
Offline RL에서 One-step distillation을 이용한 policy optimization을 2026 Neurips에 제출하며 꽤 성공적으로 마친 후, Generative Modeling 분야에도 내 아이디어를 적용할 수 있지 않을까 하면서 최근 Distillation으로 one-step generative model을 만드는 방법들을 찾고 있다. 바로 논문의 핵심 아이디어를 확인해보자.
N-step Diffusion 모델을 바탕으로 1-step generative model을 만드는 방법으로, 본 논문에서는 Distribution Matching과 Pointwise Regression을 둔다.
Distribution Matching

여기서 $p_{\text{fake}}$는 one-step generator가 만들어내는 데이터에 대한 확률분포이고, $p_{\text{real}}$은 실제 data distribution을 의미한다. KL divergence를 낮춘다는 것은 두 확률분포가 일치하게 만든다는 것이니, 해당 수식은 one-step generator의 output이 실제 data에 가깝도록 하는 것으로 보면 되겠다. Gradient의 flow는 다음과 같다:

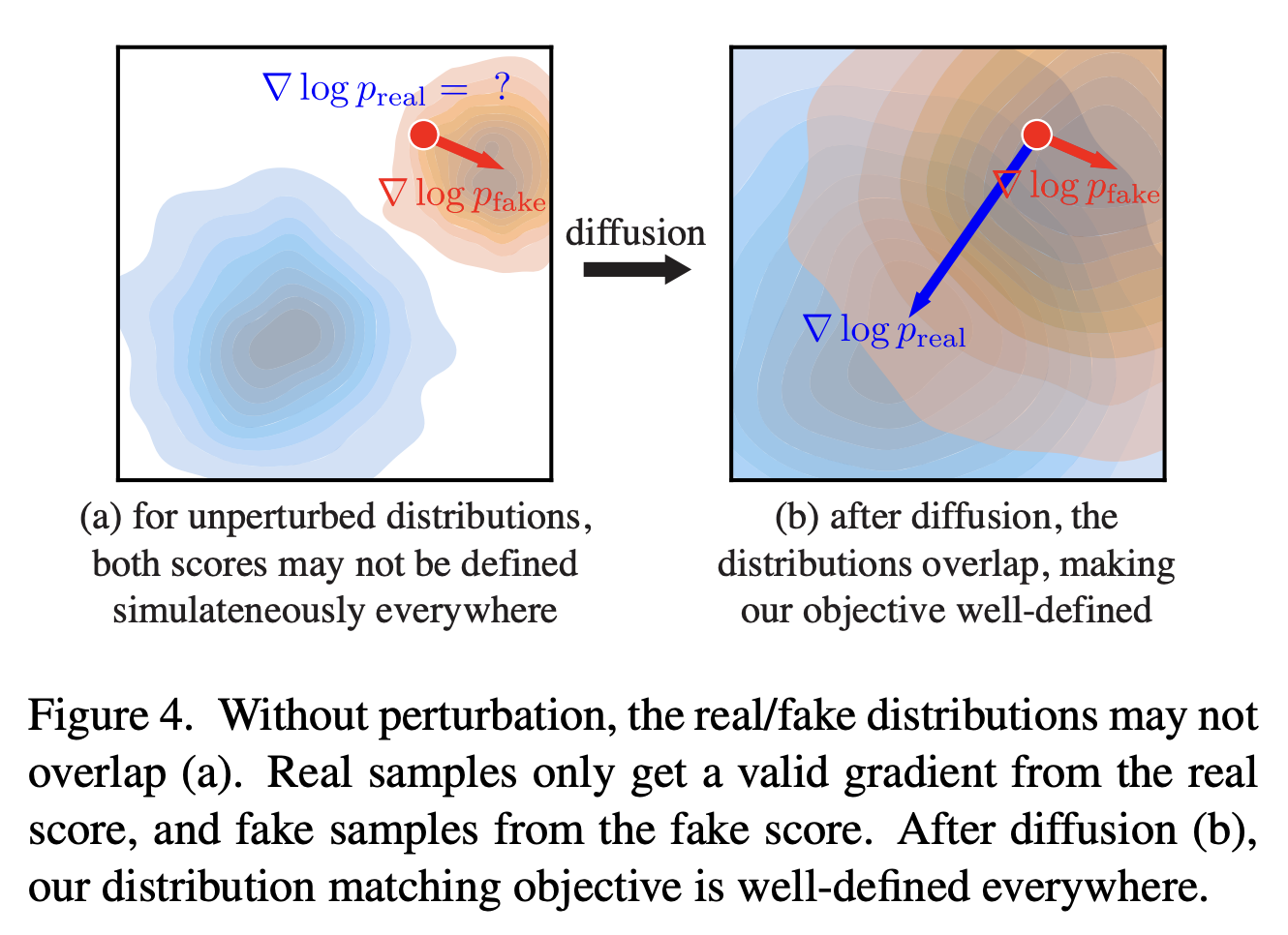
실제로는 우리가 실제 데이터에 관한 distribution은 얻을 수 없기에, $s_{\text{real}}(x)$는 pretrain된 N-step diffusion 모델을 이용한다. $s_{\text{fake}}$의 경우 one-step generator을 cloning하는 N-step diffusion 모델이다. 이상적인 경우라면 real/fake distribution의 score를 정확히 계산할 수 있다면 Eq. (2)의 gradient를 직접 구할 수 있다.
그러나 manifold assumption에 따라, one-step generator가 만들어내는 데이터 $x'$에 관한 score는 학습이 덜 된 경우, 실제 데이터를 바탕으로 pretrain이 되어 있는 N-step diffusion model이 $x'$에 대해 내는 확률값이 0에 가깝기 때문에, gradient 자체가 지나치게 불안정해질 수 있다. 따라서 본 논문은 시점 $t$에서의 score, 즉 Gaussian Noise가 추가된 상태(논문에서는 perturbation이라 한다)의 score 비교를 통해 해당 loss를 계산한다.
Github Repo에서 코드를 확인하고 대충 정리해봤으니 참고해보자:
z = sample_noise() # z ~ N(0, I)
x0 = G(z) # one-step generated sample
t = sample_timestep() # sample diffusion noise level
eps = sample_noise() # Gaussian perturbation
xt = alpha(t) * x0 + sigma(t) * eps # diffuse fake sample
eps_real = RealDM(xt, t, cond) # approx real score
eps_fake = FakeDM(xt, t, cond) # approx fake score
x0_real = pred_x0(xt, eps_real, t) # denoised prediction from real DM
x0_fake = pred_x0(xt, eps_fake, t) # denoised prediction from fake DM
grad = (x0 - x0_real) - (x0 - x0_fake) # approx s_real - s_fake
grad = normalize(grad) # stabilize scale
target = stopgrad(x0 - grad) # desired update direction
loss = mse(x0, target) # generator loss
update(G, loss) # update one-step generator
Pointwise Regression
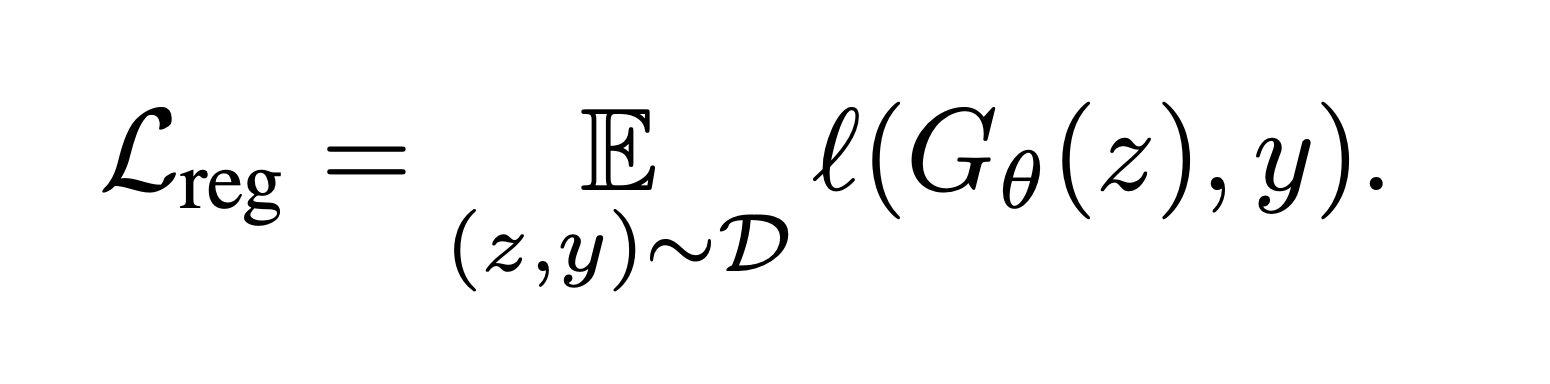
$y$는 pretrain된 N-step generative model이 생성한 데이터이고, 추가 학습을 하지 않기 때문에 caching을 할 수 있다. Loss 자체는 LPIPS MSE Loss를 사용하는데, Pixel 단위 Loss를 사용하는 것은 difference를 L2 ball 안에 가두겠다는 의미라서, 전체적인 색감만 맞추지 유의미한 학습이 불가능하게 된다. 따라서 sementic을 보존하고 있는 LPIPS loss를 사용하는 것이 합리적이다.
우선 Pointwise regression의 장점은, same input-same output 원칙을 두기 때문에 teacher의 diversity를 지킬 수 있다는 것이 첫 번째이고, one-step generator의 output을 따라해야 하는 fake N-step diffusion model에 가해지는 nonstationary problem을 완화시킬 수 있다는 점이 두 번째이다.
그러나 단점은, same input-same output 원칙이 지나치게 엄격하다는 것이다. 비유를 해보면 누군가에게 가르쳐주는 것(distillation)은 좋지만, 사고의 흐름까지 정확하게 따라하도록(pointwise regression) 하면 그 가르침 자체가 살짝 아쉬워질 것이다. DMD2 논문에서 해당 pointwise regression을 폐기한 것은 그러한 단점에서 비롯하기는 하나, 필자는 그래도 그 장점이 있는데 단점 하나 때문에 폐기해버리고 복잡한 아키텍처를 가져가야하나 싶다.
전체 pseudocode를 보면서 마무리하자.

따로 추가적으로 리뷰할 내용은 없어서, 여기서 마치도록 하겠다!
'논문 리뷰 > CV' 카테고리의 다른 글
| Swin Transfromer 논문 리뷰 (0) | 2025.10.03 |
|---|---|
| ResNeXt 논문 리뷰 (0) | 2025.09.26 |
| SwAV 논문 리뷰 (0) | 2025.09.26 |
| Barlow Twins 논문 리뷰 (3) | 2025.08.29 |
| Noisy Student 논문 리뷰 (1) | 2025.08.29 |