WS) as websocket:
while True:
message = await websocket.recv()
data = json.loads(message)
producer.send("binance-trades", data)
print("Sent:", data)
asyncio.run(binance_to_kafka())from kafka import KafkaConsumer
import json
consumer = KafkaConsumer(
"binance-trades",
bootstrap_servers=["<EC2_PUBLIC_IP>:9092"],
value_deserializer=lambda x: json.loads(x.decode('utf-8')),
auto_offset_reset='latest',
enable_auto_commit=True
)
for message in consumer:
print("Received:", message.value)본인 EC2 퍼블릭 IP를 작성해주도록 하자.
이제 다음과 같은 절차를 거치면 된다.
# Kafka 토픽 생성
bin/kafka-topics.sh --create \
--topic binance-trades \
--bootstrap-server localhost:9092 \
--partitions 1 \
--replication-factor 1
# EC2에서 consumer.py 실행
python consumer.py
# 혹은 python3 consumer.py
# 다른 터미널 / 로컬에서 producer.py 실행
python producer.py
생각보다 어렵지 않은 코드다. MLOps를 할 때 가장 기본이 되는 데이터 스트리밍을 하는 법을 배웠고, 이 다음에는 데이터를 받아오면서 전처리와 S3에 담는 과정을 구현해보면 될 것 같다.
'MLOps > Kafka' 카테고리의 다른 글
| Kafka Streams, KStreams (0) | 2025.05.13 |
|---|---|
| Kafka 개념 이해하기 (0) | 2025.05.13 |